
サム・アルトマン3

CHAPTER12
オープンAI創業と「効果的利他主義」
●オープンAI、始動
・『オープンAIは2016年1月4日に始動したがその前の数週間は大混乱で、サツキヴァ―の参加も定かではなかったため、アルトマンとブロックマンはオフィススペースのことを考える余裕もなかった。
ディープマインド追撃をめざす一団は、とりあえずブロックマンのサンフランシスコの自宅マンションで仕事を始めた。ソファセットに寝そべったり、楕円形のダイニングテーブルに座ったり、アンドレイ・カーパシーの場合はブロックマンのベッドで仮眠することもあった。
ある時サツキヴァ―とジョン・シュルマンは、議論の途中で何かを書こうとして立ち上がり、ホワイトボードがないことに気づいてその場で固まった。ブロックマンは慌てて買いに走った。
まだ何をやるできかさえわからない状態だったから、ブロックマンは他の面で役に立とうとした。オフィス用品を注文したり、キッチンのコップを全部手洗いしたりした。「みんなほんとにたくさん水を飲むんだ」
ストライプでの最後の数年間は、キャリアについて思い悩み、特大の野望と、コードだけを書いていたいという欲求との葛藤を、長いブログ記事で吐露することもあった。ブロックマンはこの時代を、「自分の役割について考える」プロセスと呼んでいる。理由が何であれ、ブロックマンは悶々として過ごすことに耐えられなくなった。「僕が考えたいのはこんなことじゃない」と心の中でつぶやいた。「自分にとって重要な問題と、自分が最大限に貢献できる方法を考えたい」
自分の「エゴ」を離れ。「世のため」になることがしたかった。「コップ洗いでAGIに貢献しようとしているみたいだった。もっといいやり方はないのか?」
ブロックマンがリビングのソファとダイニングテーブルの間にホワイトボードを設置すると、チームは未知の霧に足を踏み入れた。』
●コンピュート
・オープンAIは少数の研究者をさらに少人数のチームに分けて関心のあることを追求させた。この頃、オープンAIはブロックマンの自宅から、セコイア所有のオフィスに移った。次にはマスクの会社「ニューラリンク」が入るパイオニアビルに移転した(賃料はマスクが負担した)。
・ブロックマンとサツキヴァ―は採用方針について話し合った。「数学羨望」を避け、AI研究者とソフトウェアエンジニアが対等な立場に立って、何に取り組むかを平等に決める会社を構想した。これはディープマインドとはかなり異なる方針となった。この時期、マスクもアルトマンもチームの様子を見にオフィスに来るのは週に1回程度だった。マスクはテスラとスペースXの他にも何社も切り回ししていて、すでに手一杯な状態だった。アルトマンもYCの舵取りが非常に忙しかったが、9月になるとYCでの債務の多くを移譲し、アルトマン自身は「YCグループ」という新組織の社長に納まった。(YCグループでの社長在籍期間は2014年2月~2019年3月)
●EA信望者を理事に迎い入れる
・EAとは効果的利他主義のことであるが、EA推進運動は、現実的な問題から、「生まれくる全人類を救う」という遠大な取り組みに向かい始め、核戦争や世界的パンデミック、AIの暴走など、可能性は低いがゼロではない重大な問題に注力するようになる。OP(オープン・フィロソフィー)もこの流れに乗った。OPはオープンAIに研究者として入社していたダリオ・アモディ、ポール・クリスティアーノがともにOPの技術顧問であることを公表した。
(なお、2021年1月にはダリオとポール他5名の計7名によって、OpenAIの競合となるAnthropicが設立されました)
・OPはマスクとアルトマンが初期のインタビューで語っていた「オープンAIの技術をオープンソース化する」計画の見直しを求めた。特にマスクは長年に渡って技術のオープンソース化を強力に擁護していて、テスラの特許もほとんど公開している。それでもOPが見直しに拘ったのは、「軽卒で無節操な人や悪人がこの技術を悪用すれば人類滅亡を招く恐れがあると考えたからである。このOPの動きに対し、オープンAI自身も利益追求や製品開発への懸念から、技術のオープンソース化について慎重な姿勢を示し始め、次のような見解を表明した。『当社は私的利益のために情報を非公開にするつもりはありません。しかし長期的には、安全性の懸念がある場合に技術を非公開にするための正式なプロセスを策定することを検討しています。』
CHAPTER13
前代未聞の「株を持たないCEO」
●マスク、「オープンAIの全面指揮権」を要求
・『マスクを含む共同創業者たちは、営利組織の転換を模索しながら、「誰が」その組織の指揮を執るかを長時間かけて話し合った。マスクはオープンAIの過半数の株式と、理事会の支配権、CEOの肩書き、そしてオープンAIの全面的な指揮権を要求した。
だが、サツキヴァ―とブロックマンは、マスクがオープンAIにあまり時間がかけられないのではないかと懸念した。CEOの選任は最終的に、フルタイムの共同創業者のうち、上級職であるブロックマンとサツキヴァ―に委ねられた。
2人は最初、マスクを選んだ。するとアルトマンがブロックマンに電話をかけ、マスクは一緒に仕事をするのが難しい人だと言って翻意させた。
次にブロックマンがサツキヴァ―を説得した。「僕は創設当初から、サムにCEOになってもらいたかった」とブロックマンは2023年にWSJに語っている。「会社にはサムの形をした『穴』が開いていて、僕らはあえてその穴を埋めずに、何年も待っていたんだ」
同年9月、ブロックマンとサツキヴァ―はマスクとアルトマンに、苦しい胸の内を打ち明けるメールを送った。
「あなたと一緒に仕事がしたいという気持ちはとても大きいし、それを叶えるためなら会社の株式や指揮権、僕らの解雇権など、何でも提供したいのはやまやまだ」と、ブロックマンとサツキヴァ―はマスクに宛てて書いている。だが懸念があった。「今の構造で行くと、いつかAGIの一極的で絶対的な支配を、あなたが手にすることになるかもしれない。最終的に実現したAGIを支配するつもりはない、とあなたは言うが、今回の交渉で、あなたが絶対的支配を極度に重視していることがはっきりした」加えて、オープンAIが「AGIの独裁を避けるため」に設立されたことを考えると、「あなたがその気になれば独裁者になれるような構造を持つことは愚策」に思われる、とつけ加えた。
2人はアルトマンについても懐疑的で、とくに彼の政治的野心をふまえて、同じメールに続けて書いた。「僕らはこのプロセスでの君の判断を完全に信用できずにいる。なぜなら君のコスト関数[意思決定の原理]が理解できないからだ」と、高校の数学コンテストの常連らしい言葉遣いでアルトマンに宛てて書いている。「君にとって、なぜCEOの肩書きがそんなに重要なのかがわからない。君が挙げた理由は変化しているが、何がその変化を駆り立てているのかがよくわからない。AGIは本当に君の第一の目標なんだろうか? それと君の政治的野心はどうつながっているんだ。君の思考プロセスはどう変わってきたのか?」。これらはブロックマンというよりはサツキヴァ―の思いだったが、程度の差こそあれ、2人とも同じ懸念を持っていた。』
PART4
岐路 2019-
CHAPTER14
「危険すぎて公開できない」AI?
●「21世紀最大の発見かもしれない」
・アモディと数人の研究者は、2019年GPT-3の開発を通して「スケーリング則」に関する論文を発表し、データと計算資源、ニューラルネットワークの規模を拡大すればするほど、大規模言語モデルの性能が「一貫して」向上することを示した。この論文は資金調達に奔走するCEOのアルトマンにとって、まさに天の恵みとなった。これは開発に投じられる資金が知識の限界を確実に押し広げてくれることを、科学的に示したものだったからである。
CHAPTER16
CEO解任事件、衝撃の真相
●解任
・『翌日、11月17日金曜日。アルトマンはF1レースを観戦するために、恋人のムルヘリンとラスベガスを訪れていた。
正午前。アルトマンは「グーグルミート」のアプリで、サツキヴァ―との会議へのリンクをクリックした。そして驚いた。画面にはサツキヴァ―だけでなく、ダンジェロとトナー、マッコーリーの顔までも現れたのだ。しかも不吉なことに、ブロックマンはいなかった。彼は数分前に理事を解任されていた。
サツキヴァ―は短い原稿を読み上げて、アルトマンに解任を告げたが、具体的な理由は示さなかった。アルトマンは愕然としたまま、つい、YCでスタートアップに助言していた頃の決まり文句を口走った。「何か手伝えることはあるかな?」
ニューヨーク・タイムズ紙の報道によると、理事たちは、移行期の舵取りをするムラティを支えてほしいと求め、アルトマンはそうすると約束した。
参加者のウィンドウが画面から一斉に消えたとたん、アルトマンはコンピュータから締め出された。』
●一瞬で広まるニュース
・『最初の瞬間は、ただもう信じられない、という思いしかなかった。悪い夢を見ているようだった。それから、怒りがこみ上げてきた。
数分後。オープンAIのウェブサイトに掲載された簡潔なブログ記事で、アルトマンがCEOを退任し、理事会を去るというニュースが発表された。そこにはたんに、アルトマンが「理事会の責任遂行に支障を来たした」とだけ書かれていた。
この知らせは、テック界の大物CEOたちが参加するメッセージアプリ「ワッツアップ」の私的なグループに、破壊級の衝撃をもたらした。』
●社員が「アルトマン支持」に回った理由
・『サンフランシスコ、発表前の数分前。ムラティはマイクロソフトCTOケヴィン・スコットに電話をかけ、理事会がこれからアルトマンを解任すると伝えた。
スコットは慌てて上司のサティア・ナデラを会議から引っ張り出して、ムラティと話させた。なぜ解任するのかというナデラの問いに、ムラティはわからないと答え、理事のダンジェロと話してほしいと促した。ダンジェロも、犯罪がらみではないと請け負う以外には、プレスリリースに書かれていた以上の情報を提供しなかった。
ムラティと社員たちとのやりとりも同様に進んだ。ムラティが理事会から渡された、危機管理コミュニケーションの要点をまとめた資料は、あのあいまいなブログ記事と大差なかった。
午後2時、ムラティとサツキヴァ―は全社会議を開催した。2人は45分もの間、「サムは何をやらかしたのか?」という主旨の質問を浴びせられ続けた。解任の理由はいつか社員に知らせられるのかという質問に、サツキヴァ―は「ノー」と答えた。
じつはアルトマン解任当時、社員の保有株式を、発行時の評価を大きく上回る900億ドル近くの企業評価額で売り出す交渉の最終段階にあったのだ。これが実現すれば、当時800人近くに増えていた社員の多くが大金持ちになれる。そして、この公開買付を主導するVC「スライヴ・キャピタル」の経営者ジョン・クシュナーは、トランプ大統領の娘婿ジャレッド・クシュナーの弟で、アルトマンのYCでの活動を長年にわたって支援してきた人物である。売り出しがアルトマンなしで行なわれるほど甘くないことを、社員は百も承知だった。
全社会議後、YCコンティニュイティ・ファンドの法務責任者を経て、オープンAIの出世街道を着実に上がり続け、CSO(最高戦略責任者)に就任したばかりのジェイソン・クォンが、サツキヴァ―の前に立ちはだかった。「これじゃ納得できない」と彼は言った。「みんなキレてるぞ」。クォンは幹部15人と理事全員のビデオ会議を申し入れ、サツキヴァ―はこれに応じた。
同日夜。理事たちがビデオ会議にログインすると、バーチャル会議室はむき出しのパニックに満ちていた。
クォンは礼儀正しく会議を始めようとして、「理事会は会社の利益のために行動したものと信じている」と言った。それでも、オープンAIには会社に生活を頼る800人近い社員がいて、そのほとんどがアルトマンを慕っていることを考えれば、理事会は「一貫して率直ではなかった」以上の説明をする義務がある、と迫った。
その上クォンの部署は、すでにニューヨーク南部地区の連邦地方裁判所から問い阿合わせを受けていた。この裁判所は、CEOの虚言に対する理事会の告発を、格好の調査対象と見なす傾向にある。
理事会はあいまいな言動によって、会社に対する規制当局の調査を招き、社員に苦痛を与えた。理事会はアルトマンを復帰させるしかない、なぜなら、会社の破壊を許すことは理事会の義務に反するからだ、とクォンは息巻いた。
すると理事のトナーはこう答えた。たとえアルトマンを追放して会社が破壊されることがあったとしても、「それが実際に会社の使命にかなう場合もありますよ」と。
これはまちがいではない。オープンAI憲章には、同社の「第1の信認義務は人類を守ることにある」と説明されている。理事会は社員にも、投資家にも、何ら義務を負わない。理事会は、憲章に掲げられた高邁な理想の有効性を試したまでのことだった。』
CHAPTER17
さらなる難局へ
●内省
・『オープンAIはより一般的な組織構造をめざして、経験豊富な新理事たちを迎えた。メディア会社パラマウント・グローバルの取締役を長年務めた、ソニー・エンターテインメント元社長のニコール・セリグマンや、ビル&メリンダ・ゲイツ財団の元CEOで、フェイスブックとファイザーの取締役を務めたスー・デズモンド=ヘルマン博士など。
また、解任の一端となった、アルトマンの社外活動への不信を避けるために、利益相反に関する新しい指針を導入した。
「疑念を持たれていたから、法的な助言のもとで標準的な手順を導入した。疑わしきは確かめよ、ということだ」と新理事のローレンス・サマーズは説明する。「サムはとても誠実にそれをやっている」
社外の法律事務所ウィルマ―ヘイルは、3万件以上の文書を精査し、数十人をインタビューした結果、旧理事会は権限の範囲内でアルトマンを解任したが、調査した限りにおいては、彼を解任しなければならないほどの問題は見当たらなかった、と結論づけた。
「ウィルマーヘイルの調査結果をふまえて、われわれは旧理事会とは異なる事業判断を下した。サムがCEOの座にとどまることの適切性に疑問を投げかけるようなものは、記録の中には何一つなかった」とサマーズは言う。
それでも、アルトマンはあのできごとの後で内省し、なぜ自分が理事会の信頼を失ってしまったのかを理解しようと努めた。
また、非営利の構造が維持不可能なほど不安定で、おそらく―営利企業だが、財務利益を追求しながら社会的・環境的利益を優先できるような法的枠組みを持つ―「パブリック・ベネフィット・コーポレーション(PBC)」のような組織形態に転換する必要があることを認識しつつも、そうした転換が一部の人の信頼をさらに損なうおそれがあることも理解していた。「僕らはつねに学習し、適応している。僕らのやっていることはつねに変化しているから、変化できる余地をたっぷり残しておくようにしているけれど、それを嫌がる人もいる。それでも、ときには余地を十分に残しておかなかったために、やろうとしていたこととはちがう選択肢を選ばざるをえなくこともある。僕らは非営利組織として始まり、次に利益に上限を設け、それがうまくいかなくなると、今度はPBCにする必要がある、なんて言っている。構造としてそれがうまく機能することを心から信じているけれど、そのやり方にカチンとくる人がいるのも当然だ」。』
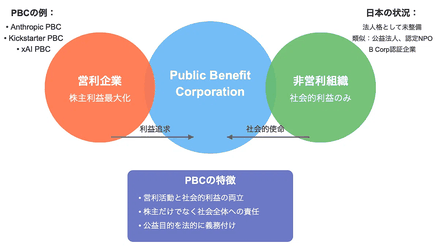
画像出展:「OpenAIが営利モデルを撤回しPBCに転換」
『PBCは営利企業の一種ですが、その法人憲章で「株主だけでなく社会全体の公益も追求する」ことが義務付けられています。通常の株式会社(営利企業)が経営陣に株主利益の最大化を求めるのに対し、PBCは取締役会が意思決定の際、特定の公益目的を考慮する法的責任を負う仕組みです。』
未来へ
●アルトマンの確信
・『リベラリズムが世界中で攻撃を受けるなかにあっても、アルトマンは合理性と科学、進歩を心の底から信奉し続ける。
イギリス物理学者デイヴィッド・ドイッチュが2011年に著した一般向けの科学書、『無限の始まり』を読んで以来、アルトマンはこの本を会う人会う人に勧めている。この中でドイッチュは、18世紀頃の啓蒙時代が、宇宙的な意義を持つ瞬間だったと主張する。それは、人類が真に知識を生み出すことを学び、その知識よって理論的には宇宙のすみずみまでを征服し変革できるようになった瞬間だというのだ。
「自然法則で禁じられていないことはすべて、適切な知識があれば実現できる」とドイッチュは説く。「死」も解決できる問題だ。人類が将来生み出すテクノロジーによって、宇宙のどんなに寒く暗い片隅にあっても、エネルギーと知識を活用することが可能になるはずだ。
アルトマンはサンフランシスコ・ロシアンヒル地区の自宅に、人類の進歩へ信奉を示すコーナーを設けている。彼の家を訪れる人が最初に目をするのは、3本の「手斧」で、うち1本は今までに発見された最古のものだ。手斧は、過去150万件のほとんどを通して、人間がものをつくり、生き物を殺し、料理をするために使っていた、唯一の道具である。
コーナーには、技術史のさまざまな段階の剣や、真空管、宇宙から持ち帰られたもの、コンコルドエンジンのブレード、アップルの初期のコンピュータ「Mac LCⅡ」のレプリカ、オープンAI製のロボットハンドなど、数十の品々が並ぶ。2024年9月のエッセイに、アルトマンは書いた。
「人類史を技術的発展という狭い視点からとらえれば、こうも言える。人類は数千年にわたる科学的発見と技術進歩の積み重ねを経て、砂を溶かし、不純物を少々加え、それを驚くべき精度で途方もなく微小な規模で精密に配置してコンピュータチップを製造し、そこに電気を通すことで、ますます高性能なAIを創造できるシステムを構築するにいたったのだと」それに続くのは、おそらくアルトマンにしか書けない一文だ。
「これは歴史全体における最も重大な事実になるかもしれない。人類は数千日以内(!)に超知能を手に入れ可能性がある。もっと時間がかかるかもしれないが、必ずそこに到達できると確信している」。』

感想
サム・アルトマンがスティーブ・ジョブズやマーク・ザッカーバーグと異なる印象をもつのは、2つあるように思いました。
1つは、Yコンビネータという投資家(エンジェル投資家)としての豊富なキャリアです。数々の若き才能、様々なアイデアと接する機会は、アルトマンのビジネスの幅と深さをつくり、そして、多くの人とのネットワークを通じて起業を支援するという才能を伸ばし、大きな能力を手に入れたと思います。
もう1つは、政治(民主主義)に対する畏敬の念ではないかと思います。既にご紹介していますが、アルトマンがブログに書いたとされる以下の言葉が、それを物語っているように思います。
「経済成長がなければ、民主主義は機能しない。なぜなら有権者はゼロサムの世界に生きているからだ」
これは、将来に渡って経済成長することが民主主義を守り、豊かな生活、平和な世界を築き上げられるというアルトマンの信念ではないかと思います。おそらく、すべての行動はここを起点にしていると思います。
大きなことを成し遂げた人に共通すると思うのは、いずれも、目標達成のための凄まじいエネルギーです。特に、“好奇心”、“行動力”、“信念”です。そして、その桁外れのエネルギーと揺るぎない自信が人を惹きつけるのだと思います。成功に導く大切な人との出会いも、そのエネルギーに因るものではないでしょうか。
“人との出会い”という言葉から、ウォーレン・バフェットの教えを思い出しました。素晴らしい出会いを自分のものにできるかどうかは人それぞれですが、おそらく、大事な人との出会いなくして、大きなことを成し遂げることはできないだろうと思います。
(画像は「ばっちゃまの米国株」の動画から拝借しました。これは学生に向けてのメッセージですが、“教師”を広い意味として捉えるならば、人生における教訓にもなると思います。)




サム・アルトマンにとってその出会いはループト時代のスティーブ・ジョブズ、Yコンビネータのポール・グレアム、ヒドラジン・キャピタルの共同設立者であるピーター・ティール、OpenAIのグレック・ブロックマン、そして、最大のライバルイーロン・マスクの5人ではないかと思います。
サム・アルトマン2

プロローグ
クーデター前夜
●「楽観主義者」サム・アルトマンとは何者か
・アルトマンはビジョナリーであり、エヴァンジェリスト(伝道者)であり、ディールメーカー(交渉人)であり、19世紀であればプロモーターと呼ばれるような人物である。
・Yコンビネータ時代に培った強みは、不可能に近いアイデアを可能だと思わせ、巨額の資金を調達して実際に実現してみせるその手腕である。
・シリコンバレーの「ゼロを加える」精神を、おそらく誰よりも地で行っているのがアルトマンである。これはYコンビネータの共同創業者のポール・グレアムの話である。
画像出展:「Yコンビネータ」
アルトマンが関わったYコンビネータは、単なるスタートアップ投資会社に留まらず「世界のイノベーションを加速するためのエコシステム」として機能し、起業家からテック業界、社会全体への広範なインパクトを残したとされています。
●「僕らが世界を導く声になれれば」
・『インタビューのなかで、アルトマンの利他的なうわべに隠された猛烈な競争心が垣間見えたのは、ほんの一瞬だけだった。』
●本書は「書かれたくない」
・アルトマンは数か月の交渉でも、「書かれたくない」という意向が明確であり、最終的な判断も「No」であった。理由は、「自分にはまだ早い」、「自分ばかりに注目が集まるのは困る」というものだったが、その後の電話での再三の交渉により、何とか執筆プロジェクトの合意を得た。『ただし僕がこの執筆プロジェクトをひどく嫌がっていたとはっきり書いてほしい。』とのことだった。
・劇的な解任劇の後、770人の社員のほとんどが、アルトマンが復帰しなければ退社してマイクロソフトに移籍する、と脅す歎願書に署名した。これはOpenAIの社員と投資家にとって、アルトマンがなくてはならないのは明らかであったからである。
●ビジョンを信じさせる力
・VC(ベンチャーキャピタル)は、スタートアップ企業の成功を投資家に信じ込ませるシャーマン(呪術師)のような能力こそが成否を決めるが、アルトマン以上にうまくやれる人はいない。
●アルトマンの投資先
・アルトマンの興味は一般的なVCとは異なり、未来に向けられている。例えば、「人間の寿命を10年延ばす」、「幹細胞を用いてパーキンソン病を治療する」、「超音速旅客機を復活させる」、「脳をコンピュータに接続するための移植デバイスを開発する」といったムーンショット事業(破壊的イノベーション創出事業)が目立つ。
●「サムは権力を手に入れるのがものすごくうまい」
・アルトマンを発掘したパトリック・チャンの話では、アルトマンは単に新しい技術を開発して世界に提供するだけでなく、常に「歴史上の偉人」になることを目指している。そして政治にも高い関心を持っているとのことである。
・Yコンビネータの共同創設者であるポール・グレアムは、「サムは権力を手に入れるのがものすごくうまいんだ」との話をしている。
●アルトマンとは何者か
・本書は「サム・アルトマンとは何者か」という問いに答えることを目的にしている。
・『本書を執筆するために、私はアルトマンの家族や友人、恩師、メンター、共同創業者、同僚、投資家、投資先企業に250件以上の取材を行ない、アルトマン自身にも何時間にもおよぶインタビューを行なった。そこから浮かび上がってきたのは、スピードを求めリスクを愛する凄腕のディールメーカーであり、宗教めいた確信を持って技術進歩を信望し、それでいて、ときには周りの人よりも速く動きすぎ、衝突を避けようとするあまり、かえって大きな衝突を招くこともある人物像である。』
・『アルトマンは倒されるたび、さらに強くなってよみがえってきた。恩師のグレアムも、2008年に彼について書いている。「人食い人種で一杯の島にパラシュートで落としたとしても、5年後に戻ったら王になっている」』
●アルトマン理解に欠かせない「家族」と「初期キャリア」
・『スタンフォード大学在学中に出会った仲間と、位置情報を利用したSNSを開発する最初のスタートアップ、「ループト」を立ち上げた。ループトは、彼がオープンAI以前に創業した唯一の会社であり、その物語には、のちの彼の活躍や苦難の片鱗がすでに現れている。たとえばセコイア・キャピタルなどの一流VCからやすやすと資金を調達し、経営難に陥ったスタートアップの若きCEOとして社員の反乱に翻弄された。
だがループトの最大の偉業はなんといっても、アルトマンをポール・グレアムとYコンビネータに引き合わせたことだろう。グレアムはアルトマンの中に、スタートアップの成功に必要なすべての素質を見た。ループトは2012年に売却されたが、アルトマンはその後もYコンビネータと親密な関係を持ち、Yコンビネータのスタートアップに助言しながら、ティールの支援を得た自身の投資ファンドを運営していた。その後グレアムは引退を決意し、後継にアルトマンを指名する。これによってアルトマンは、いきなりシリコンバレーの権力の中枢に躍り出たのである。
Yコンビネータは彼の指揮下で、養成するスタートアップの数を年間数十社から数百社に増やし、物理学や化学などのハードサイエンス分野に進出し、ムーンショット専門の部門を新設し、そしてこの部門を通して、「オープンAI」と呼ばれる非営利の研究所を生み出した。また、Yコンビネータの運営で多忙だったアルトマンに代わって、オープンAIの人材集めを担ったのは、彼の友人で、Yコンビネータの支援するオンライン決済会社「ストライプ」でCTOを務めた、グレッグ・ブロックマンだった。』
PART1 出発 1975-2005
CHAPTER2
「人を動かす」才能にめざめる
●「ゲイ・ストレート同盟」を立ち上げる
・『サムは高校の最終学年までに、性的マイノリティへの偏見や差別をなくすことをめざす学生・生徒組織「ゲイ・ストレート同盟」の支部を、「ほとんど意志の力で学内に立ち上げた」とロディンガーは言う。「サムは天性のリーダーだった。それも、ただ仕切るだけじゃなく、人を動かすことができた」
2000年代初めのセントルイスでは、性的指向はまだ「触れてはいけない」話題だった。ゲイのカップルは公の場所で一緒に踊ったり、手をつないで歩いたりしなかった。
この年ゲイ・ストレート同盟は、ゲイトとみなされている多くの生徒への理解を促すために、学内集会を開くことにした。しかし、キリスト教の生徒組織「KLIFE」の家族から、出席を遠慮させてほしいという要望が出され、学校はこれを受け入れた。
サムは激しい憤りを感じ、学校の「ズケズケ述べる」伝統に則って、翌日の朝会で声を上げることを決意する。
前の晩はよく眠れなかった。だが朝になり、壇上に立った時には、自信をみなぎらせていた。彼がゲイだということを、友人たちは知っていたかもしれないが、大半の生徒は知らなかった。サムはインパクトを最大限に高めるために、この場でカミングアウトするという、大胆きわまりない行動に出たのだ。』
※経営者とLGBTQ
Appleのティム・クック、PayPalマフィアのボスのピーター・ティール、そしてサム・アルトマン、この3人の傑出したテクノロジー界のトップリーダーはいずれもゲイとされています。ゲイの人がもつ何かの特性が強烈なリーダーを生む要因となっているのかという疑問から、AI(Perplexity)に質問してみました。
●大学進学
・志望校の3校(ハーバード、スタンフォード、ノースカロライナ(UNC)に合格。アルトマンは3人の兄妹のため、合格者の上位3%となり学費が全額免除になったUNCに行きたいと両親に提案したが、子ども時代からの夢だったスタンフォード大学を、両親は「夢を追いかけなさい」と送り出した。
CHAPTER3
「位置情報サービス」で起業する
●焦りと野心
・アルトマンを駆り立てていたのは、焦りと想像を絶するような野心だった。あるとき、「取り組みたい」を決めるのが先であると思い直し、紙切れに走り書きした。それは上から順に、「AI」、「核エネルギー」、「教育」だった。
●「サムには『現実歪曲空間』を生む力がある」
・アルトマンに会う人はその知性に魅了されるが、何よりも際立たせているのは「超自然的なまでの自信」である。
●人生を変えた、Yコンビネータでの面接
・Yコンビネータの4人の共同創業者とアルトマンの面接はわずか25分で終わった。ポール・グレアムは「ああ、これが19歳のときのビル・ゲイツの姿か、と思った」とのこと、一方、アルトマンも「あの時初めて、やった、一緒に過ごしたい人たちをとうとう見つけたぞ、と思った」
CHAPTER4
Yコンビネータ1期性になる
●Yコンビネータ、誕生
・グレアムはVCを内部から変革し、「われわれ自身のVCを始めようじゃないか」とリヴィングストンに提案した。それはVCとは異なるエンジェル投資であった。(PDFを参照ください)
PART2 成長 2005-2012
CHAPTER6
ループトで「敵を味方にする術」を学ぶ
●「できないことはない」というオーラを放つ
・『アルトマンの心は沈んだ。「ブーストと提携できれば、必然的に親会社のスプリントと提携することになる。そしてスプリントと提携すれば、ベライゾンとAT&Tも追随すると考えたんだ」
だが、わずかな可能性がまだ残っていた。レディエイトの競合は、ブーストが喉から手が出るほどほしがっていたものを提供できなかったのだ。それは、友人が5マイル圏内などにいることをユーザーに通知する機能だ。レディエイトのチームは、徹夜でそれを完成させた。
「あの日はたしか、朝4時から6時まで寝て、7時の便でブースト本社のあるオレンジ部に飛んだ」とアルトマンは言う。
アルトマンあアポなしでワイナリーのオフィスに押しかけ、10分だけ時間をくださいと言った。ワイナーが会議室に招き入れると、カーゴショーツ姿のアルトマンは、小柄な体には大きすぎる椅子の上にちょこんと座って、「インド風」にあぐらをかいた。そして口を開いたとたん、その場を完全に支配してしまった。
「体重50キロぐらいの、小柄な汗だくの若者の話を、いい歳をした大人がありがたがって聞き入っていた」とワイナーは言う。「サムは自信を発散させていた」
1時間ほど経った頃、ワイナーは会議室を出て、ブーストの製品担当副社長のオフィスに駆け込み、ブーストは契約相手を変更して、「たった今ふらりと現れた男」と提携する必要があると言った。レディエイトのチームは、ワイナーの求める機能を構築することによって、「機動性があり、能力がある」ことを証明した、と。
ワイナーはセコイアに電話でサムとレディエイトの人物と財務状況を照会してから、この若者と同社のワイヤレス契約を結ぶことを決めた。
アルトマンはこの時のやりとりから、基本的な教訓を学んだ。「何かをやり遂げるには、とにかくしつこくやることだ」
ワイナーは今もアルトマンとの邂逅をはっきり覚えている。「彼と会った人は1人残らず、あの才能をうらやんでいた。“できないことはない”というオーラを漂わせていたね。そして、非常に楽観的あった。決断力があって楽観的。 半信半疑のまま何かをやるということがなかった」』
●1%でも可能性があれば「成功する」と自分を確信させる
・『ジェイコブスティーンには、今も忘れられない光景がある。ループトに加わって1年ほど経った頃、顧問のワイデンに誘われて、アルトマンと3人でランチに行った。ワイデンはアルトマンに、ループトのほかにどんな構想を持っているのかと訊ねた。アルトマンは2つ挙げた。薄毛治療と核融合だ。ジェイコブスティーンはそれを聞いて、内心苦笑した。「核融合の何を知っているというんだ? コンビネータ科学科を3年で中退した、核融合の博士号も持たない19歳なのに」と。
その20年後、アルトマンはこの技術を実現しうる少数の核融合スタートアップのうちの1社を支援する。そしてジェイコブスティーンは気づいたという。アルトマンは、何かが成功する可能性をほんのわずかでも思い描くことができれば、それが「成功する」とまずは自分を確信させ、それから他人、とくに投資家を確信させることができるのだと。』
●アルトマンへの「不満」
・ジェイコブスティーンの退社後、ループトの幹部は大半が取締役会に対しアルトマンの解任を要求した。だが、取締役会は幹部たちの要求を却下した。
・『「僕は18、19歳の時、一緒に働きにくいことで有名だった」とアルトマンは、投資家のリード・ホフマンのポッドキャストで認めている。「会社の創業者として、週100時間働き、死ぬほど集中して生産性を上げること自体は、わるいことじゃない。でも、とくに会社が大きくなれば、自分が雇うほとんどの人に仕事以外の生活があることを理解しなくてはいけなかった」』
CHAPTER7
スティーブ・ジョブズにシゴかれる
●ジョブズの1行返信「弱いな」
・『モリッツは、これは難しいことだ、とはっきり言った。なにしろジョブズはSNSを毛嫌いしていたのだから。
「サムを売り込む必要があるな」とマカドゥーに言った。まず モリッツが根回しをし、続いてマカドゥーがアルトマンの経歴を説明するメールをジョブズに送った。「セコイアが投資した史上最年少の創業者で、スタンフォード中退者だという、スティーブに刺さる物語をね」とマカドゥーは言う。
リード大学を中退してアップルを創業したジョブズが、アルトマンの物語に惹かれるはずだという、マカドゥーの読みはズバリ当たり、ジョブズはループトのアプリを見てみるよと請け合った。
返事が来ないまま、数週間が過ぎた。しびれを切らしたマカドゥーは、ループトはどうでしょうかとさりげなくメールで訊ねた。
ジョブズの返事はたったひと言、「弱いな」だった。
マカドゥーはラップトップをつかんで廊下を走り、モリッツに返事を見せに行った。「どうしたものですかね?」。モリッツはヴァレンタインと同じく、ただ頭を振って「わからんよ」と言った。
アルトマンとハワードは、ジョブズの言葉にもひるまずに開発を進めた。今のバージョンがループトの可能性を引き出し切れていないことは、2人にもわかっていた。「弱い」は発奮を促す合い言葉になった。
ジョブズはループトにもの足りなさを感じたかもしれないが、アップルの製品とエンジニアリング部門の20代の若者たちはとりこになった。
2007年11月、アルトマンのもとに、iPhone開発チームから暗号化されたメールが届く。ループトがiPhone向けアプリを開発するために、SDKにどのような機能を必要としているのか聞きたいので、ご足労願う、と書かれていた。』
●ジョブズに直接売り込む
・『アップルの開発会議で登壇するという、垂涎の機会を手に入れるには、アルトマンがみずからジョブスに売り込む必要があった。アップルの開発者関係チームは、アルトマンとハワードと一緒に台本を練り、プレゼンの練習をさせた。
そしてとうとうアップルのクパチーノ本社でプレゼンを行なう日がやってきた。
アルトマンとハワードは、ジョブズが初代マッキントッシュ開発チームにひらめきを与えるために購入した、ベーゼルドルファー社のグラウンドピアノ―美を重視するアップルの姿勢の表れ―が置かれたロビーで待ち、講堂に案内された。
観客席の中央にジョブズが陣取り、数人のアシスタントが周りを囲んでいた。ジョブズはアルトマンとハワードが期待した黒いタートルネックではなく、Tシャツと短パンを着ていた。2人は緊張で口の中がカラカラだった。アルトマンがトークを担当し、ハワードがiPhone上でデモを行って、その映像を大きなスクリーンに映し出した。
プレゼンが終わると2人は前を見つめたままその場に立ち尽くした。
一瞬置いて、ジョブズは一言放った。「クールだ」
「弱い」から「クール」への格上げに2人は驚喜したが、それが何を意味するのかはまだ知らなかった。
まもなくアップル開発チームの代表から電話があり、講演者に選ばれたことを2人は知った。ただし、アップルが要求する修正を反映させ、リハーサルを支障なくこなすという、条件つきだ。
その後の1週間、2人はアップルのチームとリハーサルを特訓した。休憩時間にコードを手直しし、シヴォかサイに電話してサーバー側の修正をしてもらった。アップルの要請により、ループト社内では引き続きチームを少人数を除いて極秘とされた。「あれが行われるのを社員が知ったのは、本番のたった2日前だった」と、マーケティング責任者のリウは言う。』
●「ハイパフォーマーの活かし方」をアップルから学ぶ
・『アップル社内では、ループトは文句なしの大ヒットだった。ダウンロード数は急増していた。そして、アップルが数カ月後の海外でのiPhone発売に向けて準備を進めていた時、ジョブズは念を押した。ループトの位置情報技術は、iPhoneが利用可能になるすべての言語と国で動作するんだろうな、と。
だが当時の技術状況では、これは無理難題だった。ある時、ジョブズはループトとのミーティングにやってきて、ループトが彼の期待するほど幅広くサービスを提供できそうにないことを知ると、いきなりアルトマンを罵倒した。
その夜、マカドゥーとの大好きな寿司屋での夕食に現れたアルトマンは、まだ激しく動揺していた。「ジョブズと今までで一番厳しいミーティングをしてきた」とマカドゥーに言った。
「スティーブはいつも猛烈で、要求水準がとてつもなく高かった。だからこそ、私たちはあれほどすばらしい仕事をして、すばらしい製品を生み出すことができたのだがね」とフォーストールは語る。「スティーブが人にものを投げつけるのを、実際この目で何度も見たことがあるよ」
今になってみれば、ジョブズと過ごした数カ月がアルトマンに大きな影響を残したのは明らかだと、マカドゥーは言う。
「あの頃のアップルに関わったことは、サムに起業家として、またハイパフォーマーたちのリーダーとして、とてもよい意味で影響をおよぼした」。そして続けて言った。「誰かがプリマドンナ[才能はあるが傲慢で扱いにくい存在]だからといって、それだけの理由で辞めさせたりはしない。そんなのは取るに足りないことだ。ハイパフォーマーの半数は、何らかの面でプリマドンナなんだ。そういう連中をうまく活かすスキルを身につけないといけない。サムはその能力を大きく伸ばした。なにしろiPhone黎明期のアップルを内側から観察したんだからな』
PART3
飛躍 2012-2019
CHAPTER9
ピーター・ティールに投資を学ぶ
●ティールが見抜いた「アルトマンの長所と短所」
・ティールのアルトマン評は、「じつに賢い」、「とても固い信念を持ち、とても律儀で、とてもバランスが取れている」が「やや楽観的すぎるきらいがある」というものだった。また、アルトマンの強みは「知識」というより「人脈」にあると考えた。
・ティールは「テック界でミレニアム世代の代表を1人選ぶとしたら、アルトマンだ」と断言された。
・ティールの逆張り的な世界観は、人との協調を大切にするアルトマンのスタイルとは相いれない。アルトマンにとって最も称賛するティールのスタンスは、斬新なアイデアを生み出すために流れに逆らおうとするところである。「彼(ティール)は何ものにもとらわれない方法で世界について考える」とポッドキャストで述べた。
●ディープマインド
・デミス・ハサビスとシェーン・レッグ、そして起業家のムスタファ・スレイマンは「ディープマインド」を創業した。この社名はニューラルネットワーク(神経回路)を用いる機械学習の一種である、「ディープラーニング(深層学習)」にちなんでいる。たとえ人類の存在そのものを脅かす恐れがあったとしても、AGI(汎用人工知能)を開発するつもりだと、投資家に宣言した。
●「AGIは技術史上最大の発展になるかもしれない」
・『2013年12月、ハサビスはカリフォルニア州とネバダ州の境にある。タホ湖畔のハラーズ・カジノホテルで行われた機械学習会議に登壇し、ディープマインドの初めての大きなブレークスルーを発表した。それは、人間の指示を一切受けずに、アタリのビデオゲーム「ブレイクアウト(ブロック崩し)」のルールをみずから学習し、すばやく習得する。AIエージェントである。ディープマインドは深層ニューラルネットワークと強化学習を組み合わせることによって、これを実現した。
グーグルはこれに衝撃を受け、ひと月後に同社を6億5000万ドルで買収した。
このディープマインドの業績―AIが混沌とした世界を理解して、何らかの目的に向かって進めることを証明し、AGIに向かって大きな一歩を踏み出したこと―が持つ意味が広く理解されるようになったのは、1年以上後に同社がネイチャー誌にそれを発表してからのことである。
だがディープマインドの投資家であるティールは、その重要性をただちに見て取り、アルトマンとも議論した。
グーグルによるディープマインド買収のひと月後の2014年2月、アルトマンは個人のブログに「AI」と題した記事を投稿し、AIは十分な注意を払われていない、最も重要な技術的動向だと書いた。
「はっきり言うと、AIはおそらく機能しないだろう。これはどんな新しい技術についても言えることで、おおむね正しい発言だと言っていい。それでも、ほとんどの人がAIの可能性についてあまりにも悲観的すぎると思う」。そしてこう加えた。「AGIは機能するかもしれない。もしも機能すれば、それは技術史上最大の発展になるだろう」』
CHAPTER10
Yコンビネータ社長に抜擢
●Yコンビネータの社長に就任
・グレアムはアルトマンに社長のバトンを渡す理由として、「サムは恐ろしく有能でいて、根っから慈悲深いという、まれな人間だ。ほとんど理解されていないことだが、それらはアーリーステージ投資に欠かせない資質なのだ」とした。さらにブログには「サムは私の知る誰よりも賢く、私を含む誰よりもスタートアップを知り尽くしている」と書いた。
●ためらい
・アルトマンは社長になるべきかどうか迷った。投資家向きなのは理解していたが、本当は会社をやりたいという気持ちが強かったからである。最後はエンジェル投資家として創業者と働きたい気持ちが勝ってYCの社長をひき受けることにした。
●「経済成長」なくして民主主義なし
・アルトマンはYコンビネータの社長を引き受ける前年に「PGスタイル」という自身のブログで哲学的な個人エッセイを発表した。そのエッセイとはアルトマンの心の奥底に潜む最も強固な信念である。それは、「経済成長がなければ、民主主義は機能しない。なぜなら有権者はゼロサムの世界に生きているからだ」。人間に分かち合いを教えることはできなくても、経済成長という「裏技」によってパイそのものを拡大すれば、限られたパイを奪い合う必要もなくなる。というものである。
以下はそのブログですが、“Sam Altman”から拝借しました。
●成功のコツは「自分と似た仲間を集める」こと
・アルトマンは単刀直入で、雑談への耐性は欠けているがとてもオープンで相談しやすく、創業者の話を全神経を集中して聞いてくれるというのが創業者たちの印象だった。
CHAPTER11
「非営利のAI研究所」構想
●「AI倫理委員会」を設置したグーグルの真意
・政府の「AI倫理委員会」はアルトマンが、AI規制を政府に呼びかける公開書簡の作成を手伝ってほしいとイーロン・マスクに頼み、2人で草案を練って2015年7月に政府に提出した。
ディープマインドの「AI倫理委員会」に対する評価には厳しい意見があり、イーロン・マスクはピーター・ティールなどの友人を夕食に招いては、グーグルの力に対抗してAIを安全にする方法について話し合いました。
また、アルトマンはマスクに次のようなメッセージを送りました。「人類のAI開発を阻止することがはたして可能なのかどうかを、ずっと考えていた。答えは、ほぼ確実にノーだと思う。もし阻止できないなら、それを最初に実現するのはグーグル以外の何者かであるべきだ」。
●「人間の脳がAGIへの地図になる」
・「人間の脳がAGIへの地図になる」とはイリヤ・サツキヴァ―の信念である。サツキヴァ―はDNNResearch(ジェフリー・ヒントンの新会社)立ち上げに参画、Googleによる買収でGoogle Brainチームに移籍した。その後、2015年末にOpenAIのチーフサイエンティストとしてChatGPTや大規模言語モデル開発を主導した。OpenAI退職後、2024年6月にSafe Superintelligence Inc.(SSI)を設立。
・ニューラルネットワークは1980年代に飛躍したものの、その後は期待されたような成果は出ていなかった。その状況が一変したのはGPUと呼ばれる半導体チップである。GPUは膨大な並列計算を高速で実行することができるため、大規模なニューラルネットやデータセットを扱えるようになった。そして、それはAIの進歩を加速させた。
サム・アルトマン1
サム・アルトマンにはイーロン・マスクに通じる強烈なリーダーシップを感じる一方で、イーロン・マスクとは全く異なる個性も感じます。それは“陰”と“陽”の違いという印象があります。また、色々調べたところ“Disruptor(破壊的変革者)”という名称が見つかりました。さらに日本語の“先導者”に関し、英訳するとどんな単語があるのか調べてみると、文語的あるいは比喩的表現として“Pathfinder”という言葉もあるようです。この“Pathfinder”として相応しい人物は誰ですかとAI(Perplexity)に質問したところ、トーマス・エジソン(「パスファインダー・オブ・テクノロジー」)、マリー・キュリー(「パスファインダー・イン・サイエンス」、マルコム・X(「パスファインダー・フォー・ブラック・パワー」)等の名前が出てきました。
AIは従来のCPUベースのコンピューティングパワーから、CPUに加え、GPU、LPU、TPU、APU、NPUといった様々プロセッシングユニットを組み合わせた新たなコンピューティングパワーを必要とする、従来とは全く次元の異なるIT基盤上に構築されるものであり、ニューロ・コンピューティングを柱とする“第二の情報革命”あるいは“新しい計算原理”と言われています。

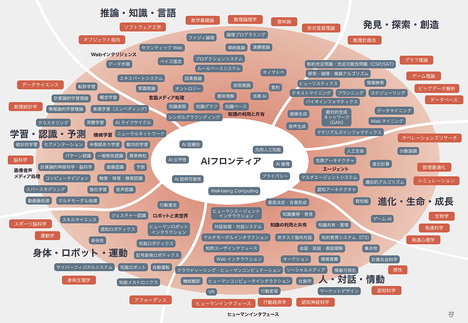
画像出展:「AIマップ」
『AI研究は拡大し、全体を俯瞰的に捉えることが難しくなっている。また、AI研究の成果を用いた多数のシステム(AIシステム)が実社会で活用され始めており、AIシステムとAI技術との対応も把握が難しくなっている。そこで、これから活躍するAI研究の初学者、およびAI活用を狙う異分野の研究者・実務者をターゲットとしたガイドとして、AIマップβ2.0を作成した。』
この情報革命をリードしているのは、DeepMindを抱えているGoogle、OpenAIをスピンアウトした元メンバーによって設立されたAnthropic、マーク・ザッカーバーグのMeta Platforms、ジェン・スン・ファンのNVIDIA、イーロン・マスクのxAI等(中国企業もあります)ですが、これらと比較しても、OpenAIを率いるサム・アルトマンは現在、最も注目する人物です。
『サム・アルトマン 生成AIで世界を手にした起業家の野望』は2025年10月発行と新しく、480ページの分厚い本でした。目次は非常に細かく分類されていたのですが、目次を見ればおおよその内容がつかめると思い、全て書き出しました。(最初のブログは目次だけのご紹介で終わっています。取り上げたのは“黒字”の部分です)

著者:キーチ・へイギー
訳者:櫻井裕子
発行:2025年10月
出版:ニューズピックス
プロローグ
クーデター前夜
●ピーター・ティールの警告
●「楽観主義者」サム・アルトマンとは何者か
●「AIによる人類存亡の危機」を懸念する人々
●シリコンバレーでは創業者が「神」である
●オープンAI本社にアルトマンを訪ねる
●「僕らが世界を導く声になれれば」
●本書は「書かれたくない」
●ビジョンを信じさせる力
●アルトマンの投資先
●「サムは権力を手に入れるのがものすごくうまい」
●アルトマンとは何者か
●アルトマン理解に欠かせない「家族」と「初期キャリア」
●史上最高のスタートアップ物語
●アルトマンを魅了する「ある思想」
PART1 出発 1975-2005
CHAPTER1
神童を生んだ「強烈すぎる両親」
●父、ジェリー・アルトマン
●住宅をめぐる人種差別
●サムも受け継いだ、ジェリーの「スタイル」
●徹底した楽観主義
●再婚
●「ディール・ストラクチャリング」の名手
●「神童」サム・アルトマン誕生
●再びセントルイスへ
CHAPTER2
「人を動かす」才能にめざめる
●受け入れられない「官民パートナーシップ」
●もがく両親
●兄妹たち
●サムとユダヤ教
●「サムにはもっとレベルの高い教育が必要だ」
●ジョン・バロウズ・スクール https://jbhs.burbankusd.org/
●テックを通じて他人と興味を分かち合う
●ゲイの自覚
●「人にどう思われようと気にしない」
●恋人
●「ゲイ・ストレート同盟」を立ち上げる
●大学進学
CHAPTER3
「位置情報サービス」で起業する
●焦りと野心
●「親しみやすいが、心ここにあらず」な学生
●位置情報と携帯電話を利用して何かやろう
●「サムには『現実歪曲空間』を生む力がある」
●ビジコンでの出会い
●スタートアップ界の教祖ポール・グレアムの口説き文句
●人生を変えた、Yコンビネータでの面接
CHAPTER4
Yコンビネータ1期性になる
●「絵画」からすべて学んだポール・グレアム
●グレアム、伝説のハーバード講演
●「VCのやつらは最低だ」
●VCの最大の問題は「報酬の支払われ方」
●Yコンビネータ、誕生
●「欠点のある創業者」でも成功できる
●創業者プログラムの「1期生」に
●「サムだけが『ビジネス』の視点から見ていた」
●全米3位の通信キャリアCTOを魅了する
●NEAにレディエイトをピッチする
●Yコンビネータ「1期生」たちの活躍
PART2 成長 2005-2012
CHAPTER5
「ジョブズやゲイツと並ぶ逸材だ」
●「最初のタームシートで妥協しないように」
●セコイアのVC、グレッグ・マカドゥー
●セコイア・キャピタル
●「何があってもサムには会うべきだわ」
●「ジョブズやゲイツと並ぶ逸材だ」
●大学中退命令
●「ただの『一時休学』だ」
●レディエイトとユーチューブへの巨額投資
●完璧なタイミングでの起業
●テック宇宙の中心、パロアルトにて
●送り込まれた「大人」たち
●ザッカーバーグにとってのサンドバーグ
CHAPTER6
ループトで「敵を味方にする術」を学ぶ
●「できないことはない」というオーラを放つ
●「ループト」に社名変更
●ループト、初の製品発表
●シンギュラー・ワイヤレスCEOを抱き込む
●プライバシー問題への対応でアルトマンが学んだ「手法」
●「規則」をダシに議員を味方につける
●ループトの成長と「最大の問題」
●1%でも可能性があれば「成功する」と自分を確信させる
●アルトマンへの「不満」
CHAPTER7
スティーブ・ジョブズにシゴかれる
●通信業界をひっくり返したスティーブ・ジョブズ
●脱獄アプリ
●ジョブズの1行返信「弱いな」
●ジョブズに直接売り込む
●アップル開発者会議でのプレゼン
●「ハイパフォーマーの活かし方」をアップルから学ぶ
●フェイスブックからの1.5億ドル買収提案を断る
CHAPTER8
社員の信用を一気に失う
●強敵フォースクエア登場
●「サムには1人で突っ走る傾向がある」
●アルトマンCEOへの不信と解任要求
●疑惑
●マカドゥーが見抜いていた「アルトマンの人脈力」
●セコイアの「一石二鳥」
●アルトマン、セコイアの「秘密の花形スカウト」に
●パトリック・コリソン
●ストライプ創業を支援する
●CEO業務から解放される
●ループト、売却
PART3
飛躍 2012-2019
CHAPTER9
ピーター・ティールに投資を学ぶ
●ピーター・ティール、伝説のスタンフォード講義
●ティールの真のねらい
●自分を見つめ直す時期
●核エネルギー
●ティールと「ヒドラジン・キャピタル」を立ち上げる
●ティールが見抜いた「アルトマンの長所と短所」
●「逆張り」をしないヒドラジン・キャピタル
●YCの「ゴールドラッシュ」
●アルトマンとティールの投資戦略
●シンギュラリティとエリーザー・ユドコウスキー
●「AIは大惨事をもたらす可能性がある」
●ティール、ユドコウスキーの後継者に
●汎用人工知能(AGI)
●ディープマインド
●「AGIは技術史上最大の発展になるかもしれない」
CHAPTER10
Yコンビネータ社長に抜擢
●Yコンビネータの社長に就任
●グレアムがアルトマンを後継者に据えた真の理由
●ためらい
●テックバブルの再来
●「経済成長」なくして民主主義なし
●新生YCのハードテック構想
●金融面での圧倒的な才能
●成功のコツは「自分と似た仲間を集める」こと
●VCを震え上がらせた、自社ファンドへの7億ドル調達
●苦境のレディット支援に乗り出す
●みずから難局に飛び込み信頼を築く
●『スーパーインテリジェンス』とニック・ポストロム
●「神の領域」に踏み込む野望
CHAPTER11
「非営利のAI研究所」構想
●世界初の「AI安全性会議」に参加したイーロン・マスク
●スカイプ創業者が後援する「生命の未来研究所(FLI)」
●マスクに接近する
●「AI倫理委員会」を設置したグーグルの真意
●高額報酬をともなう「安全性重視のAI研究所」構想
●グレッグ・ブロックマン
●ストライプ創業者のコリソン兄弟と出会う
●「人生にリハーサルはないよ」
●AI界の神童たちと出会う
●早熟の天才、イリヤ・サツキヴァー
●「人間の脳がAGIへの地図になる」
●「未来に来たみたいだった」
●メンバー候補を旅行に連れ出す
●YC内に「オープンAI研究所」誕生
●「非営利」にせざるを得なかったわけ
●サツキヴァ―を口説け
●「10億ドルを調達した、と発表しよう」
CHAPTER12
オープンAI創業と「効果的利他主義」
●オープンAI、始動
●王者ディープマインド製「アルファ碁」の衝撃
●コンピュート
●ユニバーサル・ベーシック・インカム(UBI)実験
●「実現しうる最高の未来都市」を建設する:「YCシティーズ」
●伝説のアラン・ケイに「人類進歩研究コミュニティ」を託す
●「サムは文明の建設者だ」
●HARC、痛恨の失敗
●やさしき誘惑
●「次の大統領選に出馬する」
●家族
●ティールへの不満が爆発する
●「トランプ勝利」に打ちのめされる
●州知事選出馬をひそかに模索する
●オバマとの協調
●アシロマ会議
●「AI軍拡競争」を避けよ
●シリコンバレーに広がる効果的利他主義(EA)運動
●EA信望者を理事に迎い入れる
CHAPTER13
前代未聞の「株を持たないCEO」
●オープンAI、eスポーツで勝利
●マイクロソフト
●つかの間の前進
●生成AI時代を切り拓いた「トランスフォーマー論文」
●「前代未聞の巨大モデル」の訓練に一点集中する
●生成的事前訓練済みトランスフォーマー(GPT)
●マスク、「オープンAIの全面指揮権」を要求
●「オープンAIはテスラの1部門になれ」
●マスク、去る
●実質的なCEOに
●ミラ・ムラティ
●父ジュリーの死
●サンバレー会議
●投資家に還元する利益に「上限」をつける
●YCチャイナ
●サウジアラビア
●「初心」を忘れたYコンビネータ
●前代未聞の「株を持たないCEO」誕生
●理事会の刷新と拡大
●激怒するリヴィングストンとグレアム
●アルトマンがYCに残した混乱
●「資金調達」の達人
PART4
岐路 2019-
CHAPTER14
「危険すぎて公開できない」AI?
●「危険すぎて公開できない」
●亀裂の始まり
●「21世紀最大の発見かもしれない」
●「フューショット学習」が可能な脅威の「GPT-3」
●失意のブロックマンとLLM
●数百社を回ってGPT-3を試してもらう
●アニー
●2020年のパンデミック下で
●アモディ、競合アンソロピックを創業
●確率的オウム
CHAPTER15
世界を揺るがせたチャットGPT公開
●GPT-3を使ったゲームの炎上
●「社会を再構築する」野望
●ワールドコイン
●寿命延長と若返り研究にのめり込む
●核融合スタートアップ「ヘリオン」
●変わる私生活
●アニー
●「DALL-E2」公開
●ブライアン・チェスキー
●アライメント
●ウェブGPT
●EA信望者ヘレン・トナー、理事に
●「会話型(チャット)インターフェースは思っていたよりすごいかも」
●チャットGPT、公開
●号砲
●追い詰められたグーグル
●グーグル打倒の好機をつかんだマイクロソフト
●全世界を驚愕させた「GPT-4」公開
●アルトマン、ホワイトハウスと公聴会に召喚
●恐怖の特効薬は「情報を与えること」
CHAPTER16
CEO解任事件、衝撃の真相
●新任理事の人選をめぐる権力闘争
●相次ぐ理事の辞任
●利益相反
●たび重なる「アルトマンの嘘」
●不可解な「スタートアップ・ファンド」
●アニー、サムを告発する
●サツキヴァ―の警告「君はもっとミラと話すべきだ」
●ムラティの訴え
●積み重なるサツキヴァ―の懸念
●「彼らは信頼できるのか?」
●アルトマンの怒り
●アルトマンの「手口」
●スラックのスクリーンショット
●スパイ
●「サティアには伝えたの?」
●解任
●一瞬で広まるニュース
●社員が「アルトマン支持」に回った理由
●逆に追い詰められる軽率な理事会
●反撃
●「サツキヴァ―のクーデター」なのか
●アルトマン邸にて
●アルトマン、オフィスに現れる
●決着
CHAPTER17
さらなる難局へ
●「この時代に結婚できたことを幸運に思う」
●政治への野望
●空約束
●7兆ドル
●EA勢力によるAI規制の波
●圧倒的な資金力で政府に食い込むEA勢力
●「今は誰もが型破りになることを恐れている」
●内省
●マスク、オープンAIを提訴
●サツキヴァ―、去る
●安全性研究者たちの流出
●口止め
●her
●サツキヴァ―の危惧
●「セーフ・スーパーインテリジェンス(SSI)」設立
●「テック業界は規制されないことに慣れきっている」
●「人食い人種の王」
エピローグ
未来へ
●家族
●「AIのゴッドファーザー」の警告
●「信用できない人物が世界最強のAIを支配すべきではない」
●未来
●アルトマンの確信
RapidusとTSMC
偶然、NHKスペシャルでラピダスを知りました。
画像出展:「“1兆円”を託された男 ~半導体ニッポン 復活に挑む~」
『2025年7月、日本の新興メーカー・ラピダスが最先端半導体の試作に成功した。革新的なナノ構造で高性能を実現。AI社会の要になると期待されている。投入された税金は1兆円超。その量産化には日本の命運がかかる。プロジェクトを率いるのは社長・小池淳義。』
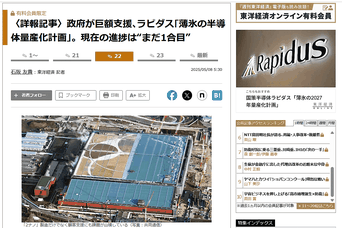
画像出展:「政府が巨額支援、ラピダス“薄氷の半導体量産化計画”。現在の進捗は“まだ1合目”
『この前日、最先端「2ナノメートル」世代の半導体の国産化を目指すラピダスに対し、経済産業省は最大で8025億円の追加支援を決定した。これで、2022年からの累計支援額は1兆7225億円に上る。』
番組は小池社長の孤軍奮闘ぶりが印象的でした。「平気かな~?」というのが直観です。なぜなら、日本は1970年~1980年代、世界シェア5割を超えていたにも関わらず、2010年には1割を切ってしまったという過去があるからです。
思うにこれはチャンレンジすることを軽視し、現状維持に胡坐をかいてしまったということだと思います。その守りの空気が入れ替わって、国と民間が高い志を共有できなければこの戦いは非常に厳しいものになるように思います。
以下のように日本では5年10兆円という話が出ていますが、
“半導体・AI分野で2030年度に向け10兆円以上の大規模公的支援”
TSMCは米国だけで1000億ドル(約15兆円)を投資するということが決定的になっています。
“TSMC、米国への1,000億ドル追加投資は台湾への投資に影響せずと説明”
この資金調達の規模とフットワーク(実行力)の良さをみても、やはり厳しい戦いだと思います。
このようなことを真剣に考えても意味のないことなのですが、とりあえずTSMCの凄さが何なのかを知りたいと思い本を買いましした。

著者:王 百録
解説:鈴木一人
訳者:沢井メグ
発行:2023年10月
出版:(株)日経BP

序文
第1章 護国神山、TSMC
1.なぜTSMCは「台湾の守り神」と呼ばれるのか
2.業界トップランナーへの道
3.TSMC現象
4.護国神山たち
第2章 TSMC誕生の奇跡
1.すべては李国鼎から始まった
2.モリスによって偶然誕生したTSMC
3.台湾最大の投資
4.ファウンドリーモデルの考案者は誰か
第3章 モリス・チャンスとは何者か
1.MITとシルバニア
2.テキサス・インスツルメンツでの栄光の25年
3.実践から学ぶ―モリス・チャンの政治の知恵
第4章 TSMCの七つの競争優位性
1.制度は米国式、リーダーシップは台湾式
2.競合他社を圧倒する数の技術者チーム
3.一流かつ現実的な企業文化
4.生産技術と賃金が2大ハードル
5.21世紀型AIマーケティング
6.「全方位型」「一歩先行く」顧客サービスモデル
7.1300社からなる巨大サプライチェーン
第5章 TSMCの技術開発秘話
1.創業の壁―6インチファブからのスタート
2.TSMCとUMC
3.TSMC対インテル、そしてサムスンとの競争
4.TSMCとエヌビディア
5.ハイテク界の巨匠が語るモリス・チャンとTSMC
第6章 今後10年を展望する
1.TSMCの海外工場
2.グローバルにESGを推進する
3.今後10年で起こり得る危機
謝辞
解説
第1章 護国神山、TSMC
1.なぜTSMCは「台湾の守り神」と呼ばれるのか
●三流製品を請け負う「ローエンド・ファウンドリー」のイメージだったTSMCが脱皮したのは1998年にNVIDIAから高性能グラフィックチップの製造を受注したことによる。
●ファウンドリーは「受託製造」と言われていたため、単純な組立工程にすぎないと考えられていた。しかし、実際は数百から数千の工程があり、それぞれの工程に少しの誤差も許されない非常に厳しいものである。それゆえに、物理学、電気工学、化学、機械学の専門家で、研究開発や製造に10年以上の経験がある一流の頭脳が求められる。
●TSMCは創業3年目から30年にわたって高成長を続け、収益を拡大し世界の半導体製造者のトップになった。
●1960年代から数万人の台湾人が米国に渡って半導体産業で働き、1980~2010年に台湾に帰国し、半導体産業で成功を収めた。
2.業界トップランナーへの道
●TSMCに対抗するため、IBM、インテル、サムスン電子などがTSMCに対抗するため多額の投資を行なったが、IBMは3年で撤退。サムスン電子はiPhoneに関する競争に勝てず、インテルは7nmプロセスの歩留まり率を3年かかったが目標をクリアできず、その間、TSMCへ生産委託を決断したAMDにシェアを20%程、差をつけられた。
●2009年にCEOに復帰したモリスは様々な反対を退け、毎年100億~200億米ドルの投資を続け、生産能力において競合との差は更に広がった。
●創業以来、TSMCは人材と研究開発に莫大な投資を続けた。半導体製造に関する10万件以上の特許技術を開発した。
●モリスは市場の動向を見極める鋭い感覚を持っている。それは創業期、その後20年以上続いた急成長期、そして巨大企業になった今も、技術研鑽を決して怠らなかったためである。これにより経営トップが最新技術に対する理解不足による誤った意思決定を下すということがなかった。
3.TSMC現象
●TSMCはエリート人材の宝庫である。新卒は台湾の名門5大学の電機、電子、機械専攻の学生が大挙して押し寄せる。マネージャー、副所長、所長は世界から広く人材を募集しており、特に米国、日本、欧州に加え、インド、ロシア、中国、韓国、東欧諸国にも対象を広げている。そのため、上司が外国人、同僚の国籍がみんな違うというのはもはや日常の光景である。
第2章 TSMC誕生の奇跡
1.すべては李国鼎から始まった
●『実際、これは予期せぬ成功の物語である。
1986年7月、モリスが工研院院長に就任した当日、前任者の方賢斉からA4サイズの1枚の紙を手渡された。それは緊急事案リストで、そのトップに書かれていたのが、米国から帰国した新竹サイエンスパークで創業した半導体3社のため、ウエハー製造工場の建設を急ぐことだった。
その3社の創設者はIBM、HP、インテルなど大企業出身の華僑たちで、いずれも半導体分野に精通していた。彼らは政府の科学技術担当だった李国鼎の呼びかけに応じ、高待遇だった米国での大企業を辞して台湾に帰国し、新しくつくられた新竹サイエンスパークで起業した。だが、当時のサイエンスパークは決して恵まれた環境ではなかった。研究開発施設やオフィスなどハード面や政府による優遇措置はあったものの、人材、生産工場、ベンチャーキャピタルなどハイテク産業に必要な条件が整っていなかった。もし政府が生産工場などの問題を解決できなければ、プロジェクトは水に流れるところだった。工場を設立できなければチップは生産できず、新竹サイエンスパークの第一陣となった半導体企業は解散せざるを得ない。そうした情報が海外にいる華僑の耳に入れば、優秀な人材が現地の生活を捨てて台湾のために帰国することなど二度とないだろう。そうなれば台湾のハイテク産業の発展のためにつくられた新竹サイエンスパークは、せいぜい昔ながらの工業エリアとして利用されるのが関の山だ。もし、この時、計画が頓挫していたら、1年に5兆~6兆台湾ドルの生産額を生む現在の新竹、竹南、台中、台南、路竹のサイエンスパークの繁栄はなかった。
李国鼎と孫運濬が長年心血を注いできたプロジェクトは幻のごとく消えてしまいそうだった。2人は政府の経済・科学技術のトップだ。中でも財政部長(財務相に相当)と経済部長(経産相に相当)を歴任し、かつて蒋介石から「行政院応用技術開発グループ」の責任に任命されたこともある李国鼎は、焦りを感じていた。新竹サイエンスパークの半導体企業3社の問題を解決するには、ウエハー工場の創設しかなかった。これが工研院院長に就任した最初の月に、モリスにつきつけられた課題だった。
前任者の方賢斉はモリスに緊急事案リストを渡した際、こう伝えた。「KT(李国鼎の英語での愛称)は特にこの件を急いでいる。数日以内に話があるだろう」。方賢斉の言葉通り、数日後、モリスはKTから電話を受けた。半導体3社の創業問題の解決策を議論するため、行政院で開かれるKT主催の隔週の会議に参加せよ、というものだった。当初、3社がそれぞれウエハー工場をつくり、それを支援する案が出されていたが、政府にはそこまでの予算はない。そこで、ウエハー製造能力を有する企業を設立し、そこに3社が生産を委託するというモリスの提案を受け入れることになった。
当時、モリスは私に、この3社は当初非ロジックICをつくろうとしていたが、モリス自身は「特定用途向けロジックIC(ASIC)の生産に取り組むつもりだ」と述べていた。政府の望みは3社のためできるだけ早くウエハー工場をつくることであり、技術や製造の方向性はモリスに一任した。
ここで注目しておきたいのは、TSMCが1987年に創業した当初、技術の源泉は工研院電子研究所の6インチウエハー・ファブであり、その後、フィリップスからの技術供与もあったことだ。当時のウエハー製造技術の主流はUMCによる3μm~5μmプロセスで、民生用IC分野が主力製品だった。一方、TSMCが持つ1.5μmプロセス・月産2万枚の生産能力はややオーバースペックだった。当時、国内のIC設計企業は30社ほどで、そこから見込める発注は月に数百枚程度しかない。TSMCの製造能力を生かすには、海外市場の開拓が急務だった。TSMCの設立当初、経営陣の何人かがモリスがよく知る米国の半導体業界の外国人だった理由はここにあった。
1988年、インテルCEOのアンドリュー・グローブが訪台した際、モリスは彼を新竹サイエンスパークの工場に招待した。PC用マイクロプロセッサーチップの世界的リーダーであるインテルから注文を勝ち取りたいと考えていたからだ。天は努力する人を裏切らない。1年後、インテルが派遣した専門家チームによる200項目にわたる監査をパスし、ついにインテルからの受注に漕ぎ着けた。おかげで工場のラインはフル稼働となり、TSMCの歴史に新たな1ページが刻み込まれた。
偶然が積み重なって植えられた苗木が、のちに巨木となり花を咲かせた。その大樹は、台湾という技術の島を守っているのである。』
3.台湾最大の投資
●TSMCの投資額が巨額だったため、政府の出資上限は49%だった。資本金は55億台湾ドル(約272億円)の内訳は政府が27億台湾ドル(出資比率48.3%)、フィリップスの出資比率は27.5%だった(フィリップスのオプション条項の持株比率は当初の50%以上は、交渉による最大40%となった)。政府による48.3%出資は、当時の行政院長が李国鼎を全面的に支持し、与党国民党の金庫番こと中央銀行の兪国華の大きな協力があって実現したものだった。さらに、政府の財務、経済関係の閣僚や幹部はすべてKT[李国鼎]の息がかかった者であったことが大きく、彼らはこれが台湾にとって非常に重要な政策投資であることを認識し、支援するために最善を尽くした。この結果、政府および党からの出資分は特に大きな問題はなかった。
●民間からの出資は大きな課題として立ちはだかったが、フィリップスの27.5%に加え、兪国華と李国鼎からの強い働きかけによって、民間企業と党営企業から合計24.2%の出資金を集めることができ、TSMCの設立の道が開けた。
●モリスは台湾政府が半導体産業の振興で大きな役割を果たしていることを常に称賛している。それは、工研院の設立による半導体技術の開発の指導から人材育成、サイエンスパークにおける土地、工場、働きやすい労働環境の提供、そして税制措置まで、これらの政策が台湾半導体産業を成功に導いたと述べている。
第3章 モリス・チャンスとは何者か
2.テキサス・インスツルメンツでの栄光の25年
●米国で様々な経験を積んだモリスは、台湾に帰国するや否や李国鼎からTMSCという新プロジェクトを任せられると、すぐに力を発揮した。これが台湾の繫栄と世界トップクラスの半導体開発の成功を導く鍵となった。1985年、もし、李国鼎がIBMやインテルという米国企業から3人組を台湾に呼び戻し、新竹サイエンスパークで事業を立ち上げるように仕向けなければ、そして、彼らが政府に半導体製造工場の建設を熱望しなければ、現在の台湾における半導体産業の成功はなかった。さらに、1970年から1980年代にかけて台湾の一流大学が数千人の理工系学生を米国の大学院に送り込み、その後、彼らが修士号や博士号を取得し、現地で半導体関連の仕事に従事したことも、1990年以降のTSMCの急成長に欠かせない要素だった。
第4章 TSMCの七つの競争優位性
2.競合他社を圧倒する数の技術者チーム
●TSMCの技術チームは、キャリア20年以上のベテラン幹部とキャリア5~10年の敏腕技術からなる約2万人の規模である。これらの技術者は世界有数のテクノロジー企業から幅広い領域のプロジェクトを受注したほか、先進国の軍事・航空・宇宙産業などから超高精度チップの製造を請け負うために訓練されてきた。彼らは、生産・研究開発部のチーフエンジニア、マネージャー、シニアマネージャー、部長、副所長と昇進して中堅幹部となり、多種多様な問題解決能力を身につけた。この数千人規模の熟練幹部たちがキャリア10年以上のベテラン技術者2万人を率いており、この技術部門の人材こそがTSMCの最大の武器となっている。
4.一流かつ現実的な企業文化
●TSMCの4つのコアバリューを掲げている。
①常に誠実であること(Integrity)
②コミットメント(Commitment)
③イノベーション(Innovation)
④顧客の信頼(Custmer Trust)
この4つのコアバリューを実践するには、あらゆる角度から議論し、どんなことをすべきなのか具体的に定めなければならない。さらにその方法を継続的に運用し、修正と試行を繰り返すことで企業文化として定着しやがて制度となる。
●制度導入の初期段階では、その制度をトップが尊重し、堅持することが重要である。モリスはTSMCの創業前、米国の三つの企業で経験を積んだ。特にTIでの25年間では、20人程の技術者チームのリーダーから、3000人を率いる副社長まで務めた。彼は半導体企業の競争力が、コーポレートガバナンスや企業文化の質によって決まることを目の当たりにしてきた。そのため、TSMCの経営が安定し、2000年前後に成長期に入ると、モリスはコーポレートガバナンスと企業文化に多くの時間を費やし、進化させていった。
①常に誠実であること(Integrity)
◇“私たちは、真実のみを語る”
◇“私たちは、なし得ないことを誇張しない”
◇“私たちは、お客様に対し、安易にコミットしない。けれども、一度コミットしたことには、どんな犠牲を払ってでも最後までやり遂げる”
◇“私たちは、法の範囲内で同業他社と最大限競争し、他社を誹謗中傷することなく、他社の知的財産権を尊重する”
◇“私たちは、客観的で公正、公平な方法でサプライヤーを選定し、協力する”
◇“私たちは、従業員の不正行為や、派閥などによる「社内政治」を許さない。私たちが人材を採用する際に最も重視する基準は人柄と才能であり、縁故による採用しない”
●「常に誠実であること」について、これほど具体的な踏み込んで説明している例は、国内外の大企業を見ても珍しい。特にモリスが避けたかったことは、縁故や派閥による不公平な評価である。優秀な人材が不合理な理由で昇進できず会社を去ってしまうという事態をなくしたいと考えていた。
②コミットメント
◇“コミットメントとは双方向のものだ”
◇“従業員は全力で会社に忠誠を尽くし、「会社の成功は、自分の成功」の精神で、勤勉かつ誠実に仕事に取り組む”
◇“会社は従業員を最も大切な資産と見なし、有意義でやりがいがある仕事、安全な職場環境、十分な報酬と充実した福利厚生を提供する。また、仕事以外の家族や友人関係、趣味を広げ、豊かな人生を送れるようサポートする”
◇“私たちは、株主、顧客、サプライヤー、地域社会、その他のステークホルダーに対するコミットメントを守り、各関係者の利益のバランスをとるよう努める“
◇“株主が平均以上の投資リターンを得られるようにする。顧客やサプライヤーと全面的に協力して、長期的なウィン・ウィンの関係を築く。良き企業市民として、地域社会をよりよくするための努力を惜しまない”
●このような理念は、CEOや会長がリーダーシップを取り、功績のすべてのものになる米国の大企業とは大きく異なる。
[誠実・正直であり続けること]
-TSMCが「人による支配」ではなく「制度によるガバナンス」を成功させたことが、他の99%の台湾企業と完全に異なる点である。
-「制度によるガバナンス」を実現できた理由は、数十年にわたる観察と分析から具体的かつ明確に判明している。台湾企業では幹部の親族や同郷、出身大学などの関係が重視され、派閥やグループが形成されやすい。どんな企業にも程度の差こそあれ社内政治は存在し、根絶は非常に難しい。そうした組織風土は、不公平な人事や報酬を生み出しやすい。この不合理は企業のリソースを浪費するだけでなく、経営目標が不明確になり、競争力の低下を招く。たとえ企業がある強みを生かして成長し、好業績を上げられるようになっても、意欲の高い人材が排除され、内部対立が発生すれば、従業員は大きな不公平感と不満を抱える。これは放置できない問題である。
[「ファウンドリー事業」に徹する]
-これはモリスが長年、従業員に再三伝えている言葉である。
-『我々の事業は、専業のファウンドリー・サービスだ。この分野は急成長しており、研究開発に全力を注いでいけば、成長に限界はない。だからこそ私たちはファウンドリー事業に徹して最大の成功を追求する』
[チャレンジと楽しさがある職場環境]
-TMSCでは、チャレンジができ、学びがあり、そして楽しさがある職場環境は、金銭報酬より重要だと考えている。また、優秀で志の高い人材を確保するため、全員が力を合わせてこうした環境をつくり維持していく。
5.生産技術と賃金が2大ハードル
●TMSCは優位性を維持するため、生産技術、資金、サプライチェーンの三つに注目している。
●生産能力とプロセス技術は一心同体である。プロセス技術が整って初めて、生産性を爆発的に高めることができる。
●『半導体技術の進歩は非常に速い。モリスは彼の自伝の中で、TIに入社した当初、配属先のリーダーのプロ意識に感心したが、10年後も彼の技術的な考え方は変わっておらず、そのせいで大きな後れをとっていたと振り返っている。この教訓から、モリスは78歳でCEOに復帰した後も、技術トレンドに乗り遅れて経営判断を誤らないように、毎週、半導体の技術開発に関する記事や社内でとりまとめた資料を読み続けた。』
●『2021年3月末、TSMCの上層部は工場の新設・拡張のため今後10年間で2000億米ドルを投資すると発表した。生産能力を現在の倍にして、競合を突き放す狙いがある。TSMCではこの目標を達成するため、用地取得、電力供給や水資源の確保、人材育成などで先手を打つべく、様々な行動計画を打ち出している。』

画像出展:「台湾TSMC、米国で1000億ドル追加投資-先端半導体の生産体制強化」(Bloomberg)
『トランプ米大統領は3日、台湾積体電路製造(TSMC)が米工場に1000億ドル(約15兆円)を追加投資する計画を発表した。』
5.21世紀型AIマーケティング
●TSMCは2012年頃から、顧客サービスの将来を見据えて「AIマーケティング・見積価格設定システム」の構築を始めた。この巨大データベースには半導体産業の技術、市場、特許、関連業界、個別企業の経営状況などに関するデータが蓄積、常時更新される。AIの深層学習とアルゴリズムを活用したシステム、TSMCにとって競合他社との差を広げるためのツールである。特に価格設定システムは、チップ製造の受託を一製品として見積もるのではなく、業界全体の環境(研究開発のレベル、収益性、競合分析、市場規模と成長性、技術進化の動向など)を評価し、製品の成長段階や市場におけるポジションなど幅広い要因に応じて柔軟に価格を変化させる、AIを活用したダイナミック・プライシングを実現する。そのため、TSMCには「価格設定システム」を担当する副社長を責任者とする専門部署が設けられている。
解説
[ラピダスはTSMCのライバルとなるか]
●『今や最先端半導体を独占的に生産するTSMCだが、かつて半導体王国であり、グローバルシェアの半分を握っていた日本は、その半導体の栄光を取り戻すべく、大きな政策転換を遂げている。TSMCの工場を熊本に誘致するだけでなく、茨城県つくば市にある産業技術総合研究所とTSMCの共同研究機関である「TSMCジャパン3DIC研究開発センター」を設立して、後工程の3Dパッケージを研究するだけでなく、政府が3300億円を出資し、民間企業や銀行など8社の共同出資によってRapidus(ラピダス)を設立した。ラピダスは「ビヨンド2ナノ」を標榜し、最先端半導体のファウンドリーとして、日本の半導体産業を復活させる原動力にしようとしている。

『JRDCは、TSMCがクリーンルームを備えた研究開発施設として初めて台湾以外に設立した拠点で、日本のパートナー企業とともに、次世代の3次元集積化技術や高度なパッケージング技術の研究を推進しています。』

『日本ではロジック半導体の開発・製造が40nm世代で止まっています。Rapidusはこれを何世代も飛び越え、まだだれも達成していない2nm世代から始めるという非常にチャレンジングな目標を掲げています。』
このラピダスが成功するかどうかは時がたたなければ判断できないが、気になる点は、現代の半導体製造において不可欠な、巨額の設備投資を継続して行うだけの資本がどこから出るのかという点と、先端半導体を開発するための人材が十分に存在するかという点だ。
本書でも述べられているように、TSMCの成功には様々な要素があるが、ファウンドリーというビジネスモデルを支えてきたのは、政府からの出資だけでなく、収益性の高い製品から生まれる利益を投資に注ぎ込み、他のライバルが追いつかないほど設備投資を繰り返したことにある。ラピダスがTSMCのライバルとして勝ち抜くためには、同様の設備投資を続けなければならないが、果たしてそれが可能なのかどうかは疑問が残る。
また、TSMCの成功のカギは歩留まりの高さであったことは本書からも明らかだが、そうした歩留まり率を高めるためのノウハウは、いくら博士号を持った人材をそろえても得られるものではない。様々な半導体製造を経験し、現場で問題を解決する能力があるかどうかが勝敗を分ける。TSMCは台湾の中小企業によるOEM文化の中で育った企業であり、町工場における改良・改善のノウハウを持っていたからこそ、高い歩留まり率を実現できた。日本において、先端半導体の製造を支えるノウハウがあるわけではなく、それを身につけていくためには、他の半導体産業でのノウハウを蓄積した人材が必要となってくる。そうしたことが可能なのかどうかにも注目しておく必要があるだろう。』
感想
5年10兆円の巨大プロジェクトはオールジャパンの国家プロジェクトだと思います。台湾の半導体産業は明らかに国家レベルで進められ花開きました。キーワードは資金と人材(技術)です。
私が営業で経験したプロジェクトは、比較にならない小さな小さなプロジェクトばかりですが、プロジェクトの成否のカギは、「人・物・金を動かす客観的かつブレないリーダーシップ」に掛かっていることは確かだと思います。また、“競合&協業“というあり方も考えた方が良いと思いました。
追記(2025年11月26日):”ラピダス、世界最先端1.4ナノ半導体新工場 29年稼働でTSMCを追う”

AIの進化はGPUなどの半導体を指数関数的に増加させるため、TSMCに集中している状況の逼迫が、早ければ2026年後半にも電力供給問題とともに顕在化されるという予想もあります。ラピダスがその受け皿になれれば、世界の半導体需要に大きく貢献できると思います。
(記事の全文は有料です)
フィンテック2

第2章 どんなサービスがあるの?
◆お金を使う(決済)②
●作るのも、使うのも、お金の管理も簡単。若者に人気の「プリペイドカード決済」
・Suica、PASMOなど
◆お金を使う(決済)③
●売り手と買い手の利便性がともにアップ。スマホ1つで支払いができる「モバイル決済」
・PayPay、楽天ペイ、d払いなど
◆お金を使う(送金)①
●スカイプの技術を送金サービスに応用。為替手数料いらずで低コストの「海外送金」
・WISEなど
◆お金を使う(送金)②
●登録した「友人」に即入金できる。細かいお金のやり取りに使える「個人間送金」
・アカウント同士でお金のやり取り。業者形態によって特徴が異なる。
1)資金移動業者(事前にしっかり本人確認)・・・LINE Payなど
2)銀行業者(SNSと連携した口座へ送金)・・・楽天銀行など
3)前払い式支払い手段発行業者(受け取り側は現金化できない)・・・PayPay、楽天ペイなど
4)電子決済等代行業者(顧客と銀行を仲介する存在)・・・Money Tapなど
◆お金を借りる(融資)②
●今まで融資を受けられなかった層にもチャンスを。貸し手と借り手をつなぐ「ソーシャルレンディング」
・新しい与信判断で融資を受けられる人が広がった。
◆お金を増やす(投資)
●自分に最適のプランを提案してくれる資産運用の強い味方「ロボアドバイザー」
・ロボアドバイザーの仕組み
1)情報取集(投資に対する質問に回答)
2)ポートフォリオ作成(情報を分析し、ポートフォリオを作成)
3)金融商品の提供(ポートフォリオに沿った金融商品を提供)
例)
・トラノコ
◆お金を管理する①
●レシートを撮影するだけでOK。家計を自動で管理することができる「PFM」
例)
◆お金を管理する②
●知らない間にお金を貯められる!?ユニークな発想で楽しめる「自動貯金アプリ」
・ユニークなルール設定で楽しく貯められる (貯金アプリ「フィンビー」のルール例)
1)おつり貯金(支払い時の差額を貯める)
2)シェア貯金(複数人で目的のために貯める)
3)歩数貯金(歩数条件に応じて貯まる)
◆金融機関向けのサービス
●本人確認から利用者とのやり取りまで。膨大な業務をテクノロジーで支援する
例)
・TRUSTDOCK(デジタル身分証アプリ)
・iYell(金融機関の住宅ローン事業を支援するサービス)
◆新しいサービス①
●パソコン、インターネットに続くイノベーション。発行者も管理者もいない新しい通貨「仮想通貨」
・2024年時点で、世界中で流通している仮想通貨の種類は20,000種類を超えており、ビットコイン以外も含めて、日々新しい仮想通貨が登場し続けています。
・米国では「安全性と成長力を両立させた新たな“デジタル・ドルエコシステム”づくり」の方針が出ています。
◆新しいサービス②
●給料や代金支払いをよりフレキシブルに。若者に人気の「前払い・後払い」サービス
例)
・Payme(給与の一部を最短即日払いで受け取れる)
・NP後払い(様々な通信販売で利用できる後払いサービス)
◆金融を超えるフィンテック①
●健康促進からマーケティングまで。IT技術で革新を起こす「保険テック(インステック)」
・ヘルスケアの例
1)ウェアラブル端末の情報から健康状態を評価、予測して保険料に反映
2)保険契約者の健康促進のための健康診断サービスなどを提供
・保険の引き受けの例
1)保険の引き受けの判断材料の処理をAIがサポート
2)コールセンターでの回答にAIを活用
・マーケティングの例
1)顧客データと公的機関のデータを掛け合わせてマーケティングに活かす
2)ビッグデータの解析結果を保険料に反映
◆金融を超えるフィンテック②
●これからITが必要になる業界。不動産に関わる課題を解決する「不動産テック(プロップテック)」
・オンラインでの内見疑似体験などを利用することでより質の高い情報を提供できる。
・悪質業者情報を共有することにより不動産取引の透明性が増し、安心感が生まれる。
・売り手と買い手が直接つながる機会が生まれる。
・価格査定や売却物件の予測情報の精度が上がる。
・潜在的なニーズに目が向けられるようになる。
例)
・RENOSY(不動産売買等に関するサービス)
・OHEYAGO(セルフ内見やオンライン申し込みなどができる不動産賃貸サイト)
第3章 これから何が起こるの?
●知らぬ間にサービスを利用していることも。知識や判断力が、損得を決める時代に
・金融は「黒子」のような存在と言われているが、フィンテックの普及によって金融は生活のなかにますます黒子的入っていくと考えられる。今までは金融サービスを比較し選択していたが、これからはそのようなプロセスを経ないで自動的にサービスが適用されるようになるだろう。
・金融の知識(リテラシー)の有無が貧富の差につながる可能性が大きい。
・フィンテックの普及に伴い、それに便乗した詐欺が増えたり、情報が漏洩しやすくなったりする。
◆社会はどう変わる?①
●銀行は、金融業からサービス業へ。顧客視点に立った改革はますます進む
・フィンテックの普及で最も影響を受けているのは銀行である。
・システム部門が主導して、新たなフィンテック企業の発掘や他業者との連携といったイノベーションを推進
・資本提携やグループ化によるフィンテック企業の囲い込み
・銀行口座とフィンテックサービスをAPI(アプリケーション・プログラミング・インターフェース)で連携させる。
◆社会はどう変わる?②
●証券会社からカード会社、ITベンダーまで。金融業界の仕事は大きく変化する
・証券会社:ブローカ業務にとっては脅威に、ディーラー業務ではデータ収集や分析で支援を受けることもある。
・クレジットカード業界:業務の効率化や利用明細のリアルタイム配信によりセキュリティコストを削減。
・ITベンダーが金融機関とフィンテック企業を繋ぐ役割をはたす。

画像出展:「セゾンテクノロジー、データ連携ビジネスが拡大」
セゾンテクノロジーはクレディセゾンが46.84%の株を保有している企業でHUFTというファイル転送・データ連携ミドルウェアは国内約80%のシェアです。このような金融系ITベンダーがフィンテックの鍵を握っていると思います。
◆社会はどう変わる?③
●ケータリングから民泊まで。「実体を扱う事業会社」が金融を展開
例)
Airbnb(部屋を貸す人向けにローンを提案したり、独自の電子マネーを発行したりする)
◆生活はどう変わる?②
●気づかないうちに始まっていた!?金融サービスはより「黒子的」な存在に

画像出展:「押さえておきたいエンベデッドファイナンス。注目を集める新たなFinTechの潮流と仕組み」
『「自分たちが消費者に直接金融サービスを提供するわけではなく、そのようなサービスを提供したいと考えている事業者の黒子として、裏側で必要な仕組みを提供する」プレーヤーが注目を集め始めています。』
◆生活はどう変わる?②
●学べば学ぶほど、得する世界。「お金の教育」が義務化されるのも近い
・フィンテックが普及すると、より多くの人がバリュエーション豊かな金融サービスを利用できるようになるため、状況に応じて最適なサービスを適切に選ぶためには、お金や金融に関する知識や判断力(金融リテラシー)を身につけることが大切である。
◆生活はどう変わる?④
●増える詐欺や、情報流出。情報リテラシーを身につけよう
・情報リテラシーを高めるための方策
1)迷惑メールなどのウィルス対策を万全にする
2)IDやパスワードの使い回しは避ける
3)SNSなどでの個人情報発信を慎重に行う
4)新しいサービスや業者は事前に信頼性を確認する
第4章 フィンテックを支えるキーテクノロジー
●テクノロジーの大幅な進化がフィンテックの誕生と発展を支えてきた

画像出展:「ITは加速しながら新たなステージへ」
AIは第二の情報革命ともいわれています。
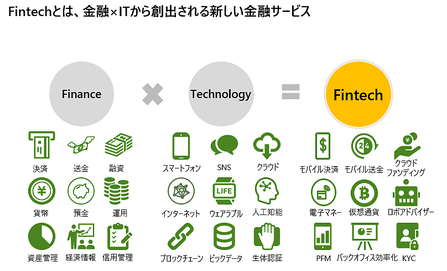
画像出展:「新たなキーワードはシームレス。銀行・保険・証券の相互乗り入れで新サービスが加速する」
『FintechはFinanceとTechnologyを掛け合わせた造語で、既存の金融の機能と新しいテクノロジーを組み合わせて新しいサービスを作っていこうというムーブメントを支えています。』
感想
「フィンテックは価値や富を自由に、安く移動できるようにする」というのが最も端的な説明ではないかと思います。圧倒的な利便性が進む一方で、“エンベデッドファイナンス”のように金融サービスの黒子化は進んでいます。特に潜在的なリスクを含め、安全とリスクの現状をどのように把握するのが良いのか、AI(Perplexity)に質問してみました。この課題はずっと続くものだと思います。
フィンテック1
とある理由でフィンテックを少々勉強する必要があり、1冊の本を購入することにしました。

監修:桜井 駿
編集:福島広司
発行:2020年5月
出版:(株)幻冬舎
ITでお金はもっと身近になる
フィンテックって何? 理解するための7つのキーワード
第1章 フィンテックはなぜ生まれたの?
●海外で生まれ、人気のフィンテックサービス。日本は遅れているって本当?
◆フィンテックはどこで生まれたか?①
●インターネットサービスの普及に伴い、新しい金融サービスが次々に誕生
◆フィンテックはどこで生まれたか?②
●大手金融機関が破綻したことで、人々の“金融機関離れ”がさらに進んだ
◆フィンテックはどこで生まれたか?③
●スマートフォンの使用者が増え、サービスの提供・利用がしやすくなった
◆フィンテックは今どこにいる?①
●ステージ1:すでにあった金融サービスがIT技術でより便利になった
◆フィンテックは今どこにいる?②
●ステージ2:これまで存在しなかったあたらしい金融サービスが登場した
◆フィンテックは今どこにいる?③
●ステージ3:大きなIT企業やテクノロジー企業が、独自の金融サービスを始めた
◆フィンテックは今どこにいる?④
●ステージ4:建設業や不動産業など、規制の厳しい他業界まで波及
◆日本のフィンテックはどうなっている①
●日本では、現状の金融サービスが充実。新しいサービスはゆっくり広まる
◆日本のフィンテックはどうなっている②
●金融機関とIT企業が手を取り合って、より便利なサービスを作り出している
◆日本のフィンテックはどうなっている③
●フィンテックの普及に向け、法改正も。これからの発展が期待されている
1分でわかる! 第1章のおさらい
第2章 どんなサービスがあるの?
お金を使ったり、借りたい、管理したり。様々な分野でサービスが展開されている。
◆お金を使う(決済)①
●ネットショップでのやり取りに欠かせない。売り手と買い手をつなぐ「オンライン決済」
◆お金を使う(決済)②
●作るのも、使うのも、お金の管理も簡単。若者に人気の「プリペイドカード決済」
◆お金を使う(決済)③
●売り手と買い手の利便性がともにアップ。スマホ1つで支払いができる「モバイル決済」
◆お金を使う(送金)①
●スカイプの技術を送金サービスに応用。為替手数料いらずで低コストの「海外送金」
◆お金を使う(送金)②
●登録した「友人」に即入金できる。細かいお金のやり取りに使える「個人間送金」
◆お金を借りる(融資)①
●会ったこともない人が支援者になる。夢のスタートを支える「クラウドファンディング」
◆お金を借りる(融資)②
●今まで融資を受けられなかった層にもチャンスを。貸し手と借り手をつなぐ「ソーシャルレンディング」
◆お金を増やす(投資)
●自分に最適のプランを提案してくれる資産運用の強い味方「ロボアドバイザー」
◆お金を管理する①
●レシートを撮影するだけでOK。家計を自動で管理することができる「PFM」
◆お金を管理する②
●知らない間にお金を貯められる!?ユニークな発想で楽しめる「自動貯金アプリ」
◆お金を管理する③
●中小企業の会計情報を、見える化。経理業務の効率アップする「クラウド会計」
◆お金を管理する④
●従業員も会社も、業務効率アップ。「クラウド型経費精算サービス」
◆金融機関向けのサービス
●本人確認から利用者とのやり取りまで。膨大な業務をテクノロジーで支援する
◆新しいサービス①
●パソコン、インターネットに続くイノベーション。発行者も管理者もいない新しい通貨「仮想通貨」
◆新しいサービス②
●給料や代金支払いをよりフレキシブルに。若者に人気の「前払い・後払い」サービス
◆金融を超えるフィンテック①
●健康促進からマーケティングまで。IT技術で革新を起こす「保険テック(インステック)」
◆金融を超えるフィンテック②
●これからITが必要になる業界。不動産に関わる課題を解決する「不動産テック(プロップテック)」
1分でわかる! 第2章のおさらい
第3章 これから何は起こるの?
●知らぬ間にサービスを利用していることも。知識や判断力が、損得を決める時代に
◆社会はどう変わる?①
●銀行は、金融業からサービス業へ。顧客視点に立った改革はますます進む
◆社会はどう変わる?②
●証券会社からカード会社、ITベンダーまで。金融業界の仕事は大きく変化する
◆社会はどう変わる?③
●ケータリングから民泊まで。「実体を扱う事業会社」が金融を展開
◆生活はどう変わる?①
●未来では、「データのお金」が現金と同じくらい大切なものになる
◆生活はどう変わる?②
●気づかないうちに始まっていた!?金融サービスはより「黒子的」な存在に
◆生活はどう変わる?②
●学べば学ぶほど、得する世界。「お金の教育」が義務化されるのも近い
◆生活はどう変わる?④
●増える詐欺や、情報流出。情報リテラシーを身につけよう
1分でわかる! 第3章のおさらい
第4章 フィンテックを支えるキーテクノロジー
●テクノロジーの大幅な進化がフィンテックの誕生と発展を支えてきた
◆モバイル
●フィンテックサービスの利用にも発展にも欠かせない存在
◆クラウド①
●“雲の向こう”で作られたサービスをいつでも好きなだけ利用できる
◆クラウド②
●新しいフィンテテック企業が新サービスを開発・運用しやすくなった
◆ビッグデータ①
●膨大な情報を集めて解析することで新たなサービスが生まれる
◆ビッグデータ②
●個人情報の収集や活用は、金融サービスの発展に不可欠なもの
◆AI(人工知能)①
●限りなく人間に近い存在になった。状況判断や意思決定ができる人工知能
◆AI(人工知能)②
●人より精度の高い分析ができる。融資や投資の分野で人工知能が活躍
◆API(アプリケーション・プログラミング・インターフェース)①
●1つの入り口から複数のサービスを使うには企業と企業の「連繋」が欠かせない
◆API(アプリケーション・プログラミング・インターフェース)②
●API公開にはメリット、デメリットがある。どこまで連繋を許すかはこれからの課題
◆ブロックチェーン①
●全ての取引記録が1本の鎖に。改ざんも不正もできない分散型台帳
◆ブロックチェーン②
●世界中にいるたくさんのマイナーたちが、ブロックをつなぎ、報酬をもらっている。
◆IoT
●あらゆるモノがネットにつながりより多くの情報が集められるようになる
◆デザイン(UIとUX)
●サイトの見やすさ、わかりやすさは、フィンテックサービスの大きな強み
1分でわかる! 第4章のおさらい
キャッシュレス決済が普及。今、フィンテックの「入り口」に
ITでお金はもっと身近になる

フィンテックって何? 理解するための7つのキーワード
●IT技術で便利になった金融サービス
・フィンテックは「金融=Finance」と「IT技術=Technology」を掛け合わせた造語、IT技術を駆使した金融サービスのことである。
・注目されるようになった金融機関以外のベンチャー企業やスタートアップが金融サービスを提供し始めたため。
●金融危機で発展し、技術の進歩で加速
・リーマンショックで優秀なIT技術者が金融業界を離れ、ベンチャー企業やスタートアップに移って、新しい金融サービスを始めた。
・IT技術の進歩により加速的に発展した。
●金融・情報リテラシー
・自分のお金や個人情報は自分の力で守る意識を持つことが必要
・フィンテックが発展すると個人情報の流出や詐欺のリスクが高まる。
ご参考:“フィンテック時代に必要な金融知識は何か?”
第1章 フィンテックはなぜ生まれたの?
◆フィンテックはどこで生まれたか?①
●インターネットサービスの普及に伴い、新しい金融サービスが次々に誕生
・1998年に誕生したオンライン決済のPayPalがフィンテックの先駆けと言われている。

画像出展:「PayPal戦争と今日の起業家への教訓」
PayPalの創業メンバーはPayPalマフィアと呼ばれています。その中でもイーロン・マスクとピーター・ティールが有名です。PayPalマフィアが注目されているのは、PayPal在籍後、YouTube、LinkedIn、 Tesla、 SpaceX、Palantir、 Yelpなど世界的なテック企業を次々と創業し、また、投資家として新興企業を強力に支援したためです。
・金融機関が担っていた“決済”・“融資”・“送金”・“投資”が規制緩和やIT技術の進歩によって細分化され、専門的に行うサービスが誕生した。
◆フィンテックは今どこにいる?②
●ステージ2:これまで存在しなかったあたらしい金融サービスが登場した
・いろいろな悩みをITで解決
1)割り勘は面倒・・・割り勘アプリ(小銭不要)
2)貯金をしたい・・・自動貯金アプリ(知らない間に貯蓄できる)
3)銀行を通さないでお金のやり取り・・・仮想通貨(国や銀行が関わらない)
4)毎月の高額の保険料は大変・・・わりかん保険(保険金を割り勘にする)
◆フィンテックは今どこにいる?③
●ステージ3:大きなIT企業やテクノロジー企業が、独自の金融サービスを始めた
・ベンチャー企業やスタートアップだけでなく、AmazonやMeta(Facebook)が大規模な顧客基盤を背景に参入。
2014年2月から開始されたもので、Amazonのマーケットプレイスに参加している法人販売事業者を対象に行なっている融資サービス。Amazonレンディングには通常の融資では考えられない数多くの個性的な特徴がある。
◆フィンテックは今どこにいる?④
●ステージ4:建設業や不動産業など、規制の厳しい他業界まで波及
1)医療・・・MedTech(ヘルスデータの連繋で医師と患者をつなぐ)
2)建設・・・ConTech(現場と職人のマッチング)
3)保険・・・InsTech(企画から提案、販売までオンライン)
4)不動産・・・PropTcch(物件の売買・契約の他、民泊サービスなど)
あらゆる業種において支払い・請求というお金の流れが存在する。これらはフィンテック関わってくる。
◆日本のフィンテックはどうなっている①
●日本では、現状の金融サービスが充実。新しいサービスはゆっくり広まる
・普及しづらい4つの理由
1)教育や経済状況などの水準が揃っている
2)規制が厳しく言語対応に時間がかかる
3)現状でも便利なのでニーズに乏しい
4)サービスに対して求めるレベルが高い
◆日本のフィンテックはどうなっている②
●金融機関とIT企業が手を取り合って、より便利なサービスを作り出している
・脅威から協業路線へ。互いの強みを持ち寄り、より良いサービスが登場。
・金融が身近なものになり、また、仮想通貨などの新しいサービスが出てきたことにより、お金や金融を考える時代になってきた。
マーク・ザッカーバーグ
IT営業を25年勤め、私にとってのカリスマは“スティーブ・ジョブズ”です。他界されたのはおよそ14年前でした。
そして、第二の情報革命といわれるAIがいよいよ本格化する今、ITのカリスマは誰だろうと思いました。最初に頭に浮かんだのは“イーロン・マスク”です。一時、DOGE(米政府効率化省)のリーダーとなっていましたが、現在は代わっています。また、DOGEは内閣レベルの省庁ではなく、特別な一時的組織(USDOGE Temporary Organization)として設置されており、活動は2026年7月4日までの期限付きということです。
また、イーロン・マスクが目指している世界は、「人類の長期的な存続と進化を実現するためのテクノロジー主導の世界」とのことです。以下の表はマスクが関わっている(関わった)企業ですが、これを見ると本気だなということが分かります。

画像出展:「AI(Perplexity)が作成」
テスラについてはオプティマス(ロボット)が注目されています。
「人類の長期的な存続と進化を実現するためのテクノロジー主導の世界」というものは、あまりに巨大でピンときません。私がイメージする“カリスマ”とは少し違う気がします。
こちらの資料はAI(Perplexity)が作ったものです。これを見るとイーロン・マスクは、やはり“カリスマ”であって“ビジョナリー”ではないことは明らかです。ただ、最後に書かれたイーロン・マスクが“異色・現代型”のカリスマ“ということだとすれば、私にとってはやはり違うという印象です。
イーロン・マスクの次に頭に浮かんだのは、“マーク・ザッカーバーグ”です。個性の強烈さではイーロン・マスクにかないませんが、年齢はイーロン・マスクが51歳(1971年6月28日生)、マーク・ザッカーバーグが41歳(1984年5月14日生)と10歳の差があります。総資産の順位は1位がイーロン・マスク、ザッカーバーグは3位です(2025年9月22日時点)。

画像出展:「AI(Perplexity)が作成」
そして、ザッカーバーグが目指すものは「すべての人に“パーソナル・スーパーインテリジェンス(超知性)”を提供し、AIの恩恵を社会全体で共有する社会」ということです。私のカリスマ像に照らし合わせれば、カリスマは“マーク・ザッカーバーグ”だなと思います。
なお、NVIDIAのCEOである“ジェンスン・フアン”は、「AIの父」というイメージです。


編者:ジョージ・ビーム
訳者:今村絵里
発行:2022年11月
出版:(株)文響社
序章 マーク・ザッカーバーグの半生
PART1 船出(2002-2009)
マーク・ザッカーバーグの歩み PART1
●人の下で働きたくない
●引き延ばし
●仲違い
●どん底で見つけたアイデア
●些末なこと
●人生の目標
●最終目標は金じゃない
●試行錯誤を楽しむ
●スタートアップ
●Facebookの原型
●持続可能なビジネス
●優先順位をつける
●採用条件
●簡単に逃げない
●謝罪
●長期的な視点
●理想的な働き方
●目の前の仕事に集中する
●雑音に耳をかさない
●CEOの役割
●情報の充実
●個人情報の管理
●ユーザーが主役
PART2 加速(2010-2011)
マーク・ザッカーバーグの歩み PART2
●若気の至り
●成功をつかむ条件
●価値あるものを生む
●機が熟すのを待たない
●経営理念
●情報のカスタマイズ
●Facebookの基本ルール
●オープンな世界
●機能の簡素化
●社風
●目先の大金
●起業家が持つべき資質
●せっかち
●ユーザーへの感謝
●つながりをサポートする
●アイデアを拾い上げる
●職場環境
●「ソーシャル・ネットワーク」
●ハッキング
●欲望を捨てる
●コンピュータは手段にすぎない
●ソーシャルプラットフォーム
●幸運な偶然
●願い
●起業への助言
●成長できる環境
●起業
●最大のリスク
●成長の糧
●人間の欲
●自己表現のためのSNS
●簡単なことから始める
●日常の一部になる
PART3 使命(2012-2014)
マーク・ザッカーバーグの歩み PART3
●初の役員会議
●イノベーションの素
●コーディングの上達
●効率の向上
●リスクを恐れない
●Facebookの真骨頂
●Facebookの役割
●1対1で話す
●社の信条
●等身大であれ
●短所と長所
●Facebookの誇り
●エンジニアの責任
●量より質
●テクノロジーの恩恵
●実名を使うSNS
●価値観
●知恵を共有する
●よいチームとは
●新たな社訓
●土台作り
●インターネットを広める
PART4 明暗(2015-2016)
マーク・ザッカーバーグの歩み PART4
●孤独を打ち消す
●仕事時間
●全人類をつなげる
●広い視野
●会社員が平等
●風とおりのよい職場
●会社の存続は二の次
●クリエイティブな若者
●少年時代
●日常
●ダメ出しはいらない
●インターネットの普及
●コンテンツ共有
●育児休暇
●未来に対する責務
●次世代に伝えたいこと
●所有株の99%を寄付する
●インターネットによる救済
●自由を守る
●運用エネルギー
●ライバルは二の次
●ビジョンを実現する
●表現欲
●日常とサービス
●癖
●無料にこだわる
●コードは議論に勝る
●まずは飛び込む
●チャンスは先にある
●未来は作れる
●未来予測
●ファッション
●一歩目
●選挙への貢献
●インターネットの課題
●人工知能
PART5 原点(2017-2018)
マーク・ザッカーバーグの歩み PART5
●全体の中のポジション
●人間として向き合う
●検閲はしない
●第二子
●多様性を高める
●信頼できるコンテンツ
●ひらめきよりも行動
●結果はすぐ得られる
●歩みを止めない
●人々の暮らし
●決断のポイント
●採用基準
●矜持
●格差
●日々思うこと
●問題を放置しない
●世界の課題に向き合う
●インターネットの無償化
●子どもへの思い
●信じるもの
●子どもの可能性
●VRの可能性
●必要経費
●自己研鑽
●自分の役割
●親
●情熱を持つ
●悲観を活かす
●誇れる仕事
●良質なサービス
●つながりがもたらす効果
●Facebookが果たす責任
●社会的責任
●セレクション
序章 マーク・ザッカーバーグの半生
才能を伸ばし続けた少年時代
・『マークは子どもの頃から既に生半可な知識では太刀打ちできない相手だった。父であるドクター・ザッカーバーグによれば、息子の質問に「イエス」と答えた場合には、それ以上説明する必要はなかったが、「ノー」と答えた場合にはたちまち反論にあい、言葉を尽くして理由を説明しなければならなかったという。両親は、我が子はいずれ弁護士になると思ったかもしれないが、マークの興味は別のところにあった。コンピュータサイエンスという2進数の世界だ。
幼い頃から、マークのコンピュータ好きは明らかだった。12歳の時には、Atari BASICを使ってメッセージをやり取りするソフトウェアのプログラム「Zucknet」を作り、これは自宅や父親の歯科医院でも使われた。我が子がコンピュータサイエンスに並々ならぬ関心を抱いていると気づいた両親は、ソフトウェア開発者を家庭教師として雇うとともに、近隣のマーシー大学でBASICプログラミングのクラスを受講させ、コンピュータサイエンスのカリキュラムが充実していた全寮制の名門私立高校フィリップス・エクセター・アカデミーへと転校するのを手助けした。
こうして、高校時代には、ユーザーの好みに合わせて自動的に選曲が行われる音楽再生ソフト「Synapse」を開発した。このソフトウェアに興味を示したマイクロソフトやAOLに買収を持ちかけられるが、その申し出を断り、ソフトを無料配布するまでになっていた。』
調べたところ、マーシー大学で受講していたのは、地元のアーズリー高校に通っていたときです。年齢は15歳でした。そして、2年ほど在学した時点で中退を考えたようですが、ご両親に説得され、中退ではなく転校することを決意します。転校先は、自宅から300Km離れたフィリップス・エクセター・アカデミーという卒業生の大半がハーバード大学、コロンビア大学、ケンブリッジ大学、オックスフォード大学といった名だたる名門校へ進学する超名門校でした。
※ご参考:“マーク・ザッカーバーグ”
PART1 船出(2002-2009)
マーク・ザッカーバーグの歩み PART1
●人生の目標
・『クールなものを作るのがとにかく好きだし、人にあれこれ指図されたり、決められた時間内に物事をこなしたりしなくていいというのが、僕の人生の中で手にしたいと思っている贅沢なんです。
・・・利益を生み出すものをいつかこの手で作れると思います。』 2004年
●採用条件

【地頭のよさ】=“raw intelligence”とのことです。
「心からの共感」も非常に重視されています。
最も重要な条件は、「地頭のよさ」とのことです。英文を見ると「地頭」は、英語では“raw intelligence”となっています。私事ですが、約50年前に通っていた母校(高校)は、「生徒の地頭は良い」との評判でした。そのため、この「地頭」という言葉は何となく気に入っていました。そもそもどういう意味か詳しく調べることはなかったのですが、今回、特に英語の“raw intelligence”の意味を知りたいと思い調べてみました。
●長期的な視点
・『僕の役目は、長期的な視点でものを作ることです。それ以外のことはじゃまでしかありません』 2007年
●CEOの役割
・『CEOの役割は基本的には2つあると思います。すなわち、会社のビジョンを設定すること、チームを作ることです。僕たちはビジョンを定め、今まさに実行しているところなんです。4年前に創業したばかりなので、しなければならないことはまだ山ほどありますね。
中でも、チーム作りは本当に重要です。チーム作りには多くの時間を割いて懸命に取り組んでいます。』 2008年
PART2 加速(2010-2011)
マーク・ザッカーバーグの歩み PART2
●起業家が持つべき資質
・『[よい起業家・CEOに必要な資質の]1つは、自分のやりたいことをしっかりとわきまえていることです。なぜなら仕事をしていると煩わしいことが次々と出てくるので、自分のやりたいことを100%把握していないとあらぬ方向へ行ってしまうからです。自分のやりたいことを把握し、しっかりと胸に刻んでおくこと。これが第一ですね。
第二は、よいチームを作ることです。このことに僕は膨大な時間を費やしています。製品作りに携わっていない時には―僕はチームと一緒に製品作りに取り組んでいるのですが―本当に優れたエンジニアリング部門のトップや、最高のハッカーやエンジニア、もの作りをしたい人々を集めることから、これから取り組むことを正確に伝え、全社員に計画の内容をしっかりと理解させることのできる製品部門のトップ、そして[FacebookのCOO]であるシェリル[・サンドバーグ]のようなビジネスに非常に長けた人材に至るまで、組織の隅々まで目を配ってチーム作りを行なっています。
・・・僕が会社を経営すべきか否か? もし僕がいなくなっても、舵取りは問題ないでしょう。自分の仕事をきちんと分かっていて、優れたスタッフがいれば、その時点で大成功なのです。』 2010年
ハッカーというと犯罪のイメージが強いと思いますが、米国ではハッカーとは、本来はコンピュータやネットワーク、暗号技術、プログラム解析など高度な技術を持つ技術者を指す言葉とのことです。
●ソーシャルプラットフォーム
・『これからの5年間は、ソーシャルプラットフォームを作り上げる時間になると思っています。
柱となる考えは、ほとんどのアプリケーションが今後ソーシャル化し、大多数の産業はソーシャルデザインや友人との共同作業を中心とした仕組みに見直されるということです。』 2010年
PART3 使命(2012-2014)
マーク・ザッカーバーグの歩み PART3
●よいチームとは
・『僕が思うよいチームとは、チームとして集まった時のほうが、個々でいる時よりもよい決断を下せる集団のことです。』 2013年
●新たな社訓
・『我が社の社訓を、「素早く行動し、破壊せよ」から「土台を固めた上で、素早く行動せよ」に変更しました。』 2014年
日本語にすると、強い表現だなと思います。原文は、We’ve changed our internal motto from “Move fast and break things” to “Move fast with stable infrastructure”.です。共通しているのは“Move fast”です。ちなみにモットー(motto)が英語であったことを初めて知りました。調べたところ明治時代に入ってきた言葉だそうです。
感想
「何故、カリスマになれたのだろう?」というのが疑問でした。
12歳の時にメッセージをやり取りするプログラムを作ったというのは明らかに天才少年です。しかし、世界規模で見渡せば、同じような天才はいると思います。
次に思ったことは、ご両親の理解と支援です。「ソフトウェア開発者を家庭教師として雇うとともに、近隣のマーシー大学でBASICプログラミングのクラスを受講させた」とあります。調べたところ、地元のアーズリー高校時代(15歳)の時の話のようです。高校に希望が見出せず中退しようとしたザッカーバーグに対し、ご両親は全寮制の名門私立高校フィリップス・エクセター・アカデミーへと転校を勧めます。
「やはり、裕福だったのが大きな要因だったのかな?」と思い、フィリップス・エクセター・アカデミーを調べてみました。そこには色々な発見と驚きがありました。

画像出展:「フィリップス・エクセター・アカデミー①」 こちらが高校のホームページのトップページです。

画像出展:「フィリップス・エクセター・アカデミー②」 最初の驚きは『入学選考に、ご家庭の経済状況には一切関係ありません』という掲示です。
画像出展:「フィリップス・エクセター・アカデミー③」 「本当かな?」と思って調べると、『年収$125,000(1ドル150円換算で約1875万円)未満の家庭は授業料が無料です。』となっていました。
(下の方に出ています)

画像出展:「フィリップス・エクセター・アカデミー④」 日本の私立の超進学校を想像し、「もっぱら勉強なのかな~?」と思って調べると、運動施設の充実には物凄いものがありました。運動以外の施設も充実しており、「とてもかなわない!」という感じです。
画像出展:「フィリップス・エクセター・アカデミー⑤」 日本では東京大学や京都大学を目指すためという印象ですが、エクセターには450以上の学術コースがあります。ハークネス教育アプローチとは楕円形等の「ハークネステーブル」を囲み、教師と生徒が対等な立場で自由に対話を重ねながら学ぶディスカッション型の教育法だそうです。
日本の高校は総じて、大学に“入るため”の勉強を教えるところという感じですが、米国のフィリップス・エクセター・アカデミーをみると、米国を引っ張っていくリーダーを育てること。そして、“大学で更に専門的に学ぶため”に実体験を通して、何を専攻しどこの大学に進学するのが自分にとって1番の選択かを判断できるようにするという感じです。
単純に、“カリスマ(特にビジネスや政治)”が出現するような土壌として両国の教育を比べるならば、圧倒的に米国の方が可能性は高いと思います。
脱線しますが、スポーツの世界に限ってみれば、幼少の頃から学びを求めて世界に出ていくケースもみられます。日本代表で活躍されている久保建英選手がスペインのバルセロナの下部組織(カンテラ)に入団したのは9歳です。そしてスペインに渡って育成を受けていました。国内ではJリーグが発足し最年少出場記録は15歳7ヶ月(高校1年生)です。若くして日本のトップリーグでプレーすることも夢ではなく、さらに、そこから世界への道も見えてきます。
ザッカーバーグが「何故、カリスマと言われるようになったのか」の理由の一つめは、ご両親の理解と米国の自由で深い教育システム(育成の在り方)にあったと思います。
二つめの理由は、ザッカーバーグの目標が“お金“ではなく、“自分の理想の実現”という高いものであり、目標達成のために一切の妥協を許さなかったことだと思います(理想とする物づくりへのこだわりと志の高さ)。これは以前、ブログにアップさせて頂いた“スティーブ・ジョブズ”と“ウォルト・ディズニー”とまったく一緒です。
このように考えた具体的なエピソードは2つです。
1.高校時代に開発した音楽再生ソフト「Synapse Media Player」
ザッカーバーグは、高校時代に開発した音楽再生ソフト「Synapse Media Player」に対し、マイクロソフトやAOLから100万ドル規模の買収・出資提案を受けていました。しかし、彼はこのオファーを一貫して拒否しています。詳細は添付資料をご覧ください。

画像出展:「AI(Perplexity)が作成」
2.慈善財団「Chan Zuckerberg Initiative」の設立
最初から慈善財団を作るのが目的だったとは思えません。また、30兆円を超える資産の使い道など途方もないものだと思いますが、慈善事業に資産を使うということは、本当に素晴らしい称賛されるべきことです。

画像出展:「Facebook創業者5.5兆円寄付と資産永久防衛策の慈善財団」
『SNSフェースブックの創業者マーク・ザッカーバーグ最高経営責任者(CEO)と妻のプリシラ・チャン氏が1日、自身が保有する同社株の99%を、夫婦で設立する慈善財団「Chan Zuckerberg Initiative」を通じて慈善活動に寄付すると発表した。寄付する予定の株式時価は現在450億ドル(約5兆5300億円)と、個人としては過去にほとんど例がないほどの巨額になる。』
三つめの理由は、米国が失敗に寛容で正当なチャレンジであれば評価する社会だからだと思います。スポーツの世界は失敗が当たり前、目標に向かって努力と工夫と強い信念で日々の練習を積み重ねて、課題を超えていくものです。
日本の政治やビジネスの世界は、前例が重要でリスクはなるべく取りたくないという意識が一般的だと思います。少なくとも、チャレンジは評価されるどころか、煙たがれるというのが実態ではないでしょうか。(これは「チャレンジ≠勝ち馬&チャレンジ≠評価」という理由が大きいと思います)
野球の世界では“大谷翔平”という日本人のカリスマ選手が誕生しましたが、特にビジネスにおいて、日本から世界的なカリスマ経営者が生まれる可能性は、起業に対する高くない評価と忖度が根強い日本の組織の力学においてはかなり難しいように思います。
※Meta Platformsの課題
IT、特にAIの進歩はSNSなどを通じての不正利用が拡大、巧妙化する原因にもなります。以下の表は2024年、2025年にニュースになったものの一覧です。Metaに限ったことではありませんが、社会は不正利用に対する企業側の迅速かつ適切な対応を求めおり、その対応を誤ると信頼を失うという大きなリスクも抱えていると思います。

画像出展:「AI(Perplexity)が作成」
ディープラーニング2

終章 変わりゆく世界―産業・社会への影響と戦略
変わるゆくもの
●ある環境の中で機能を発揮する特定の仕組みであり、その見えない相互作用が知能である。
●インターネットは情報流通に革命を起こした。以前は流れなかったところにも情報が流れるようになった。従来は先生から生徒、上司から部下、メディアから大衆という直線的な流れは横方向にも広がりをもつようになった。これらは組織や社会システムと関係ない情報の流れであり、様々な新しい付加価値を生んだ。
●人工知能によって生み出される変化は「知能」という、学習し、予測し、そして変化に追従するような仕組みが、今度は人間や人間が属する組織と切り離されるということである。今までは組織においては然るべき階層まで上がって組織としての判断を下していた。個人の判断は1つの身体ゆえに処理できる数は限られていた。それがルールや濃淡、数に制約はあるものの同時並行的に分散して行うことができるようになる。
●人という物理的存在に依存していた知能が、必要条件の範囲においてにはなるが、地球上の必要とされる所に自由に配置できることは、人工知能が人類の発展に大きく貢献できる要素ではないか。
じわじわ広がる人工知能の影響
●人工知能は研究開発が先行するので、ビジネスに展開されるまでには時間がかかる。
●防犯は社会的コンセンサスが取りやすいので、防犯カメラと過去の犯罪履歴のデータベースを組み合わせた監視ネットワークは大きく治安に貢献できるだろう。ただし、個人の行動履歴というプライバシーの問題をクリアする必要がある。
●製造業では熟練工の技術の分野にも入っていける可能性がある。また、「改良」や「改善」に取り組んできた製造現場において、ディープラーニングによって人工知能が特徴量を自ら掴むようになると、新しい工程を「設計」できるようになるかもしれない。特に試行錯誤が許されている試作段階などのステージでは人工知能の利用が進むと思われる。
●製薬や材料の分野において、仮説生成まで人工知能が担えるようになれば、今まで以上に探索できる解の範囲が一気に広がるかもしれない。
●音楽や絵画といった芸術の世界にも、試行錯誤の頻度と効率を高めるため人工知能が進出するかもしれない。
●自動車に限らず、電車でも飛行機でも運転士・操縦士の大事な仕事の一つは「異常検知」であるが、これは特徴表現学習の得意とするところである。すでに飛行機は離着陸以外、その大半は自動操縦になっている。
●広告・マーケティングはデータマイニング等、すでにコンピュータが活躍している分野だが、短期的や一過性の利用から長期的に刻々と変わる顧客ニーズをリアルタイムに的確にとらえることで、完全自動化されていく可能性がある。ブランドイメージの向上や商品企画などの仕事に関しても人工知能の介在する余地は大きい。
●医療、法務、会計・税務は最も人工知能が入りやすい領域である。医療は画像診断技術の向上が期待できる。ただし、自動運転と同じように「診療の適切性」と「責任」の問題は難しい問題である。
●弁護士の仕事の中では、クライアントの情報を整理したり、関連法令をチャックしたり、過去の判例を調べたりすることは人工知能のメリットを活かしやすい。情緒的な面や当事者の利害関係を調整するという面は人間が得意とする領域である。
●金融は人工知能が活躍できる大きな領域である。顧客対応システムや資産状況に応じたポートフォリオを提供することは価値がある。証券会社や不動産会社はより付加価値の高い情報提供ができるように見直すことが求められるだろう。
●教育はデータ分析によってもっと進化する分野である。学習パターンや生徒の向き不向きをより的確につかみ、適した学習方法を提示することができる。個々の教師が個人的に持っているノウハウなど、教え方の知識は多くの生徒のデータを分析することでより客観的で質、量ともに充実したスキルを効率的に習得できるようになるかもしれない。一方、生徒のやる気を高めたり、効果的に競わせたりする方法は人間と人工知能がうまく連携することにより高いレベルの教育を提供できるのでないか。
近い将来なくなる職業と残る職業
●人工知能による変化は、多くの人に影響を与える可能性があるという点で、今までの変化とは異なるかもしれない。また、貧富の差が広がるのではないかと考えられている。これらは基本的には富の再分配によって是正するしかないが、格差や平等について考えることは非常に重要である。同様に国際的な経済格差に関しても考えなければならない。
●『この段階[2030年頃]で、人間の仕事として重要なものは大きく2つに分かれるだろう。1つは、「非常に大局的でサンプル数の少ない、難しい判断を伴う業務」で、経営者や事業の責任者のような仕事である。たとえば、ある会社のある製品の開発をいまの状況でどう進めていけばよいかは、何度も繰り返されることではないためデータがなく、判断が難しい。こうした判断はいわゆる「経験」、つまり、これまでの違う状況における判断を「転移」して実行したり歴史に学んだりするしかない。いろいろな情報を加味した上での「経営判断」は、人間に最後まで残る重要な仕事だろう。
一方、「人間に接するインタフェースは人間のほうがいい」という理由で残る仕事もある。たとえば、セラピストやレストランの店員、営業などである。最後は人間が対応してくれたほうがうれしい、人間に説得されるほうが聞いてしまうなどの理由で、人間の相手は人間がするということ自体は変わらないだろう。むしろ人間が相手をしてくれるというほうが「高価なサービス」になるかもしれない。』
●『さらに忘れてならないのが、人間と機械の協調である。すでにチェスでは、人間とコンピュータがどのような組み合わせで戦ってもよい、フリースタイルの大会がある。さまざまな仕事においても、この「フリースタイル」方式が出てくるはずである。人間とコンピュータの協調により、人間の創造性や能力がさらに引き出されることになるかもしれない。そうした社会では、生産性が非常に上がり、労働時間が短くなるために、人間の「生き方」や「尊厳」、多様な価値観がますます重要視されるようになるのではないだろうか。』
人工知能と軍事
●人工知能の応用を考える際に、忘れてはならないのが軍事面での応用である。米国では長い間、DARPA(米国国防高等研究計画局)が主導的役割を担ってきた。理由は利益につながる必要性がないからである。インターネットの起源となったARPANETもDARPAの予算で支援された。
●戦闘において、無人操縦機やロボットは人命と戦闘能力の両面において大きな価値をもたらす。
人工知能技術を独占される怖さ
●人工知能は、今後、ビッグデータに続いて産業競争力の大きな柱になっていくと思われる。そのため、技術の独占は大きな問題である。人工知能は「知能のOS(オペレーティングシステム)」と言えるかもしれない。汎用的な特徴表現学習が土台にあって、その上に、さまざまな機能を実現するアプリケーションが載っているイメージである。
※メタ・プラットフォーム社が開発しているLLMであるLlama3はオープンソースにする計画のようです。
※NVIDIAからのニュースレターの記事の中に“GPT-J6B”というものを見つけ、「これは何?」と調べたところ、これは、「2021 年に EleutherAI によって開発されたオープンソースの大規模言語モデルである」ということが分かりました。以下がそのサイトです。(大変驚きました)

EleutherAI は最先端の AI 研究に参加して議論することに関心のある AI 研究者、エンジニア、愛好家のグローバル コミュニティだそうです。
偉大な先人に感謝を込めて
●『ディープラーニングという「特徴表現学習」が人工知能における大きな山を越えたとすれば、この先、人工知能に大きな発展が待っていてもおかしくない。さまざまな産業で大きな変革を起すのかもしれない。長期的には、産業構造のあり方、人間の生産性という概念も大きく変えるのかもしれない。一方で、「冷静に見たときの期待値」、つまり宝くじを買って平均的に返ってくる金額について、どうとらえただろうか。
どんなに人工知能の可能性を低く見積もったとしても、最低限、多くの産業でビッグデータ化は進むだろう。そして、そこにいままで人工知能が担ってきた探索や推論、知識表現、機械学習の技術が活きるはずである。少なくとも、いくつかの分野では、これまでの専門家を超えるような人工知能の使い方が出てくるだろう。
この2つの可能性を考えたとき、この宝くじは決して悪いものではないと思う。人工知能の未来、人工知能がつくり出す新しい社会に賭けてもいいと思わないだろうか。
人工知能は人間を超えるのか。答えはイエスだ。「特徴表現学習」により、多くの分野で人間を超えるかもしれない。そうでなくても、限られた範囲では人間を超え、その範囲はますます広がっていくだろう。そして、これを生かすも殺すも、社会全体を構成するわれわれ自身の意思次第だ。』
ご参考:AIとCloud
AIがどこに入っていくのかを考えると、その可能性はコンピュータが活躍している全てのエリアだと思います。しかし、最初に先頭グループで引っ張るランナーは、体力の優れた(巨額の投資をできる大きな会社)会社です。
“マグニフィセント・セブン”とは、アルファベット(Googleの持株会社)、アップル、メタ・プラットフォームズ、アマゾン・ドット・コム、マイクロソフト、テスラ、エヌビディアの7つの会社のことですが、現在はこの7社がAIを広めていくリーダーとなっています。
アマゾン(AWS)、マイクロソフト(Azure)、アルファベット(Google Cloud)の各社はそれぞれ独自に展開するクラウドサービスに力を注いでいます。一方、メタはSNSからの展開です。テスラは自動運転とロボット、エヌビディアはAIの推進エンジンともいうべきGPUと開発環境のプラットフォームなどを提供しています。


画像出展:「世界時価総額ランキング(STARTUPS JOURNAL)」
1989年11位だったトヨタは2024年のリストを見ると39位となっています。衝撃的なのは1989年の時は、Top30社のほぼ半数の14社は日本の企業でしたが、2024年のリストではTop30社の22社が米国で、中国が2社、サウジアラビア、台湾、デンマーク、フランス、韓国、スイスの6カ国がそれぞれ1社ずつとなっています。この約30年他国に比べ、日本は生産性の改善に目覚ましい成果がみられていません。
某テレビ番組の中で評論家の方が、日本では経営者が次の経営者にバトンを渡し、会長さらには相談役として残る。バトンを渡された新しい経営者は忖度で身動きできない。現状維持が優先されチャレンジすることはままならず、”設備”にも“人”にも積極的な投資がされることはなく、ひたすら内部留保を増やしてきた。というようなお話をされていました。これは、少し大げさかもしれませんが、日本における企業内民主主義の問題ではないかと思います。
そして、AIによる革新を引っ張っていく一つの大きな選択肢がクラウドだと思います。

画像出展:「2022年のクラウド支出の割合と成長率:国別比較(Gartner)」
少し古いデータですが、クラウドの成長率が15%~35%となっているのと、IT支出は全体の5%~15%程であることが分かります。ここから、パブリッククラウドのポテンシャル(余地も大きく関心も大きい)の大きさを認識できます。
Google Cloudの事例

サイトの中頃にあります。動画はいずれも2~3分です。
■トヨタ自動車
・Aプラットフォーム(検査等)を構築した。
・本当に人がやらなければならないことはどこかを追及していく。
■セブン・イレブン・ジャパン
・デジタルデータ基盤を構築した。
・重要だったのはパフォーマンスだった(BigQuery)。
■アサヒグループ
・ITのモダナイゼーションを推進している。
・スピードや変化への追随が重要である。
パブリッククラウドとオンプレミス

画像出展:「DELL」
このDELLの「クラウドとグラウンド(オンプレミス)の相方向連携」という発想は素晴らしいと思います。
オンプレミスとは自社でシステムを保有し運用するシステムです。AIはオンプレミスの需要も拡大するとされています。
感想
松尾先生の『人工知能は人間を超えるか』を勉強させて頂き、AIはITの進歩の歴史の線上に存在しているもので、ハードウェア、ソフトウェア、ネットワークといったコアの技術の発展を背景にして一つの壁が破られ、ディープラーニングが登場したということだと思います。そして、人間とコンピュータの関係性が新しい次元に入ろうとしているように感じます。
ではどのように広がっていくのかと考えたときに、頭に浮かんだのは先にご紹介させて頂いた、“マグニフィセント・セブン”というITの超巨大企業のリーダーシップです。これは一言でいえば資金力と人材力に尽きます。
そして、大きな入口となるのが繰り返しになりますが、パブリッククラウドの活用ではないかと思います。また、各企業間の競争も後押しする要因だと思います。つまりAIによって各会社は事業の生産性を向上させることが可能になるため、新しい技術であるAI、そして入口としてのクラウドに期待する会社は増えるのではないかと思います。さらに、ネットの記事をみるとAIの導入は従来型のオンプレミス(自社システム)においても増えるという見方もあるようです。
一方、課題としては特にクラウドの御三家はAIへの多額な設備投資に対する利益の回収の不透明さを指摘されています。この高いハードルを超えることができるかどうかによって、AIの発展のスピードは大きく左右されるだろうと思います。
ネットには『金融業界で活用される生成AI:JPモルガンの事例から学ぶ』という記事がありました。
AIは単なる道具ではなく、本格的導入には以下の点が重要ということだと思います。
●経営層がAIの重要性を認識し、明確なビジョンを持つこと
●AIに関する専門知識を持つ人材を確保・育成すること
●AIを活用するための組織体制を整備すること
●業務効率化と新たな価値創造の両面でAIの活用を推進すること
●AIの倫理的な活用について検討し、適切なガバナンスを確立すること
これを見ると、AIはリエンジニアリング(構造改革)のための武器ではないかと思いました。

画像出展:「高まる期待のなか、業務への AI 活用はまだ始まったばかり」
AIは企業にとっては、リエンジニアリング(構造改革)を推進するようなものなので、普及のスピードは市場への影響が大きい大企業のCEO(例えばJPモルガンのジェイミー・ダイモンように)がどこまで本気に向き合い、抜本的な生産性向上を狙って導入していくかが一つの鍵になるように思います。
追記(2024年9月27日):AI検索 Perplexity
何となくAI(ChatGTPなど)を使うことにためらいがあったのですが、とあるウェビナーでAIを積極的に使いこなしている先生から「AIはまさに秘書です」、「一度使ったら元に戻れない」という発言がありました。また、数あるAIツールの特長も紹介して頂いたのですが、個人的に最も関心を持ったのは“AIを利用した検索ツール”で、それはPerplexityというものでした。下に貼り付けたスクリーンショットは、Perplexityへの質問(上)と回答(下)です。
「経絡とは何ですか?」という質問をPerplexityと最も有名なAIツールで比較しましたが、情報量とレスポンスは明らかにPerplexityの方が優れていました。


一度使ってみて、「これは元に戻れない」と実感しました。今まで検索結果からサイトに入り、さらに少し違った角度からの検索を行い情報を集め、自分なりの理解や納得を得ていたのですが、このような作業にかかる時間は圧倒的に省力化できると確信しました。つまり、同じレベルの理解であればより少ない時間で、同じ時間を要するならばより深い理解を得ることが可能です。
なお、専門性の高い質問や図や表の作成には【Pro】($20/月)に申し込む必要がありますが、無償の範囲でも十分に役立つと思います。
ディープラーニング1
AIに関しては少々勉強してきたのですが、今までの歩みや日本での取り組みなど、もう少し知りたいと思って見つけたのが松尾 豊先生の本でした。この本は2015年なのでほぼ10年前のものですが、松尾先生はAIの第一人者であり、本書の評価も極めて高いものでした。
第1章、4章、5章については少々触れていますが、ブログのほとんどは第6章と終章になります。AIに対する理解度はまだまだ低いのですが、確実に一歩前進できたのは良かったなと思います。

著者:松尾豊
発光:2015年3月
出版:(株)KADOKAWA
本書には「特徴表現学習」という言葉があるのですが、これは「ディープラーニング」のことです。このディープラーニングについては、ITmediaさまのサイトに詳しい解説がされていました。

画像出展:「5分で分かるディープラーニング(DL)」
『AI研究においてディープラーニングという革新が2006年に起こりました。ディープラーニング(以下では短く「深層学習」と表記)とは、ニューラルネットワークというネットワーク構造を持つ仕組みを発展させたものです。
深層学習の特長は、大量のデータから特定の問題を解く方法を学習することです。これは例えば子供に犬や猫を覚えさせるのと同じようなものをイメージするとよいでしょう。人間が経験から学ぶように、機械がデータから学習することを機械学習と呼びますが、深層学習はその機械学習の一種です。』
目次
はじめに 人工知能の春
序章 広がる人工知能―人工知能は人類を滅ぼすか
第1章 人工知能とは何か―専門家と世間の認識のズレ
第2章 「推論」と「探索」の時代―第1次AIブーム
第3章 「知識」を入れると賢くなる―第2次AIブーム
第4章 「機械学習」の静かな広がり―第3次AIブーム①
第5章 静寂を破る「ディープラーニング」―第3次AIブーム②
第6章 人工知能は人間を超えるか―ディープラーニングの先にあるもの
終章 変わりゆく世界―産業・社会への影響と戦略
おわりに まだ見ぬ人工知能に思いを馳せて
第1章 人工知能とは何か―専門家と世間の認識のズレ
基本テーゼ:人工知能は「できないわけがない」
●『人間の脳の中には多数の神経細胞があって、そこを電気信号が行き来している。脳の神経細胞の中にシナプスという部分があって、電圧が一定以上になれば、神経伝達物質が放出され、それが次の神経細胞に伝わると電気信号が伝わる。つまり、脳はどう見ても電気回路なのである。脳は電気回路を電気が行き交うことによって働く。そして学習をすると、この電気回路が少し変化する。
電気回路というのは、コンピュータに内蔵されているCPU(中央演算処理装置)に代表されるように、通常は何らかの計算を行うものである。パソコンのソフトも、ウェブサイトも、スマートフォンのアプリも、すべてプログラムでできていて、CPUを使って実行され、最終的に電気回路を流れる信号によって計算される。人間の脳の働きもこれとまったく同じである。
人間の思考が、もし何らかの「計算」なのだとしたら、それをコンピュータで実現できないわけがない。このことは特段、飛躍した論理ではなく、序章でも少し触れたアラン・チューリング氏という有名な科学者は、計算可能なことは、すべてコンピュータで実現できることを示した。「チューリングマシン」という概念である。すごく長いテープと、それに書き込む装置、読み出す装置さえあれば、すべてのプログラムは実行可能だというのである。』

画像出展:「パーソルクロステクノロジー」
『チューリングマシンとは、1936年にアラン・チューリングが発表した論文の中で「計算する」ことを定義した仮想的な計算機です。構造は単純で、この計算機で計算をして、機械がデータを出力できるならば計算できる、データの出力が不可能ならば計算できないと定義されています。』
第4章 「機械学習」の静かな広がり―第3次AIブーム①
機械学習における難問
●ウェブやビッグデータで広く使われている機械学習は、未知のものに対して判断・識別、そして予測することができる。しかし、弱点はフィーチャーエンジニアリング(Feature engineering)である。つまり、特徴量(あるいは素性という)の設計であり、ここでは「特徴量設計」と呼ぶ。特徴量とは機械学習の入力に使う変数のことで、その値が対象の特徴を定量的に表す。この特徴量に何を選ぶかで予測精度が大きく変化してしまう。例えば、年収を予測する問題を考えれば分かりやすい。どこに住んでいるか、男性か女性か、といった特徴量から年収を予測するというのは、ニューラルネットワークやその他の機械学習の方法を使って学習することができる。“性別”、“住所”、“年齢”、“趣味”等々、これらの特徴量から何を選ぶかということが予測精度を左右する。
第5章 静寂を破る「ディープラーニング」―第3次AIブーム②
ディープラーニングが新時代を切り開く
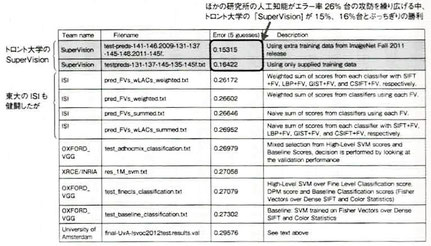
●2012年、人工知能研究に衝撃が走った。世界的な画像認識のコンペティション「ILSVRC(Imagenet Large Scale Visual Recognition Challenge)」で、初参加のトロント大学が開発したSuperVisionが圧倒的な勝利を飾った。このコンペでは画像がヨットなのか、花なのか、動物なのか、ネコなのかをコンピュータが自動で当てる問題が出題され、その正解率の高さ(実際はエラー率の低さ)を競い合う。1000万枚の画像データから機械学習で学習し、15万枚の画像を使ってテストする。
●従来はエラー率26%台の攻防だったが、SuperVisionだけが15%、16%と傑出したエラー率だった。そして、この新しい機械学習の方法が「ディープラーニング(深層学習)」だった。
画像出展:「人工知能は人間を超えるか」
●ディープラーニングの研究は約6年まえの2006年頃から始まった。ディープラーニングの凄さはデータを元に、人間ではなくコンピュータ自身が高次の特徴量を作り出し、それにより画像を分類することである。このディープラーニングによって人間の介在を必要としない人工知能の世界に踏み込むことができた。
●ディープラーニングは「人工知能研究における50年来のブレークスルー」とされている。それ以前は黎明期と「マイナーチェンジ」といえる。なお、ディープラーニングは「表現学習」の一つとされているが、本書では「特徴表現学習」という呼び方をする。
自己符号化器で入力と出力を同じにする
●ディープラーニングが従来の機械学習と大きく異なる点は2つある。1つは階層ごとに学習していく点、もう1つは自己符号化器(オートエンコーダ)という「情報圧縮器」を用いることである。

『オートエンコーダは、AI技術をサポートするニューラルネットワークの1つとして重要な役割を担っています。従来のニューラルネットワークにおける勾配消失[ニューラルネットワークの層が多すぎると逆に精度が落ちてしまうこと]や過学習[訓練データを完全に記憶してしまうことで学習データだけに最適する状態が生まれ、その結果、汎用性が失われる]といった課題を解消するために開発されたものの、現在はデータ生成や異常検知といった用途でも利用されており、さらなるニーズの拡大が見込まれます。』
第6章 人工知能は人間を超えるか―ディープラーニングの先にあるもの
ディープラーニングからの技術進展
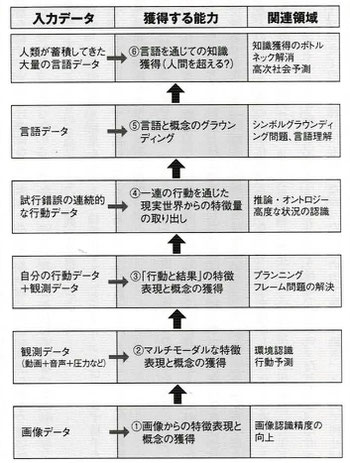
画像出展:「人工知能は人間を超えるか」
この図のタイトルは「ディープラーニングの先の研究」です。中央の“獲得する能力”は下から①~⑥となっています。
①画像特徴の抽象化ができるAI⇒②マルチモーダルな抽象化ができるAI
・人間は視覚、聴覚、触覚などそれぞれ独自の機能を持っており、作り出させる情報も異なる。脳はこれらの異なる情報を同じ処理機構で処理をする。ディープラーニングも脳と同様なことが可能であるが、時間に対応する必要がある。これは画像で言えば「動画」である。動画は時間をまたがる大局的な分脈を伝えることができる。触覚も圧力センサーの時系列の変化であり、時間をまたがるものである。
・マルチモーダルとは複数の感覚のデータの組み合わせであり、ディープラーニングはそれを可能にする。
③行動の結果と抽象化ができるAI
・コンピュータ自らの行為とその結果を合わせて抽象化することが求められる。
・人間の脳は人間が動いて目に入った情報も、動く物によって目に入ってきた情報も区別できない。しかし人間が生きていくためにはこれでは不十分である。「自分」がドアを開けたから“人”が見えたのか、“人”の方がドアを開けたから人が見えたのか、これを区別できないと生命に危険が及ぶ可能性がある。前者は「自分が指令を出したから身体が動き、それによって目に見えるものが変化した」という情報ということである。
・人間は赤ちゃんのころから、物をつかんだり、引っ張ったり、放り投げたりする。それによって、「物を動かす」とか「物を押す」とか色々な概念を獲得していく。このように人間は自らの行動とそれによる結果をセットにすることで認識できるようになる。
・行動と結果の抽象化によって「行動の計画」が立てられるようになる。例えば部屋のルームライトを交換するために、「物置にある踏み台を持ってきて、その踏み台を使って蛍光灯を交換しよう」というような行動である。
・人間が原因と結果という因果関係で理解しようとするのは、目的を明らかにし「計画的な行動」ができるようになるためではないか。
・「押す」という動作の獲得だけでも簡単な話ではない。ロボットにそれを学習させるには、テーブルを1の力で押して動かない。2の力で押すと数ミリ動いた。3の力で押せばテーブルを動かすことができる。この1、2、3のような経験を繰り返すことにより、「物を押す」という行動を抽象化できるようになる。
④行動を通じた特徴量を獲得できるAI
・「計画的な行動」ができるようになると、続いて「行動した結果」についても抽象化が進む。
・外界との相互作用による動作概念の獲得は、新たな特徴量を取り出す上でとても重要である。
・「簡単なゲームか難しいゲームか」など、「簡単」「難しい」などの形容詞的な概念は何回か試してみないと分からない抽象的な概念である。割れやすいコップなども、押すと割れる、落とすと割れるという行動と結果のセットで分かる。「割れやすい」「割れにくい」という形容詞は、ガラスの素材や形状、厚みなどによってつかめる概念である。
・コンピュータが「行動の結果と抽象化」の学習を進めれば、ひとまとまりの動作が物事の新しい特徴を引き出すことができる。それは、例えば「考えてアッと(特徴量に)気づく」「やってみてコツが(特徴量が)わかる」というようなことである。
・いったん動作を通じて特徴量を得ることができれば、次からは見た瞬間、割れやすいから気をつけようという予測ができる。このように周囲の状況に対する認識が一段階深くなり、ロボットであっても環境に適応することが可能になる。
⑤言語理解・自動翻訳ができるAI
・コンピュータが抽象的概念を獲得すると「言語」の獲得の準備が整う。例えば、「ネコ」「ニャーと鳴く」「やわらかい」という概念が出来ていれば、それぞれの概念に「ネコ」「ニャーと鳴く」「やわらかい」という言葉(記号表記)を結び付けることで、コンピュータは言葉とその意味する概念をとセットで理解する。つまり、シンボルグラウンディング問題[AIはシンボル[記号]が実世界とどのように結びついているのかを認識できないという問題]は解消される。シマウマを1度も見たことがないコンピュータも、「シマシマのあるウマ」と聞けば、あれがシマウマだと分かるようになる。
・ここでは、概念が言葉(記号表記)と結びつけられることが重要であり、その言葉が何語なのかは問われない。
⑥知識獲得ができるAI
・コンピュータが人間の言葉を理解できるようになるということは、コンピュータの中に何らかのシミュレーターが備えられており、「人間の文章を読むと、そこに何らかの情報が再現できるようになっている」ということである。
・コンピュータが本を読めるということは、膨大なウェブにある情報も読めるということに他ならない。この段階までいけばコンピュータは物凄い勢いで人類の知識を吸収できるようになるだろう。

画像出展:「人工知能は人間を超えるか」
この図のタイトルは「人工知能研究の心象風景」です。
『今までに、AIは色々な研究が行われてきた。そこでは「特徴表現をどう獲得するか」ということが最大の関門だったが、“機械学習”と“ビッグデータ”の間に抜け道ができた。それがディープラーニングである。AIは長い停滞の時を超えて動きだした。』
人工知能は本能を持たない
●人工知能は発展しても、人間と同じように概念や思考、自我や欲望を持つわけではない。
●人間には紫外線も赤外線も見えず、聞き取ることができない高音や低音、小さすぎたり動きが速すぎたりして見えない物体、匂いも犬に比べるとその能力は明らかに劣っている。そうした情報をコンピュータが取り込むと、そこから生まれてくるものは人間の知らない世界である。そのようにしてできた人工知能とは「人間の知能」とは別のものになるだろうが、間違いなく「知能」といえる。
●人間は言葉を話す。言葉には文法があるが、人間は生得的な文法(普遍文法)を備えていると考えられている。その生得的な方法を人工知能に埋め込む必要があると思われる。
●言語とともに重要なのが「本能」である。本能といっても脳に関することであり、「快」と「不快」を感じる能力である。個々の人間が持つ興味は千差万別である。楽しいことには時間は足りず、つまらないことは時間が長く、苦痛である。こうしたことは人工知能の分野では「強化学習」として知られている。何か報酬が与えられてその結果を生み出した行動が「強化」されるという仕組みである。そして、この強化学習の際に重要なのは、何が報酬か、つまり何が「快」で何が「不快」なのかである。
●人間は生物であるため、生存(あるいは種の保存)に有利な行動は「快」、生存のリスクとなるような行動は「不快」となるようにできている。食べること、眠ることは「快」、空腹や身の危険を感じることは「不快」である。こうした本能に直結するような概念をコンピュータが獲得することは難しい。それは「きれい」という概念は、おそらく長い進化の中で作り上げられた本能と密接に関係していると考えられるためである。
●「人間と同じ身体」「文法」「本能」などの問題を解決できないと、人工知能が人間の概念を正しく理解することは困難かもしれない。もっとも、「人間とそっくりな概念」を必要とするロボットの必要性は高くない。それよりも、予測能力が高い人工知能が出現するインパクトの方が大きいと思われる。
コンピュータは創造性を持てるか
●創造性には個人の中で日常的に起こっている創造性と社会的な創造性の2つがある。
●概念や特徴量の獲得とは創造性そのものである。あることに「気づく」のは創造的な行為である。一方、社会的な創造性は今までにない新しいものであるという前提が必要になる。そのため、社会的に創造的なものは少ない。
●人間は試行錯誤によって創造する。人工知能が「行動を通じた特徴量を獲得できるAI」の段階に達すれば、思考錯誤は可能なので創造性の獲得は期待できると考えられる。
知能の社会的意義
●人間社会はひとりでは生きていけない。このことについて人工知能はどう考えるべきものか。人間社会がやっていることは、現実世界の物事の特徴量や概念をとらえる作業を、社会の中で生きる人たち全員が、お互いのコミュニケーションをとることによって、共同して行っていると考えることもできる。そしてそうして得た世界に関する本質的な抽象化をたくみに利用することによって、種としての人類が生き残る確率を上げている。つまり、人間という種全体がやっていることも、個体がやっているものごとの抽象化も、統一的な視点でとらえることができるかもしれない。「世界から特徴量を発見し、それを生存に活かす」ということである。
シンギュラリティは本当に起きるのか
●人工知能はどこまで進化するのか。懸念は人工知能が自分の意思を持って自立し、自分自身を設計し直すことができるようになると、人類を超えたものになるということである。
●シンギュラリティは人工知能、遺伝子工学、ナノテクノロジーという3つが組み合わされることで、「生命と融合した人工知能」が実現するという立場である。また、シンギュラリティは人工知能が自分の能力を超える人工知能を自ら生み出せるようになる時点を指す。自ら超えるプロセスを無限に繰り返すことで、圧倒的な知能が誕生するというものである。
人工知能が人間を征服するとしたら
●人工知能が人類を征服したり、人工知能を作りだしたりするというのは夢物語である。
●『ディープラーニングで起こりつつあることは、「世界の特徴量を見つけ特徴表現を学習する」ことであり、これ自体は予測能力を上げるうえできわめて重要である。ところが、このことと、人工知能が自ら意思を持ったり、人工知能を設計し直したりすることとは、天と地ほど距離が離れている。
その理由を簡単に言うと、「人間=知能+生命」であるからだ。知能をつくることができたとしても、生命をつくることは非常に難しい。いまだかつて、人類が新たな生命をつくったことがあるだろうか。仮に生命をつくることができるとして、それが人類よりも知能の高い人工知能に「生命」を与えることは可能だろうか。
自らを維持し、複製できるような生命ができて初めて、自らを保存したいという欲求、自らの複製を増やしたいという欲求が出てくる。それが「征服したい」というような意思につながる。生命の話を抜きにして、人工知能が勝手に意思を持ち始めるかもと危惧するのは滑稽である。』
万人のための人工知能
●人工知能学会は2014年に倫理委員会を立ち上げ、人工知能が社会にもたらすインパクトについて議論を進めている。

こちらは「人工知能学会倫理委員会」のサイトです。初代委員長の松尾先生は2018年6月までの任期だったようです。
『人工知能学会倫理委員会では、2014年の委員会設置以来、人工知能研究あるいは人工知能技術と社会との関わりを広く捉え、それを議論し考察し、社会に適切に発信していくことを進めてまいりました。我が国でも、さまざまな政府機関で人工知能と社会に関する議論が行われ、また国際的にもそうした議論が進められるなか、人工知能学会としても深い専門知識に基いて、国内の議論をリードしていく役割があると考えています。』
GPUを支える技術3

第6章 GPUの周辺技術
6.2 CPUとGPU間のデータ転送
・高性能のGPUでゲームをプレイする場合などは描画のために大量のデータをGPUに送り込む必要があるため、CPUとGPUの間のデータ転送速度が非常に重要である。
●NVIDIAのNVLink
・NVIDIAが開発した伝送チャネルで、伝送速度は20Gbit/sでPCI Express3.0の2.5倍の速度である。
●NVIDIA NVSwitch
・NVIDIAが2018年に開発した18ポートのクロスバースイッチで、16台のV100 GPUを相互接続できる。これにより16個のV100 GPUのデバイスメモリが連続した512GBの大きなメモリ空間になるため、どのアドレスでもアクセスしてRead/Writeできる。これによりGPU間でデータコピーする必要がなく処理の分散が容易になる。
第7章 GPU活用の最前線
7.1 ディープラーニングとGPU
・ディープラーニングの計算処理の大部分はGPUが得意な行列の積の計算である。
・NVIDIAは自動運転用のGPUを内蔵したSoCを製品化している。
・自動運転、車の自動化にはAI用のGPUが搭載される可能性がある。
・画像認識はロボットや自動運転車の眼として重要な技術で、従来は画像認識の専門家がシステムを作っていたが、2012年にディープラーニングを使ったシステムが従来のシステムを大幅に上回る成績を達成したことから、画像認識の研究はディープラーニング中心になった。
・認識精度の向上につれて、ニューラルネットワークの規模も拡大されてきている。2020年のOpenAIの自然言語処理システムGPT-3では175B(175兆個)パラメータという巨大モデルが出現している。(GTP-4のリリースは2023年7月、GTP-4 Turboは2023年11月)
●ディープラーニングで使われるニューラルネットワーク
ネットには多くのサイトや動画がありましたが、特にいいなと思ったサイトをご紹介させて頂きます。


『本記事では、膨大なデータを分析・解析を行うためにAIの導入を検討している人向けに、ニューラルネットワークの仕組みや関連用語などを中心に解説します。また、活用事例も紹介するので、今後のAI導入の参考にしてください。』

”ニューラルネットワークとは?仕組みや歴史からAIとの関連性も解説”
『この記事では、ニューラルネットワークの基礎知識から代表的な種類、変遷の歴史まで解説します。AI技術やディープラーニングとの関係についてもわかりやすく説明しますので、AIサービスの研究や開発を検討する際にぜひ参考にしてください。』

”AIビジネスを考える上で押さえておきたい、ニューラルネットワークの実用例30選”
『人工知能分野のニューラルネットワークは、人間の神経回路の仕組みをまねる、機械学習の一手法です。 さまざまな分野でのビジネス利用が活発になり、大きな成果をあげる実例も出ています。』

”大規模言語モデル(LLM)とは? 仕組みや種類・用途など”
『近年ではさまざまな生成AIが登場していますが、そのなかでも注目を集めているものが「大規模言語モデル(LLM)」を活用したものです。以前からコンピューターと対話する形のAIは存在していましたが、大規模言語モデルの登場により、その精度は格段に向上しました。従来の言語モデルと比べて大規模言語モデルはどのような特徴を持つのでしょうか。』
●ディープラーニングで必要な計算とGPU
・推論やディープラーニングの学習も大量の行列と行列の積の計算が必要なので、GPUであればCPUよりはるかに高い処理性能が期待できる。
・ディープラーニングの推論は、16ビットの半精度浮動小数点、あるいは値を適切に量子化すれば、8ビットの固定小数点で計算してもほとんど推論結果には影響がない。
●ディープラーニングでのGPUの活用例
・画像認識は多くの分野で利用が始まっている
-ドローンの眼として画像認識の必要性が高まっており、低電力のGPUのシステムが開発されている。
-セキュリティ用の監視カメラに対し、状況の危険度の判定や通報、不審者の顔認識をすることで大幅に機能を高めることができる。
-医療画像の読影はディープラーニングにより、細かい病変の発見に貢献できる。ただし、医療機器としての活用には大量の事例による有効性の検証が必須である。
・NVIDIAは自動運転に向けたSoCに注力
-自動運転には画像認識が重要であるが、大量の計算が必要である。
-NVIDIAは自動運転を次世代のビジネスの柱として、2019年にDrive AGXOrinを発表した。
-NVIDIAは2000TOPS(Tera Operations Per Second)のコンピュータではレベル5のロボタクシーの実用化を目指している。
-NVIDIAは、AIスパコンを自社に設置し、いろいろな天候や周囲の明るさのシナリオを生成したり、実際には存在していない色々な障害物(子供の飛び出しや、前の車の落とし物など)をシナリオに加えたりして、自動運転システムを学習させてAIの品質改善を続けている。

画像出展:「GPUを支える技術」
7.2 3DグラフィックスとGPU
●VR、ARの産業利用
・VRはVirtual Reality、ARはAugmented Realityである。
●NVIDIAのGRID
・NVIDIAは中央のサーバと仮想化された端末で、各端末のGPUを搭載することなく快適なグラフィックススピードを提供できるNVIDIA GRIDというシステムを提供している。

”仮想デスクトップのグラフィックス処理を高速化「NVIDIA GRID」”
こちらの記事はアセンテック(株)さまからです。
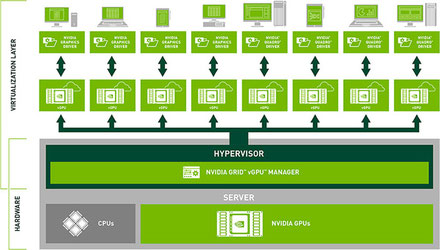
図はNVIDIA GRIDのシステム構成図です。
また、同ページにに”動画:NVIDIA GRID CPU と vGPU の対照比較 ”がありました。(1分19秒)
タイトルは「NVIDIA GRID vGPU vs. CPU Only - Siemens NX Horizon View with VMware Horizon & vSphere」です。
●物理的に複数ユーザーにGPUを分割するMIG
・MIG(Multi Instance GPU)はAmpere A100に付加された機能で、7個のGPUを個別のユーザーに割り当てるもので、他のユーザーの影響をほとんど受けない独立性の高い分割使用環境を実現する。
7.4 スーパーコンピュータとGPU
●世界の上位15位までのスーパーコンピュータの状況
・スーパーコンピュータの世界には、TOP500という性能ランキングがある。
・GPUの課題はプログラミングが難しいことがある。

『TOP500 プロジェクトは、7 年間使用されていたマンハイム スーパーコンピュータの統計を改善および更新するために 1993 年に開始されました。
当社のシンプルな TOP500 アプローチでは、「スーパーコンピューター」そのものを定義しませんが、ベンチマークを使用してシステムをランク付けし、TOP500 リストに入る資格があるかどうかを決定します。 』

こちらの記事は「ITmedia」さまより拝借しました。

『同社が独自に開発したデータセンター規模のスーパーコンピュータ「Eos」をブログと動画で披露しました。 』
写真をクリック頂くと、動画“Eos: The Supercomputer Powering NVIDIA AI's Breakthroughs”がご覧頂けます。(2分8秒)
第8章 ディープラーニングの台頭とGPUの進化
8.2 各社のAIアクセラレータ
●GoogleのTPU
・Googleはデータセンターの負荷が2倍になった場合、それをCPUの増設で対応するのは高コストのため、ディープラーニングの計算を効率的に行うことができるハードウェアの開発に着手した。
・Googleは学習時間を短縮するため、多数のTPU(Tensor[線形的な量または線形的な幾何概念を一般化したもの] Processing Unit)をネットワークで接続したマルチTPUのディープラーニング用のスーパーコンピュータを作ることになった。

画像出展:「GPUを支える技術」
右端が演算回路部分で、重みを供給する重みFIFO(First In First Out) 、行列積を計算するマトリクス乗算ユニットMXU(Matrix Multiply Unit)がある。
●NVIDIAのTensorコア
・計算回数に比べメモリアクセス回数が少なく、メモリアクセスがボトルネックにならず演算性能を出しやすい。

『NVIDIA A100 Tensor コア GPU は、あらゆる規模で前例のない高速化を実現し、AI、データ分析、および HPC 向けの世界で最も性能能力の高いエラスティック データ センターを強化します。』
●Habana LabsのGoyaとGaudi
・Habana LabsはイスラエルのAIチップメーカーだが、2019年12月にIntelに買収された。
・Goyaはデータセンター向けの推論アクセラレータ、Gaudiはデータセンター向けの学習アクセラレータである。
8.3 ディープラーニング/マシンラーニングのベンチマーク
●MLPerfベンチマーク
・MLPerfはディープラーニングの実行性能を測るベンチマークである。

『学界、研究機関、業界の AI リーダーたちによるコンソーシアムである MLCommons によって開発された MLPerf™ ベンチマークは、ハードウェア、ソフトウェア、サービスの学習と推論の性能を公平な評価を提供するように設計されています。』

“NVIDIA、MLPerf ベンチマークで生成 AI トレーニングを飛躍的に加速”
『10,752 基の NVIDIA H100 Tensor コア GPU と NVIDIA Quantum-2 InfiniBand ネットワーキングを搭載した AI スーパーコンピューターである NVIDIA Eos は、1,750 億のパラメーターを持つ GPT-3 モデルを10 億のトークンでトレーニングするベンチマークを、わずか 3.9 分で完了しました。』
8.4 エクサスパコンとNVIDIA、Intel、AMDの新世代GPU
●NVIDIAのAmpere A100 GPU
・GoogleのTPUはディープラーニングの学習と推論計算を効率よく実行する専用チップだが、NVIDIAのA100 GPUはグラフィックスや科学技術計算、データ解析、クラウドゲーミング、遺伝子解析などさまざまな用途のアクセラレータとして使えるように設計されている。

画像出展:「GPUを支える技術」
●Intelは新アーキテクチャのXe GPUを投入
・グラフィックスの世界はNVIDIAとAMDの独占状態だったが、グラフィックスだけでなく科学技術計算やディープラーニングの分野でも広く使われるようになってきて、Intelの牙城であるデータセンターをNVIDIAやAMDのGPUが侵食してきている。
●AMDは新アーキテクチャCDNA GPU開発へ
・AMDは2020年11月に大規模科学技術計算やディープラーニング計算をターゲットとするCDNAアーキテクチャを発表し、Instinct MI100 GPUを発表した。
8.5 今後のLSI、CPUはどうなっていくのか?
●微細化と高性能化
・現状で微細なパターン描画の最大の障害は光の波長である。
・EUV波長で乱れのない凹面反射鏡のレンズは特殊技術が必要で、ドイツのZEISS(ツァイス)は作ることができる。そして、このレンズを使うEUVの露光機を作れる会社はオランダのASMLである。
・微細化はスローダウンしながらも進歩している。しかし、厚みは薄くても高い電圧に耐える絶縁膜材料を探すというアプローチは原理的には可能だが、加工法などを含めて代替になる新材料の開発には長い時間が掛かるため、険しい道と考えられている。

『EUV露光は、7nm以降の微細回路パターンをシリコンウェーハ上に転写(露光)するための技術として、2019年に台湾のTSMCによって初めて量産投入された技術である。』
●チップレットと3次元実装
・業界で期待されているのは3次元実装である。なかでも一番実用化が進んでいるのがHBM(High Bandwidth Memory)である。
“「HBM(High Bandwidth Memory)」とは”
“NVIDIA、HBM3eメモリ採用の次世代GH200を発表”
●CPUはどうなっていくのか
・CPUは量的にはスマートフォンなどのSoCに使われるのが大部分である。また、IoTも主要なCPUユーザーになっていくと考えられる。一方、売り上げや利益の面では、クラウドサービスを提供する大規模データセンターがCPUの主要なユーザーである。従って、この2つの分野に向けてCPU開発が行われていくと考えられる。一方、ArmアーキテクチャのCPUをデータセンターに使おうという動きもある。その代表がAmazonのAWS Graviton CPUである。AmazonはArmのNeoverseアーキテクチャのデータセンター用のCPUを自社で開発し、使用している。
・Armアーキテクチャはサーバ市場における普及の入り口に立っているかもしれない。
8.7 まとめ
・重要なことはCPUとGPUは適材適所で仕事を分担することである。微細化はかなり進んできており、微細化だけで約10倍のトランジスタが使えるようになると予想されている。さらに3次元実装を組み合わせれば、さらに10倍以上はいけるので、CPU、GPUには大きな進化の余地は残っている。一方、大きな問題は発熱で、これには消費電力を減らすことが最も重要になる。そのために、半導体技術、回路設計技術、論理設計技術、アーキテクチャの各分野で努力が続けられている。
・GPUメーカーは並列プログラミングとCPU-GPU分離メモリから生じるプログラミングの難しさの軽減にも取り組んでいる。そして、GPUの使用分野の拡大にも力を入れており、ますます私たちの生活の中に入り込んできている。
・『本書では、GPUとはどのようなものなのか、なぜ計算性能がCPUより格段に高いのか、GPUのプログラミングはどのようにするのか、さらにニューラルネットワークの計算はどのように行われるのかなどの基本事項とともに、最新の話題や将来の見通しを含めてGPUについて解説しました。』
感想
第1章に「文字だけでなく図が加わると、情報の伝達が飛躍的に容易になる」ということが書かれており、「これだ!」と思いました。
例えば、営業でプレゼンテーションを行う場合、文字だけでなく図や表、あるいはイラストや動画などを使って効果的に説明します。また、理解する側の立場にたっても、特に目新しいことについては、文字情報だけでは理解が難しいということが多々あります。ブログの冒頭にご紹介した設計システムのCADも、2次元の製図より3次元の立体モデルの方が、デザイン、設計、製造など開発・生産の各工程に関わる人の理解を助けます。
人の気持ちを理解する場合、特に隠れた「気持ち」は微妙に表情に出ることが多く、言葉に加え目からもたらされる視覚情報は、その人の気持ちや考えを深く理解する上で、非常に役に立ちます。これらは“非言語コミュニケーション” と言われています。
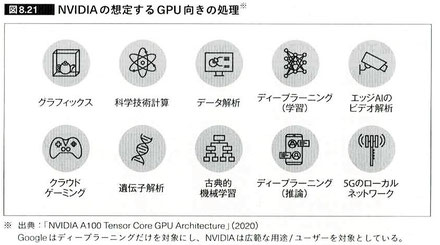
画像出展:「GPUを支える技術」
上記はNVIDIAの資料で、GPUの主な用途が紹介されています。これらのコンピューティングには文字だけでなく、画像や映像の情報処理が強く求められます。
個人的には、AIはニューラルネットワ-クという新しいコンピュータ言語によるITの革新のように思っていましたが、それに加えて、非言語コミュニケ-ションのコンピュータ化という側面もあるように感じました。
ご参考:【GTC】2024年3月18日-21日
NVIDIAが3月18日から21日までの4日間、カリフォルニア州サンノゼの サンノゼ マッケンナリー コンベンション センターでカンファレンスを行いました。興味があったので登録してみたところ、毎日メールが届き、以下のようなサイトに案内されました。

“GTC March 2024 Keynote with NVIDIA CEO Jensen Huang”
まさに『産業の米、AIの米』だと思いました。クラウドAIからエッジAI、そして、開発支援、トレーニング(学習)など、AIの全てを網羅しているという感じです。
※医療(Healthcare):“Healthcare Reimagined with Artifi” 1分35秒
※ロボット:“NVIDIA Robotics: A Journey From AVs to Humanoids” 3分42秒
※自動運転:”NVIDIA AI Tools for Autonomous Vehicle Developers” 2分23秒
※3D共同開発プラットフォーム:“NVIDIA Omniverse Cloud APIs on Microsoft Azure” 1分36秒
※CEO ジェンスン・フアン:“Jensen Huang, Founder and CEO of NVIDIA” 56分26秒
News(2024年7月26日):“中国「無人タクシー」急増 実際に乗ってみた” (YouTube 5分47秒)

画像出展:「中国で「無人タクシー」が急増 実際に乗ってみた(FNNプライムオンライン)」
なんと、中国では既に無人タクシーの営業が始まっていました。北京、重慶、広州市など全国4カ所で営業スタート。2025年までに中国の全国で無人タクシーを導入したいとのことです。
日本では過疎化する高齢者地域の交通手段として、とても魅力的ではないかと思いました。
ご参考(2024年9月12日):GPUを取り巻く新しい動き(AIを加速させる新しい技術や取り組み等が動いています)

こちらは、週刊エコノミスト2020年2月4日号です。AIチップの動きは、ここ1、2年の動向かと思っていましたが、もっと前からの動きでした。
『最初の口火を切ったのはグーグルだ。2016年5月、エヌビディアのGPUよりも消費電力が1ケタ小さいAIチップ「TPU(テンソル・プロセッシング・ユニット)を開発し、2015年から自社のクラウドで検索エンジンに使っていたことを明らかにした。省エネの鍵となったのは、演算精度を16ビットから8ビットへ半分に落としてもAIの性能はほとんど変わらず、消費電力は1ケタ小さくなるのを見いだしたことだった。TPUはその後も改良を重ね、2018年にはクラウドでなく、端末に組み込む「エッジTPU」も発表している。TPU以降、性能に支障ない範囲でいかに演算精度を下げて消費電力を抑えるかが、開発競争の中心になっていった。』
1.AI ASICチップ: ハイテク大手のAI軍拡競争における次のフロンティア
3.ASIC市場の革新と未来: 最新トレンドと成功事例に学ぶ2024年の展望
4.密かに進化するAIチップ IT/半導体業界は半世紀に1度の大変革か?
5.AMD・Intel・Google・Microsoft・MetaなどがNVIDIA対抗のAIアクセラレータ相互接続規格の開発に向けて業界団体を設立
6.胎動する「ポストGPU」、NVIDIAのボトルネック狙う米スタートアップの最終兵器
→d-Matrix:AIを持続不可能なものから実現可能なものに変える。
GPUを支える技術2

第2章 GPUと計算処理の変遷
2.1 グラフィックとアクセラレータの歴史
・2020年11月時点では、スーパーコンピュータの性能をランキングするTOP500リストの中で、147システム(約30%)がGPUをベースとする計算アクセラレータを使っている。

画像出展:「NVIDIA」
『世界の最高峰のスーパーコンピュータは、これまでより高速になっているだけではありません。よりスマートになっており、多様なワークロードにも対応しています。SC20で発表された、世界最速のスーパーコンピュータ TOP500リストのうちおよそ70%、および上位10システムのうちの8システムでNVIDIAのテクノロジが採用されています。』
“Eos: The Supercomputer Powering NVIDIA AI's Breakthroughs” Youtube 2分7秒
2.3 GPUの科学技術計算への応用
●CUDAプログラミング環境
・GPUの性能を生かすには従来のOpenGLでは限界があった。これに対し、NVIDIAは科学技術計算プログラムを記述するCUDA言語とそのコンパイラやデバッガツールを提供した。
第3章 [基礎知識]GPUと計算処理
3.1 3Dグラフィックスの基本
・3次元(3D)のモデルを表示するプログラム言語はOpenGL(GLはGraphics Languageの意味)とDirectXが標準的に用いられている。前者は業界標準のKhronos Groupが管理している。後者はマイクロソフトがWindowsのゲームなどを買い開発するために作った規格である。
●[基礎知識]OpenGLのレンダリングパイプライン
・レンダリングとはデータを処理もしくは、演算により画像や映像として表示させることである。そして、モデルデータの入力から出力までの加工手順のことを、レンダリングパイプラインという。
ご参考:床井研究室 (和歌山大学の床井浩平先生だと思います)
この床井先生のホームページに知りたいことが書かれていました。それはグラフィック処理におけるソフトウェアとハードウェアの共同作業ということです。
レンダリングパイプライン
形状データから画像を生成する方法は、サンプリングによる方法(レイキャスティング法、レイトレーシング法)とラスタライズによる方法(デプスバッファ法、スキャンライン法など)の二つに大別されます。後者は座標変換により形状データのスクリーンへの投影像を求め、それを走査変換によりスクリーン上で画素に展開(ラスタライズ)して画像を生成します。これはおおよそ以下の手順に整理されており、レンダリングパイプラインと呼ばれています。

画像出展:「床井研究室」
『形状データから画像を生成する方法は、サンプリングによる方法 (レイキャスティング法、レイトレーシング法) とラスタライズによる方法 (デプスバッファ法、スキャンライン法など) の二つに大別されます。後者は座標変換により形状データのスクリーンへの投影像を求め、それを走査変換によりスクリーン上で画素に展開 (ラスタライズ) して画像を生成します。これはおおよそ図の手順に整理されており、レンダリングパイプラインと呼ばれています。』

画像出展:「床井研究室」
『最初、この手順はソフトウェアで実装されていました。しかし、CG というのは何らかの計算結果を画像化することが目的なので、画像化の作業にもCPUを使うことは無駄だと考えられました。そこで最初に、単純な整数計算とメモリアクセスの繰り返しである走査変換が、専用のハードウェアで実現されました。これにより画像生成の速度が劇的に向上したとともに、CPUは画像化の作業から開放され計算に専念できるようになりました。 』

画像出展:「床井研究室」
『モデリング変換や視野変換(この二つはまとめてモデルビュー変換とも呼ばれます)、および投影変換といった座標変換や、陰影計算 (shading) には、実数計算が含まれます。しかし、高速な実数計算ハードウェアはコストが高かったので、当初グラフィックスハードウェアには搭載されていませんでした (32bit CPU でも初期のものには内蔵されていませんでした)。この部分をハードウェアで実装したこと(ハードウェア T&L-Transform and Lighting) によって、リアルタイム3D CG が本格的に利用されるようになってきました。 』

画像出展:「床井研究室」
『レンダリングパイプラインの処理内容はここまであまり変化してこなかったので、ハードウェア化はレンダリングパイプラインの各段階の機能をハードウェアで実現する形で行われました(固定機能ハードウェア)。このため新しい機能が必要になるたびに、それを実現するハードウェアが追加されてきました。しかしCGの応用が広がり多様な表現が要求されるようになってくると、こうして機能を追加することが難しくなってきました。
そこで、機能を追加する可能性がある部分をプログラム可能にして、ソフトウェア的に機能を拡張できるようにすることが考えられました。それまで座標計算と(頂点の)陰影計算を担当していたハードウェアはバーテックスシェーダに置き換えられ、走査変換により選ばれた画像の各画素の色を頂点の陰影の補間値やサンプリングしたテクスチャの値を合成(マージ)して決定していたハードウェアはフラグメントシェーダに置き換えられました。また、フラグメントシェーダから光源情報や材質情報を参照することや、テクスチャをバーテックスシェーダから参照すること (vertex texture fetch) も可能になりました。』

画像出展:「床井研究室」
『さらに、それまでアプリケーションソフトウェア側で行われていた基本形状(点, 線分, 三角形)の生成の一部を、グラフィックスハードウェア側で行うことができるようにもなりました。これにより、アプリケーションソフトウェア(CPU)からグラフィックスハードウェアに送られる形状データの量を減らしながら、より高品質な形状の表現が行えるようになりました。これはジオメトリシェーダにより行われます。なお、ジオメトリシェーダの利用はオプションなので、使用しなくてもかまいません。 』
●フラグメントシェーダ
・OpenGLではフラグメント、DirectXではピクセルと呼ばれている。フラグメントシェーダはフラグメントの色と奥行き方向の位置を計算するシェーダ(陰影処理を行うプログラム)である。
・Zバッファは奥行き方向の座標(Z座標)を記憶する機構である。
・ブレンディングは半透明のための処理のことである。
・テクスチャマッピングはテクスチャを立体の表面に張り付ける手法である。
・ライティングは光の当たり具合、反射、光源である。
・フラグメントシェーディングは各ピクセルの明るさや色を計算すること。平面はフラットシェーディング、面の継ぎ目が目立たないようにしたのがグローシェーディングである。
・レイトレーシングは反射した光の光路を計算し、反射による映り込みを表現する。
3.2 グラフィック処理を行うハードウェアの構造
・OpenGLやDirectXで書かれたプログラムを高速で処理するのは、ハードウェアが必要である。IntelのPC用プロセッサであるCoreiシリーズプロセッサは、CPUチップの中にGPUコアを内蔵している。また、グラフィックスボードは画像処理に特化した計算を行うGPUを搭載している。

こちらは2012年のものなので、内容は古いのですが35年前(1989年)を起点に考えると約20年間の歩みが分かるので、私にとっては貴重な資料でした。(PDF11枚)
『3次元コンピュータグラフィックスをレンダリングするためには非常に多くの演算を必要とする。従来はCPU(Central Processing Unit)上でそれらの計算を行っており、計算コストが非常に高いという問題があった。そのために、産業分野などで3次元レンダリングが必要な場合には SGI(Silicon Graphics Interface)など、3次元演算専用のハードウェアを搭載した高価なワークステーションを用いていた。
一方、1999年8月にNVIDIAからGeForce256という、パーソナルコンピュータ(PC)向けグラフィックスボードが発表された。これは、PC上で1500万ポリゴン/秒及び4億8000万ピクセル/秒の描画速度を実現した。NVIDIAは、このようなグラフィック処理を行うハードウェアを GPU(Graphic Processing Unit)と呼ぶようになった。』
3.3 [速習]ゲームグラフィックとGPU
●PlayStationとセガサターンが呼び込んだ3Dゲームグラフィック・デモクラシー
・今ではNVIDIAとAMD(当時はATI Technologies)の二強時代だが、1990年代後半は数十社のメーカーがPC向けの独自のグラフィックスハードウェア製品をリリースしていた。なかでも一時代を築いたのが3dfx Interactiveで、Voodooシリーズと呼ばれるグラフィックスハードウェア製品は当時のPCゲームファンの間に絶大な人気を博していた。

画像出展:「GPUを支える技術」
ゲームには無縁の私でしたが、Voodoo PC
の名前は知っていました。
3.4 科学技術計算、ニューラルネットワークとGPU
●科学技術計算の対象は非常に範囲が広い
・科学技術計算の範囲は非常に広いが、それらに共通していることは解析しようとする現象の物理モデルを作り、そのモデルを使って現象がどのように変化していくかを計算で求めるという点である。
・スーパーコンピュータの「富岳」の課題は9つである(文部科学省の資料より)
1)生体分子システムの機能制御による革新的創薬基盤の構築
2)個別化/予防医療を支援する統合計算生命科学
3)地震/津波による複合災害の統合的予測システムの構築
4)観測ビッグデータを活用した気象と地球環境の予測の高度化
5)エネルギーの高効率な創出、変換/貯蔵、利用の新規基盤技術の開発
6)革新的クリーンエネルギーシステムの実用化
7)次世代の産業を支える新機能デバイス/高性能材料の創成
8)近未来型ものづくりを先導する革新的設計/製造プロセスの開発
9)宇宙の基本法則と進化の解明
●科学技術計算と浮動小数点演算
・お金の計算や在庫の計算などは整数が良いが、科学技術計算では非常に大きい数や非常に小さい数が出てくるため、浮動小数点演算が必要になる。
●ディープラーニングに最適化された低精度浮動小数点数
・ディープラーニングではニューラルネットワークが使われるが、入力信号に重みを掛けさらに全入力の信号の総和をとる方式のため、多少の誤差は問題にならない。そのため、半精度で問題ないと考えられている。現在では、NVIDIA、AMD、Intelが半精度浮動小数点演算をサポートしている。
3.5 並列計算処理
・2005年頃からCPUのクロック(周波数)は消費電力の問題から頭打ちとなり、各メーカーはプロセッサのコア数を増やして性能を上げる方向に舵を切った。
●GPUのデータ並列とスレッド並列
・並列処理にはそのためのプログラムが必要になる。
・1つの命令で複数のデータを処理する方式(SIMD)だが、GPUが使っているのはSIMT(Single Instruction, Multiple Thread)であり、各スレッドが1つの仕事を担当し、複数のスレッドを並列に実行するという方法である。
3.6 GPUの関連ハードウェア
●デバイスメモリに関する基礎知識
・標準的なGPUで4~8GB、ハイエンドのGPUで12~24GB。
●CPUとGPUの接続
・GPUではOSを動かさない。これは割り込みやセキュリティ機能の不足もあるが、1番の問題は並列処理では難しい命令を高速処理することができないためである。このため、科学技術計算の入力データなどはCPUに読んでもらう必要があり、CPUとGPUの共同作業になる。
・NVIDIAが開発したのはNVLinkとNVSwitchである。
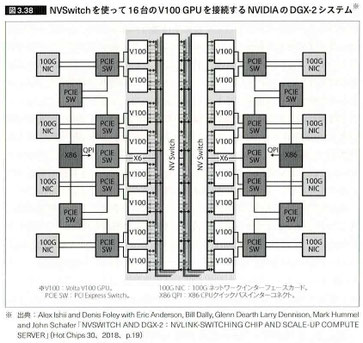
画像出展:「GPUを支える技術」
中央がNVSwitchです。
第4章 [詳説]GPUの超並列処理
・GPUはグラフィック処理を高速に実行する目的で開発されたが、その後、科学技術計算やAIのディープラーニングなどにも活用されるようになった。
4.2 GPUの構造
・GPUと300Wを消費するハイエンドGPU(NVIDIAとAMDが市場を二分する)と数Wのスマートフォン用SoCのGPUでは作りは異なる。
●NVIDIA Turing GPUの基礎知識
・NVIDIAはユニファイドシェーダ化やCUDAプログラミング言語の開発など、科学技術計算の先頭を走ってきた。さらに、ディープラーニングへのGPUの適用、自動運転車へのGPUの適用という新しい分野でも先頭を走っている。
・TuringアーキテクチャのGPUチップは「TU」が付けられ、番号は「100」が科学技術計算用の高性能チップとなっている。
●NVIDIAのTensorコア
・GoogleがTPUを自社開発し、ディープラーニング演算の性能を高めたのと時を同じくして、NVIDIAはVolta GPUの行列乗算用の演算ユニットであるTensorコアを搭載した。
4.3 AMDとArmのSIMT方式のGPU
●AMD RDNAアーキテクチャGPU
・AMDが2012年に発表したGPUはGCN(Graphics Core Next)というアーキテクチャを使ってきたが、2019年11月にRDNA(Radeon DNA)を発表し、性能/電力を50%改善したとした。
4.4 GPUの使い勝手を改善する最近の技術
●ユニファイドメモリアドレス
・ユニファイドメモリアドレスはCPUのメモリとGPUのメモリに重複しないメモリアドレスを割り当て、アドレスを見ればそれがCPUメモリかGPUかを識別できるというもの。
●NVIDIA Pascal GPUのユニファイドメモリ
・NVIDIAはPascal GPUで、ユニファイドメモリアドレスを一歩進めて、あたかもCPUとGPUが共通にアクセスできるメモリのように動作するユニファイドメモリという機能をサポートした。
4.5 エラーの検出と訂正
・宇宙線に起因する中性子の衝突で電子回路はエラーを起こす。グラフィックでは問題にならないが科学技術計算では計算途中で起こった1回のエラーが最終の計算結果を誤らせるということが起こる。問題はエラーが起こったかどうかが分からないと計算結果を信用できないということである。
●科学技術計算の計算結果とエラー
・エラーが発生していないことを100%保証することはできない。そこでエラーを見逃すことがほとんどないというシステムを作ることが重要になる。
・「エラーが起こっていない」=「エラーが起これば検出できる」という機能が必須である。
第5章 GPUプログラミングの基本
5.1 GPUの互換性の考え方
・CPUは上位互換が一般的だが、GPUはまだ発展途上の技術のためハードウェアの変更が多く、CPUのような上位互換の実現は難しい。
●ハードウェアの互換性、機械語命令レベルの互換性
・CPUの世界ではIntelのCPUとAMDのCPUは命令互換のため、Intel用とかAMD用はない。
・IBMのPOWERやArmのプロセッサ、あるいはRISC-Vの間ではハードウェアの互換性はないため、それぞれに専用のバイナリ(機械命令)プログラムを使う必要がある。
・スマートフォンなどで使われているAndroidは仮想マシンの技術を使って、異なるアーキテクチャのプロセッサを仮想的に同じハードウェアに見せることで互換性を実現している。
●GPU言語レベルの互換性
・CUDAやOpenCLという言語は多くの場合、C言語で開発されている。CUDAはNVIDIA独自の言語だが、OpenCLは業界標準のプロセッサ言語である。
5.2 CUDA[NVIDIAのGPUプログラミング環境]
・CUDAはGPUのプログラミングに必要な最低限の機能を、C言語に追加するというアプローチで開発された。
●NVIDIA GPUのコンピュート能力
・NVIDIAはそれぞれのGPUについてコンピュート能力という値を公表している。コンピュート能力はSM(Streaming Multiprocessor)の機能を公表している。
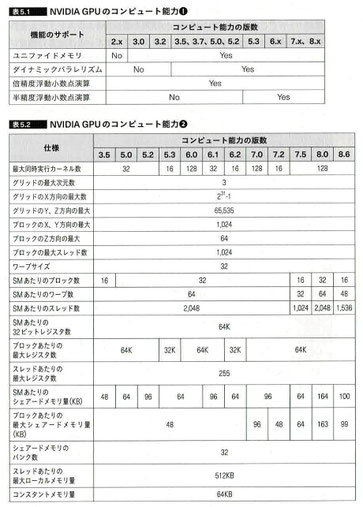
画像出展:「GPUを支える技術」
5.5 OpenMPとOpenACC
・C言語などで書かれたソースコードに、この部分はGPUを使って並列実行といった指示を書き加えるだけでGPUを使う並列プログラムを作ろうというのがOpenACC(ACCはAccelerator)やOpenMP(Multi-Processor)である。
GPUを支える技術1
設計システムはCAD(Computer Aided Design)と呼ばれています。入社後、営業管理部門から希望して移動した営業部門は、機械系設計のCADシステムや解析(CAE)システムなどを販売する部門でした。
ドイツで開発されたCADのソフトウェアは2次元の設計・製図システムがME10、3次元の立体モデルの設計システムがME30という名称でした。ざっと35年前の恐ろしく昔の話です。このME30というシステムはソフトウェアとハードウェアで1システム2,000万円以上、年間10台~15台売ればノルマ達成という感じでした。

画像出展:「Yahoo Auction」
現代では想像もできないような価格ですが、このME30という3次元CADにはSRXというグラフィックエンジンを搭載した特別仕様のEWS(エンジニアリングワークステーション)が必要なため、これだけで1,000万円以上していたと思います。
おそらく、当時のグラフィック処理をするエンジンが、NVIDIAなどが開発するGPUにつながったのだと思います。GPUはGraphics Processing Unitという名の通りグラフィックス処理用の半導体チップですが、同時に様々なソフトウェアの技術革新もあったのだろうと思います。
そして、そのグラフィック処理エンジンから派生する様々な革新が、AIの土台となるニューラルネットワークなど、新しいITの世界を切り開こうとしているように見えます。そこにはどんな歩みがあったのか、将来の可能性はどのようなものなのか、多くの発見があると期待しこの本を購入しました。

著者:Hisa Ando
第2版発行:2021年3月
出版:(株)技術評論社
目次 (大項目と中項目だけを書き出しています)
第1章 [入門]プロセッサとGPU
1.1 コンピュータシステムと画像表示基盤
●コンピュータ画像で表示するしくみ
●画像を表示するディスプレイ
●液晶ディスプレイ
-Column プロセッサの構造と動き
●フレームバッファとディスプレイインターフェース
1.2 3Dグラフィックスの歴史
●初期のグラフィックス
●コンピュータグラフィックスの利用の広がり
●3次元物体のモデル化と表示
1.3 3Dモデルの作成
●張りぼてモデルを作る
●マトリクスを掛けて位置や向きを変えて配置を決める
●光の反射を計算する
1.4 CPUとGPUの違い
●GPUは並列処理で高い性能を実現する
●GPUの出現
●GPUコンピューティングの出現
-整数と浮動小数点数
●GPUは超並列プロセッサ
●CPUはGPUのヘテロジニアスシステムと、抱える問題
1.5 ユーザーの身近にあるGPUのバリエーション
●携帯機器向けのGPU
●CPUチップに内蔵されたGPU
●ディスクリートGPUとグラフィックスワークステーション
1.6 GPUと主な処理方式
●共通メモリ空間か、別メモリ空間か
●フルバッファ方式か、タイリング方式か
●SIMD方式か、SIMT方式か
1.7 まとめ
-Column プロセッサと半導体の世代
第2章 GPUと計算処理の変遷
2.1 グラフィックとアクセラレータの歴史
●グラフィック処理ハードウェアの歴史
●アーケードゲーム機
●家庭用ゲーム機
●グラフィック
2.2 グラフィックボードの技術
●2Dの背景+スプライト
●BitBLT
●2Dグラフィックアクセラレータ
●3Dグラフィックスアクセラレータ
2.3 GPUの科学技術計算への応用
●ユニファイドシェーダ
●GPUで科学技術計算
●科学技術計算は32ビットでは精度不足
●CUDAプログラミング環境
●エラー検出、訂正
-Column ムーアの法則と並列プロセッサ
2.4 並列処理のパラダイム
●GPUの座標変換計算を並列化する
●MIMD型プロセッサ
●SIMD型プロセッサ
●SIMD実行の問題
●SIMT実行
-Column ARMv7のプレディケート実行機能
2.5 まとめ
第3章 [基礎知識]GPUと計算処理
3.1 3Dグラフィックスの基本
●[基礎知識]OpenGLのレンダリングパイプライン
●フラグメントシェーダ
●サンプルごとのオペレーション
3.2 グラフィック処理を行うハードウェアの構造
●Intel HD Graphics Gen9 GPUコア
3.3 [速習]ゲームグラフィックとGPU
●【ハードウェア面の進化】先端3Dゲームグラフィック・デモクラシー
●PlayStationとセガサターンが呼び込んだ3Dゲームグラフィック・デモクラシー
●DirectX 7時代
●プログラマブルシェーダ時代の幕開け
●【ソフトウェア面の進化】近代ゲームグラフィックにおける「三種の神器」
●【光の表現】法線マッピング
●【影の表現】最新のGPUでも影生成の自動生成メカニズムは搭載されていない
●【現在主流の影表現】デプスシャドウ技法
●HDRレンダリング
●HDRレンダリングがもたらした3つの効能
●ジオメトリパイプラインに改良の兆し
●DirectX Raytracing(DXR)
●DirectX Raytracingのパイプライン
3.4 科学技術計算、ニューラルネットワークとGPU
●科学技術計算の対象は非常に範囲が広い
●科学技術計算と浮動小数点演算
●浮動小数点演算の精度の使い分け
●ディープラーニングに最適化された低精度浮動小数点数
3.5 並列計算処理
●GPUのデータ並列とスレッド並列
●3Dグラフィックスの並列性
●科学技術計算の並列計算
3.6 GPUの関連ハードウェア
●デバイスメモリに関する基礎知識
●CPUとGPUの接続
●電子回路のエラーメカニズムと対策
3.7 まとめ
第4章 [詳説]GPUの超並列処理
4.1 GPUの並列処理方式
●SIMD方式
●SIMT方式
4.2 GPUの構造
●NVIDIA Turing GPUの基礎知識
●NVIDIA GPUの命令実行のメカニズム
●多数のスレッドの実行
●SMの実行ユニット
●NVIDIAのTensorコア
-Column ディープラーニングの計算と演算精度
●GPUのメモリシステム
-Column RISCとCISC
●ワープスケジューラ
●プレディケート実行
4.3 AMDとArmのSIMT方式のGPU
●AMD RDNAアーキテクチャGPU
●スマートフォン用SoC
●Arm Bifrost GPU
4.4 GPUの使い勝手を改善する最近の技術
●ユニファイドメモリアドレス
●NVIDIA Pascal GPUのユニファイドメモリ
●細粒度プリエンプション
4.5 エラーの検出と訂正
●科学技術計算の計算結果とエラー
●エラー検出と訂正の基本のしくみ
●パリティエラーチェック
●ECC
●強力なエラー検出能力を持つCRC
●デバイスメモリのECCの問題
-Column ACEプロトコルとACEメモリデバイス
4.6 まとめ
第5章 GPUプログラミングの基本
5.1 GPUの互換性の考え方
●ハードウェアの互換性、機械語命令レベルの互換性
●NVIDIAの抽象化アセンブラPTX
●GPU言語レベルの互換性
5.2 CUDA[NVIDIAのGPUプログラミング環境]
●CUDAのC言語拡張
●CUDAプログラムで使われる変数
●デバイスメモリの獲得/解放とホストメモリとのデータ転送
●[簡単な例]行列積を計算するCUDAプログラム
●CUDAの数学ライブラリ
●NVIDIA GPUのコンピュート能力
●CUDAのプログラムの実行制御
●CUDAのユニファイドメモリ
●複数CPUシステムの制御
5.3 OpenCL
●OpenCLとは
●OpenCLの変数
●OpenCLの実行環境
●カーネルの実行
●OpenCLにおけるメモリ
●OpenCLのプログラム例
5.4 GPUプログラムの最適化
●NVIDIA GPUのグリッドの実行
●メモリアクセスを効率化する
●ダブルバッファを使って通信と計算をオーバーラップする
5.5 OpenMPとOpenACC
●OpenMPとOpenACCの基礎知識
●NVIDIAが力を入れるOpenACC
●OpenMPを使う並列化
●OpenACCとOpenMP
5.6 まとめ
第6章 GPUの周辺技術
6.1 GPUのデバイスメモリ
●DRAM
6.2 CPUとGPU間のデータ転送
●PCI Express
●NVIDIAのNVLink
●IBMのCAPI
●NVIDIA NVSwitch
6.3 まとめ
-Column AMD HIP
第7章 GPU活用の最前線
7.1 ディープラーニングとGPU
●ディープラーニングで使われるニューラルネットワーク
●ディープラーニングで必要な計算とGPU
●ディープラーニングでのGPUの活用例
7.2 3DグラフィックスとGPU
●自動車の開発や販売への活用
●建設や建築での活用
●Nikeのスポーツシューズの開発
●VR、ARの産業利用
●NVIDIAのGRID
●物理的に複数ユーザーにGPUを分割するMIG
7.3 スマートフォン向けのSoC
●Snapdragon 865とSnapdragon 835
7.4 スーパーコンピュータとGPU
●世界の上位15位までのスーパーコンピュータの状況
●スーパーコンピュータ「富岳」
●Preferred Networksのスーパーコンピュータ「MN-3」
7.5 まとめ
-Column Apple M1とそのGPU
第8章 ディープラーニングの台頭とGPUの進化
8.1 ディープラーニング用のハードウェア
●ディープラーニング用のハードウェア
●低精度並列計算で演算性能を上げる
8.2 各社のAIアクセラレータ
●GoogleのTPU
●NVIDIAのTensorコア
●LeapMindのEfficiera
●Habana LabsのGoyaとGaudi
-Column RoCE Remote DMA on Converged Ethernet
●システムの拡張性
●ArmのMLプロセッサ
●CerebrasのWafer Scale Engine
8.3 ディープラーニング/マシンラーニングのベンチマーク
●ILSVRCの性能測定
●MLPerfベンチマーク
●MLPerfの学習ベンチマーク
●MLPerfの推論ベンチマーク
●MLPerfに登録された学習ベンチマークの測定結果(v0.7)
●MLPerfに登録された推論ベンチマークの測定結果(v0.7)
8.4 エクサスパコンとNVIDIA、Intel、AMDの新世代GPU
●Perlmutter
●NVIDIAのAmpere A100 GPU
●Intelは新アーキテクチャのXe GPUを投入
●AMDは新アーキテクチャCDNA GPU開発へ
8.5 今後のLSI、CPUはどうなっていくのか?
●微細化と高性能化
●チップレットと3次元実装
●CPUはどうなっていくのか
●高性能CPUの技術動向
●機械学習を使う分岐予測
●演算性能を引き上げるSIMD命令
8.6 GPUはどうなっていくのか
●GPUの今
●GPUの種類
●消費電力の低減
●アーキテクチャによる省電力設計
●回路技術による省電力化
8.7 まとめ
第1章 [入門]プロセッサとGPU ※GPU:Graphics Processing Unit
1.1 コンピュータシステムと画像表示基盤
●コンピュータ画像で表示するしくみ
・コンピュータはプログラムを実行し、フレームバッファ(メモリ)にデータを書き込む。動画はフレームをパラパラ漫画のようにして表示する。
・表示専用のメモリはVRAM(Video RAM)と呼ばれる。
・フレームバッファをディスプレイに表示するためには、ディスプレイインターフェースが必要である。
・複雑な画像の場合、データ生成、フレームバッファの書き込みには多くの計算とメモリアクセスが必要であり、高速に表示、描画させるためにプロセッサ(CPU)を補助する専用チップが開発された。これらはビデオチップや、グラフィックアクセラレータと呼ばれてきた。
●画像を表示するディスプレイ
・昔はブラウン管(CRT:Cathode Ray Tube)という一種の真空管が使われていた。現在は液晶ディスプレイや有機EL(Electro-luminescence)が使われている。
●フレームバッファとディスプレイインターフェース
・最近のGPUは表示機能、描画機能に加えてビデオのデコードやエンコード機能を内蔵しており、今はディスプレイインターフェース専用のチップは過去のものとなっている。
1.2 3Dグラフィックスの歴史
・文字だけでなく図が加わると、情報の伝達が飛躍的に容易になる。
●コンピュータグラフィックスの利用の広がり
・汎用コンピュータや専用の画像処理プロセッサの能力が向上するにつれて、より高度な画像表示ができるようになった。
・コンピュータグラフィックス(CG)は、画像の品質、動画、ゲームなど、それぞれのニーズにあったプロセッサが求められた。
●3次元物体のモデル化と表示
・3Dグラフィックスは1つの次元を固定すれば2次元になる。それにより3次元の表示機能を持つGPUが一般的になっている。1999年頃になると3Dグラフィックスに必要な機能の大部分をワンチップに収めることができるようになった。NVIDIAは「GeForce 256」などゲーム向けの3DグラフィックスLSIを発売した。
1.4 CPUとGPUの違い
●GPUは並列処理で高い性能を実現する
・CPUの演算器は数個~数十個だが、GPUの場合は数十~数千個にものぼる。すべて並列に動作させればCPUより1~2桁高い演算性能を得られる。
・メモリはGDDR DRAM(Graphics Double Data Rate Dynamic Random Access Memory)という従来のDDRメモリより1桁高いバンド幅を持つメモリを使っている。
・性能を高めるには並列に実行させるプログラムが必要である。
●GPUの出現
・1999年、NVIDIAは開発したGeForce 256をGPU(Graphics Processing Unit)と名付けた。そして、3Dの画像を描画するLSIを「GPU」と呼ぶようになった。

画像出展:「GPUを支える技術」
・GeForce 256の出現から10年くらいは、グラフィックス計算には整数演算が使われていた。その後、GPUチップに使えるトランジスタ数が増えると、浮動小数点演算器を搭載するようになり、2008年には32ビットのGPU(GeForce 8000)が一般的になった。これによりGPUは行列(マトリクス)の掛け算など、科学技術計算にも利用され始めた。さらに64ビットのGPUも開発された
●GPUは超並列プロセッサ
・デスクトップPC向けCPUとゲーム向けGPUの違い

画像出展:「GPUを支える技術」
特に印象的なのはスレッド数(1つのCPUが同時に実行できるプログラム数の最小単位)、オンチップメモリ、クロック周波数です。この差をみると、CPUではどうしようもない計算世界が存在するのが分かります。
また、最近ではGPUへの依存度を減らすためカスタムシリコン(システム・オン・チップASIC)が注目されています。
●CPUはGPUのヘテロジニアスシステムと、抱える問題
・CPUとGPUによる共同作業
-CPU:OS、I/Oネットワーク、データ入力、データ送受信(PCI)
-GPU:データ送受信(PCI)、計算、ディスプレイ
1.5 ユーザーの身近にあるGPUのバリエーション
●携帯機器向けのGPU
・CPUとGPU、その他の各種ユニットをワンチップにまとめたスマートフォン用のSoC(System on Chip)が代表的である。熱問題(冷却器がない)や使用時間を考慮し、低消費電力(1W以下)が重要である。
●CPUチップに内蔵されたGPU
・ノートPCではCPUチップにGPUが内蔵されているものが多い。消費電力は数Wから最大100W程度。
●ディスクリートGPUとグラフィックスワークステーション
・ゲーマーやデザイナーは高性能なグラフィックスを求める。そのため、CPUとは独立したPCI Expressカードなどに搭載されたGPU(ディスクリートGPU)が使われる。これにより消費電力による影響を減らし、高バンド幅のメモリを使うことができる。
1.6 GPUと主な処理方式
●共通メモリ空間か、別メモリ空間か
・GPUは高いバンド幅を必要とするため、両者が共通のメモリを利用するのは難しい。そのためメモリ空間は別というのが一般的である。
・メモリ間のデータ転送にはDMAエンジン(Direct Memory Access engine)が必要になる。
・CPUとGPUのメモリを共有することは、GPU開発メーカーの重要な開発目標になっている。
●SIMD方式か、SIMT方式か
・科学技術計算などの用途のためにNVIDIAが開発したのがSIMT(Single Instruction, Multiple Threading)という処理方式である。要素数に関わらず全ての演算器を無駄なく使えるので、SIMT方式が増えている。
AIと医療2

Chapter4 信頼するが、検証する
・GPT-4は管理業務の軽減だけでなく、患者に焦点を当てた知的で感情的なプロセスとしての医療に貢献する。しかし、その一方で、その潜在的なリスクも大きい。おそらくは当分の間、GPT-4は人間の直接の監視なしに医療現場で使用することはできないだろう。
●驚きと不安
・GPT-4に対する不安は、GPT-4のアドバイスが安全で効果的であることを、どのように保証したり証明したりできるかが分からないからである。
●臨床試験
・GPT-4には明確な人間の価値観が欠けている。それはGPT-4の中には、患者の嗜好、価値観、リスク回避、そして人間を構成する何百ものバイアス[非合理的な判断をしてしまう心理現象のこと]の明示的な表現がないからである。
●訓練生
・現時点では、GPT-4は臨床症例に対して最も善意ある人間と同じように行動し、反応する仕組みを持っているとは考えられていない。
●しかし、パートナーとしては……
・GPT-4が自律的に行動しないとしても、医療を改善する上でのGPT-4の可能性は桁外れに大きいように見える。それは医療従事者に取って替わるのではなく、補完するためである。米国の医療における人手不足の問題は深刻であり、今後10年以内に不足する医師は48,000人に達すると推定されている。医療者の燃え尽き症候群の問題も深刻である。仕事への不満、ストレス、患者との時間を増やせないことや最新の医療知識を身に付けられないことへの不満など、その重荷の中には絶え間なく更新される臨床ガイドライン、医療費の30%を消費すると推定されるほどのお役所仕事なども含まれる。このような厳しい労働環境は医療ミスの温床にもつながる。
●先導者
・GPT-4は超人的な臨床能力を有している。そして、患者の病気を引き起こしている可能性のある遺伝子を特定する専門医の役割を果たせる可能性もある。
Chapter5 AIで拡張された患者
・訓練を受けた医療従事者がGPT-4にアクセスできるようにすることと、新しいAIスーパーツールを情報の荒野に解き放ち、患者が直接利用できるようにすることは全くの別物である。
・GPT-4は人類が蓄積した医療情報を掘り起こす驚異的なルーツであり、ユーザがそれを使いたがるのは当然である。
・米国の成人の約75%がオンラインで健康情報にアクセスしており、彼らがWebMDや検索システムから「個人的な医療情報を分析できる医学的に全知全能なAI」と「患者が望むだけ長くやり取りできる新しい大規模言語モデル」へと大移動することは容易に想像できる。
●持たざる人々
・人類の半分、約40億人が十分な医療を受けられていないと推定されている。
・GPT-4やAIシステムの最も有望な側面の1つは、遠隔地への医療である。
・AI医療は最終的には医師に残された仕事が「複雑な意思決定と人間関係の管理」だけになる医療システムへと向かっていると考える研究者もいる。
●新しい三者の関係
・GPT-4の潜在的な利点には、「継続的なモニタリングが不可能」になった患者への積極的な連絡と情報やサービスの提供である。COVIDの患者をスクリーニングするという目的で実施された、パンデミック時のチャットボットの実験は、社会から疎外された人々に大規模にリーチする上でテクノロジーがどのように利用できるかを実証した。
・GPT-4を最初にどのように使うかを考えるべきである。それは理想的には「医療の助けを最も必要としているのは誰か」ということである。それは「社会的弱者のコミュニティ」かもしれない。
●情報に基づく選択
・GPT-4はあらゆる患者にとって米国の医療制度におけるもう1つの困難な側面を解決する可能性を示している。それは、適切な医療を見つけることである。これはAIが患者のパートナーとして、信頼できる公平な医療のガイドとなることを目指すということであり、1960年代のインフォームドコンセントを一歩超えた概念ある。

画像出展:「AI医療革命」
こちらは「血液検査」の結果です。専門家でないと理解するのは困難な内容です。
下のQAですが、プロンプト5-8は質問で、「この検査結果はどう?」と聞いています。また、次の質問(プロンプト5-9)では、眠れない原因について尋ねています。
そして、それぞれGPT-4が回答(回答5-8、5-9)していますが、どうみても医師から回答のように見えます。

画像出展:「AI医療革命」
●より良い健康
・GPT-4は「グープ(goop)」と呼ぶ「疑似科学に基づく健康アドバイスの氾濫」に対処する上でも役立つのではないか。
●セラピーAI
・「AIはセラピストであり、友人であり、恋人にさえなれる」とは、ボストン・グルーブ紙のニュース記事の見出しである。ReplikaというAIフレンドはApp Storeから1000万回以上ダウンロードされている。
・AIがセラピストに取って代われるのかは分からないが、セラピスト、特に優秀なセラピストは不足している。また、有害なセラピー(心のケア)が存在している。ロイ・パーリス博士(ハーバード大学医学部の精神医学教授)は非常に効果的なセラピストによるセラピー・セッションの記録をAIに学習させることで、その才能をより広く利用可能にできるかもしれにないと考えている。
・AIがメンタルヘルスに役立つかは「一長一短」である。軽度の不安や抑うつなどには適しているかもしれないが、重症な人には適さないと考えられる。
・AIは一次医療やオンラインCBT(認知行動療法をオンラインで提供するプログラムやサービス)でうまくいく人もいれば、治療や入院治療が必要な人もいる。
・インターネットとモバイルの時代は、地球上の人の手に情報を届けるものだった。一方、AIの時代は、地球上の人の手に知性が行き渡るようになる。その知性とは、とりわけ医療に応用できるものである。
Chapter6 もっとはるかに:数字、コーディング、ロジック
・GPT-4はUSMLE(米国医師国家試験)と同様にNCLEX(看護師国家試験)でも好成績を収めている。
●GPT-4は計算して、コードを書く
・GPT-4は点滴の問題の他、薬物の相互作用の可能性に関する質問にも答えることができる。そして、それをコンピュータプログラムの形でも説明できる。それも「アプリを作ってほしい」と頼むだけである。
・GPT-4は一般的なアプリケーションを使って計算することも得意であり、表計算ソフトの使い方にも答えることができる。
●GPT-4は不思議なことに論理的であり、常識的な推論もできる
・GPT-4は数学、統計学、コンピュータプログラミングの能力だけでなく、倫理的推論に長けている。
●GPT-4とはいったい何なのか
・GPT-4には人間の脳とは異なる制限がある。
・GPT-4の「機械学習」は電源をオフにして、新たな知識や能力を吸収しなければならない。これはトレーニングと呼ばれ、多くのテキスト、画像、ビデオ、その他のデータを収集し、特別な一連のアルゴリズムを使ってすべてのデータを抽出し、モデルと呼ばれる特別な構造にする。ひとたびモデルが構築されると、推論エンジンと呼ばれる別の特別なアルゴリズムが、例えば、チャットボットの回答を生成するためにモデルを実行に移す。
・GPT-4のニューラルネットワークの正確なサイズは公表されていないが、その規模は非常に大きく、それをトレーニングするのに十分なコンピューティングパワーを持つ組織は世界でもほんの一握りしかない。おそらく、これまでに構築され、一般に配備された人工ニューラルネットワークの中で最大のものと思われる。
・GPT-4の能力の大部分は、ニューラルネットワークの規模に起因している。
・OpenAIの技術者たちは極端なスケールが人間レベルの推論を達成する道筋となることに対して確信がない。そして、十分なスケールが達成された途端に、その多くが「ひょっこり出現」したという事実や「失敗モード(システムやモデルが予期せぬ方法で不適切に動作する状況)」が非常に不可解である理由の一端を説明している。
・人間の脳がどのように「考える」を達成するのかを、我々が理解できていないのと同様に、GPT-4がどのように「考える」のかについての多くのことを、我々は理解できないのである。
●GPT-4は単なる自動補完エンジンなのか
・GPT-4は「単なる」コンピュータプログラムである。
・GPT-4は実際に何をしているのか。「GPT-4のようなLLMは、次の単語を予測する」と言われることがある。それは、LLMは大規模統計分析を使って、これまでに起こった会話から、次に(コンピュータまたはユーザのどちらかから)吐き出される可能性が高い単語を予測する。
●しかし、GPT-4にはいくつかの絶対的限界がある
・人間は能動的に考え、世界と対話しながら学習することができる。常にオンライン、ライブである。一方、GPT-4はオフランでのトレーニングが必須である。仮に最後のトレーニングが2022年1月とすればそれ以降は何も学習していないことになる。
・GPT-4は長期記憶の欠如という限界がある。GPT-4でセッションを始める時、GPT-4は白紙の状態でセッションを行う。そして、セッションが終わると会話の内容はすべて忘れ去られてしまう。
・GPT-4はセッションの長さに制限がある。セッションサイズの上限に達すると会話はすべて中断され、新たにセッションを始めるほかない。
・人間の脳の古い記憶に関する能力は解明されていない。また、脳は体力と気力がある限り会話を続けられるが、GPT-4にはそれはできない。
●注意、GPT-4は微妙な誤りを犯す
・GPT-4には誤りは珍しいことではないので、「信頼するが、検証する」は極めて重要である。特に、数学、統計学、論理学に関しては特に注意する必要がある。
・GPT-4の確認作業は別のGPT-4とのセッションを利用する。もしくは人間が確認することである。
・GPT-4の誤りが難しい1つの要因は、人間にとって非常に難しい問題を解ける一方で、些細と思われる問題を正しく解答できない場合も少なくないからである。
・GPT-4はコードを書いたり、APIを使ったりすることができるので、ソルバーやコンパイラ、データベースなどのツールを使えるようにすると制限を克服できるかもしれない。また、医療系では病院の電子カルテシステムや医療画像データベースへのアクセス権が与えられるとGPT-4の予測可能性は向上するだろう。
●結論
・GPT-4は絶え間ない進化と改善を続けている。
・GPT-4の出力を検証することが非常に重要である。もし、検証することができないならば、GPT-4の結果を信用しない方が賢明である。
・GPT-4が実際に「考える」か、「理解する」か、「感じる」かについては、コンピュータ科学者、心理学者、神経科学者、哲学者、宗教指導者などが延々と議論し、論争していくと考えられる。そして、このような議論はとても重要である。
・今日、最も重要なことは、GPT-4のような機械と人間がどのように協力し、人間の健康を増進させるかということである。GPT-4はヘルスケアの改善に貢献する並外れた可能性を秘めている。
Chapter7 究極のペーパーワークシュレッダー
・ペーパーワークを嫌う人は多いが、医療分野で考えれば、治療に関する情報を文書化して共有し、改善に役立てるためにある。文書で物事を共有することは、治療ミスのリスクを減らし治療の効果を高める。また、病院経営には請求、送金、保険契約などの多くの事務処理が存在している。医療は厳しく規制された業界であり、政府による規制を守る方法は医療業務を文書化することである。
・医師や看護師の燃え尽き症候群は増加の一途をたどっており、職業的満足感を抱いているのは22%という調査結果も出ている(HealthDay:健康と医療に関連するニュースと情報を提供するサービス)。燃え尽き症候群の最大の原因は人員不足であるが、その次の要因は、医師の58%、看護師の51%が事務処理の問題をあげている。
おわりに
『今日は2023年3月16日、我々はこの本の執筆を終えようとしている。ありがたいことだ。つい2日前、OpenAIはGPT-4を正式に世界に公開した。
同じ日、マイクロソフトは新しいBingとEdgeのチャット機能を支えるAIモデルがGPT-4であることを明らかにした。グーグルも同日、大規模言語モデルへの開発者のアクセスを提供するPaLM APIを発表した。そのわずか1日後、アントロピック(AIの研究と開発を行う米国のスタートアップ企業)は次世代AIアシスタント「Claude」を発表した。そして今日、マイクロソフトはWord、Excel、Outlook、PowerPointのアプリケーションにGPT-4を統合することを発表した。今後数週間で、さらに多くのLLMベースの製品が市場に登場することは間違いない。AI競争は本格化しており、我々の働き方や生き方を永遠に変えるだろう
昨日、私の同僚(そして上司)であるケビン・スコットが次のような言葉を私に教えてくれた。
(それは)人間の力を大いに増大させたが、人間の善良さをあまり増大させなかった。
これはイギリスの随筆家、戯曲・文芸評論家、画家、哲学者であるウィリアム・ハズリットが1818年に発表したエッセイ「学識者の無知について」の中で書いた言葉である。私はGPT-4に、ハズリットなら大規模言語モデルとそれが人間に及ぼすであろう影響について何と言っただろうと尋ねてみた。GPT-4はこう答えた。

画像出展:「AI医療革命」
『GPT-4の出現によって、今日何が起きてるのか、特に人間の健康と福祉に及ぼす潜在的な影響を考えずに、ハズリットの言葉を読むことはできない。このことに関する世間の議論は、おそらく激しく騒がしいものとなるだろう。そして、本書がそうした議論に貢献しようとしても、ハリケーンに向かって叫ぶようなことになるかもしれない。しかし、本書がそのような議論に参加しようとする人たちにとって少しでも役に立てば幸いである。社会は今後、非常に重大な倫理的・法的な問題に直面することになるだろう。そのため私は、できるだけ多くの人々が、その答えを導き出せるような能力を備えることを切に願っている。我々は、AIと健康について理解している人々が積極的な役割を果たし、この新しい力を「不適切な行動」ではなく、「人間の善意」へと向ける必要がある。』
感想
AIはやはりITの革新だと思います。それは以下のように思うからです。しかし、もし、AIが無秩序に利用されるとすれば、大きなリスクを抱えることも確かだと思います。
「働く人は良い仕事をしたいと思っている。効率よく仕事をしたいと思っている。経営者は会社を維持そして成長させるため、仕事の質を上げたいと思っている。生産性を上げたいと思っている。利益を上げたいと思っている。世間からの評価を高めたいと思っている。
このためには、有能なパートナーが必要である。それは必ずしも人間でなくても問題はないのではないか。生成AIをパートナーのように有効活用したい経営者は間違いなくいる。そしてうまく活用した企業は大きな成長の機会を手にすると思う。」
AIと医療1
AIに関しては“生成AIの可能性”というブログをアップしています。そして、AIは一時的なものではなくITにとっての革新であり、発展していくものだろうと思っています。
今回の本のタイトルは『AI医療革命』なのですが、興味をもったのはAIを牽引するリーダー的存在のNVIDIAが、特にAI医療に注目しているということを知ったためです。


著者:ピーター・リー、アイザック・コハネ、キャリー・ゴールドバーグ
発行:2024年1月
出版:ソシム(株)
購入してから気づいたのですが、本のタイトルには、「ChatGPTはいかに創られたか」と書かれていました。これには少し戸惑いを感じました。おそらくそれは医療革命という響きが、医療の歴史や現状、あるいは医療に関わるシステムや業務プロセスを変革するような大きなものをイメージしていたためだと思います。
読み終えてその違和感は、本書が掲げるAI医療革命とはソフトウェア(コンピュータ言語)革命であり、医師や医療従事者の「考える」あるいは「つくる」という分野にAIが入り込み、そして支援する(共生医療)。それにより仕事の「質(正確性)」と「量(処理スピード)」を、従来の改善という小さなものではなく、大きな変革と呼べるような医療の在り方に変える。というものではないかと感じました。
IBMが“IBM Personal Computer 5150”を世に送り出したのは1981年です。これはITにおけるハードウェア&パーソナル革命と呼べるような気がします。

画像出展:「historyofinformation」
『1981年8月12日、IBMはIntel8088プロセッサをベースとしたオープン アーキテクチャのパーソナル コンピュータオフサイトリンク(PC) を発表しました』
そして、米国では1967年から、日本では1984年から研究者の間だけで使われていたインターネットですが、本格的に普及し始めたのは“Netscape”というブラウザが画期的だったからではないかと思います。その最初のリリースは1994年です。IBMのPC5150のリリースから13年後、これはネットワーク&モバイル革命のように思います。

画像出展:「日経XTECH」
ご参考:“なんかいウェブ研究所”
私はSEではないので技術的なことは分かりませんが、メインフレームと呼ばれる大型汎用システムの言語はCOBOLだったと思います。一方、オープンシステムでマルチタスクが特長だったUNIXシステムに関しては、Fortran、C++、Javaといったコンピュータ言語が有名だったと思います。
一方、AIで使われている言語は全く新しいタイプの言語であり、LLM(大規模言語モデル)と呼ばれています。生成AIにとってLLMはまさに無くてはならないもので、ニューラルネットワークで構成されるコンピュータ言語モデルとされています。このニューラルネットワークとは生物の学習メカニズムを模倣した機械学習法とされており、今までのコンピュータ言語とは発想が全く異なります。このことが、AIはソフトウェア(コンピュータ言語)革命ではないかと考えた理由です。
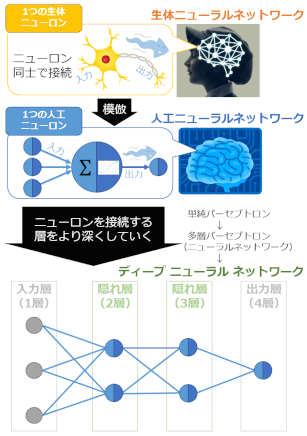
画像出展:「@IT」
『AIにおける人工のニューラルネットワークは、人間の脳が持つ神経ネットワーク(=生体ニューラルネットワーク)を簡易的に模倣、もしくはヒントにしたものです。深層学習に至るまでに、人工ニューラルネットワークは徐々に進化してきました。』

画像出展:「QuadCom」
“【IT最新トレンド】対話型AIとは何かを分かりやすく解説!”
『従来のAIは、人間がルールや指示を明示的に与えて学習します。一方、大規模言語モデルは、膨大なデータ(パラメーター)から自律的に学習します。この違いにより、大規模言語モデルは従来のAIよりも柔軟で、幅広いタスクを実行することができます。』
目次
序文 OpenAI サム・アルトマン
Chapter1 ファーストコンタクト
●GPT-4とは何か
●しかし、GPTは実際に医療について何か知っているのか
●医学の専門家も非専門家も使えるAI
●AIとの新たなパートナーシップは、新たな問いを投げかける
●ザックとその母に戻る
Chapter2 機械からの薬
●医療機関の新しいアシスタント
●GPT-4はつねに真実を語るのか
●臨床医のインテリジェントなスイスアミーナイフ
●給付金への説明
●医療の実践における伴走車
●GPT-4は現在進行形
Chapter3 大いなる疑問:それは、「理解」しているのか
●大いなる疑問:GPT-4は本当に自分の言っていることを理解しているのか
●常識的推論、道徳的判断、心の理論
●現実には限界がある
●では、大いなる疑問についてはどうだろう
Chapter4 信頼するが、検証する
●驚きと不安
●臨床試験
●訓練生
●しかし、パートナーとしては……
●先導者
Chapter5 AIで拡張された患者
●持たざる人々
●新しい三者の関係
●情報に基づく選択
●より良い健康
●セラピーAI
Chapter6 もっとはるかに:数字、コーディング、ロジック
●GPT-4は計算して、コードを書く
●GPT-4は不思議なことに論理的であり、常識的な推論もできる
●GPT-4とはいったい何なのか
●GPT-4は単なる自動補完エンジンなのか
●しかし、GPT-4にはいくつかの絶対的限界がある
●注意、GPT-4は微妙な誤りを犯す
●結論
Chapter7 究極のペーパーワークシュレッダー
●GPT-4は、紙の受付票を代替する
●GPT-4は診療記録の作成に役立つ
●GPT-4は品質向上を支援できる
●GPT-4は医療提供のビジネス面を支援できる
●GPT-4は価値基準医療の仕組みに役立つ可能性がある
●GPT-4に医療ビジネスの意思決定を任せられるか
Chapter8 より賢いサイエンス
●例:新しい減量薬の試験
●研究のための読書と執筆
●適格化のためのツール
●臨床データの分析
●消えたデータ
●基礎研究
Chapter9 安全第一
Chapter10 リトル ブラック バッグ
おわりに
序文 OpenAI サム・アルトマン
・本書は、GPT-4の汎用的な能力がどのように医療とヘルスケアに革命をもたらされるかを包括的に概説している。
・医療アプリケーションにおけるGPT-4の安全で倫理的かつ効果的な使用法に関する初期の実践指針を示し、その使用をテスト、認証、監視するための緊急の取り組みを呼びかけている。
Chapter1 ファーストコンタクト
・2022年秋、そのAIシステムはまだOpenAIが秘密裏に開発中だった。
・医療にどのような影響を与え、医学研究を変革する可能性があるかを探る。
・診断、診療記録、臨床試験のほぼすべての領域。
●GPT-4とは何か
・初心者ユーザはAIシステムを一種にスマートな検索エンジンのように捉えることが多いようだ。
・GPT-4は検索エンジンと統合できる。
・GPT-4の会話継続能力は素晴らしい。
・GPT-4は論理学や数学の問題を解くことができる。
・GPT-4はコンピュータプログラムを書ける。
・GPT-4はスプレッドシート、フォーム、技術仕様書など解読できる。
・GPT-4は外国語間の翻訳ができる。
・GPT-4は要約、チュートリアル、エッセイ、詩、歌詞、物語を書ける。これらはChatGPTより高度にこなす。
・GPT-4は複雑な数学の問題を解く一方で、単純な算数に間違えることもある。
・GPT-4は賢さと愚かさという二律背反の問題は、特に医療において最大の課題の一つである。
・携帯電話を忘れたような感覚はGPT-4にも言える。GTP-4がないと医療が成り立たない、手詰まりになる、そのような感覚を人間の健康という領域において共有することが本書の目的の一つである。
・GPT-4は新しい能力だけでなく、新しいリスクも提供する。
・GPT-4は出力の正しさを検証することが非常に重要である。
・GPT-4は自分自身の仕事と人間の仕事を見て、その正しさをチェックすることに長けている。
・医療は人間とAIの連携が求められる分野である。GPT-4だけでなく、人間によるエラーを減らすため、GPT-4をどのように使うか、事例とガイダンスが求められる。
・問題の核心にあるのは、人間と機械の新しいパートナーシップ、「共生医療」である。
●しかし、GPTは実際に医療について何か知っているのか
・GPT-4を医療に使う場合、GPT-4は医療について本当は何を知っているか、ということが大きな問題である。1つ確かなことは、GPT-4は医学の専門的な訓練を受けていないということである。
・医学的訓練を受けたGPT-4というアイデアは、OpenAIの開発者だけでなく、多くのコンピュータ科学者、医学研究者、医療従事者にとって非常に興味深いものである。その理由の1つは、GPT-4がどのような医学的「教育」を受けてきたかの正確な理解が、人間の医者についてと同様に重要なことが多いからである。
・「相関関係は因果関係を意味しない」。この区別は医療において決定的に重要である。例えば、パスタをたくさん食べると高血糖になるか、それとも単に相関関係があるだけで、根本的な原因は別にあるのかを知ることは重要である。GPT-4が因果関係の推論が可能かという問題は、本書の範囲外であり、まだ決着がついていないと言うのが適切である。
●医学の専門家も非専門家も使えるAI
・GPT-4は自らの回答を「易しく書き直して」、医学の素人も含めて、様々な人がアクセスできるようにすることが可能である。
・感情を想像し、人に共感できることがGPT-4の最も興味深い点の1つである。これは人の心の状態を想像する能力に関係しているかもしれない。このようなAIシステムとのやりとりについては、ときに機械による人間の感情の評価を「不気味」に感じることもあるだろう。
・GPT-4は不可解な診断例や難しい治療法の決定や臨床事務にも役立つが、最も重要なことは「患者との対話」において医師を支援する方法を見出したことだろう。GPT-4はしばしば驚くべき明晰さと思いやりをもってそれを実現する。
●AIとの新たなパートナーシップは、新たな問いを投げかける
・『ここまでで、GPT-4がまったく新しいタイプのソフトウェアツールであることはおわかりいただけたと願う。GPT-4の前に登場したヘルスケア向けのAIツールは、放射線スキャンを読み取ったり、患者記録のコレクションから入院リスクの高い患者を特定したり、診療録を読んで正しい請求コードを抽出し、保険請求のために提出したりといった特殊なタスクをこなしたりするものが多かった。このようなAIの応用は、重要かつ有用なものだ。何千人もの命を救い、医療費を削減し、医療に携わる多くの人々の日々の体験を向上させてきたことは間違いない。
しかし、GPT-4は、まさに別種のAIである。GPT-4は、特定のヘルスケアタスクのために特別に訓練されたシステムではない。実際、医療に関する専門的なトレーニングは一切受けていない。GPT-4は、従来の「狭義のAI」ではなく、医療に貢献できる初めての「汎用的な人工知能」なのだ。この点で、本書が扱う真の問いは、次のように要約される。すなわち、もし医療に関するほぼすべてを知る「箱の中の脳」があったら、それをどのように使うか、である。
しかしながら、もう1つ、より根本的な疑問がある。これほど重要かつ個人的かつ人間的で大きな役割を果たす資格が、人工知能にはどのくらいあるか、である。我々は皆、医師や看護師を信頼する必要がある。そのためには、我々をケアする人たちが良い心を持っていることを知る必要がある。
それゆえ、GPT-4が持つ最大の疑問、そして最大の可能性が見えてくる。GPT-4はどのような意味で「善良」なのだろう。そして、結局のところ、このようなツールは、我々人間をより良くしてくれるのだろうか。』
●ザックとその母に戻る
・『GPT-4をはじめとするAIが「考える」「知る」「感じる」のか、コンピュータ科学者、心理学者、神経科学者、哲学者、そしておそらく宗教家までもが、延々と続けるだろう。知性と意識の本質を理解しようとする我々の願いは、人類にとって最も根源的な旅の1つであることはたしかである。しかし、最終的に最も重要なのは、GPT-4のような機械と人間がどのように協力し、パートナーシップを結び、人間の状態を改善するために共同で探求していくのかということだ。』
Chapter2 機械からの薬
・GPT-4は文句を言ったり、叱ったりするのが好きではない。
・GPT-4と「関係」を持つという考え方は、本書の核心的な問いかけの1つであり、おそらく物議を醸すだろう。従来の常識では、思考し感情を持つ知覚的存在としてAIシステムを捉えるのは間違っており、AIを擬人化することには本当に危険が伴うと言われている。この問題は最も個人的な事柄の1つである医療において、特に重要だと思われる。
・GPT-4は常に変化し改善している。
●医療機関の新しいアシスタント
・米国の医療従事者の仕事量は20年間で劇的に増加した。医師や看護師は助けを必要としている。
・医療現場の日常業務の多くは、過酷で単調な事務作業などに追われている。
●GPT-4はつねに真実を語るのか
・GPT-4が出す間違った回答の問題点は、その答えが正しく見えることである。なぜなら、説得力のある方法で提示されるからである。
・GPT-4が医療現場のどこで使用すべきか、また医学のあらゆる側面、さらには医学研究論文などのレビューにも当てはまることである。
・GPT-4のような汎用AI技術は、教育的な推測や情報に基づく判断が必要とされる状況に巻き込まれる。
・医師-患者-AIアシスタントの「三位一体」が、医師-患者-AIアシスタント-AI検証者へと拡張される可能性がある。
●臨床医のインテリジェントなスイスアミーナイフ
・GPT-4は診療記録だけでなく、様々なフォーマットで質の高い診察後のサマリー(患者の診療情報や入院・退院時の概要、治療の経過などを簡潔にまとめた文書)を作成できる。
・GPT-4は会話に非常に長けているので、患者の状態や病歴に基づいて、内容の変更や推奨事項を提案することも可能である。
●給付金への説明
・GPT-4はデータを説明、比較、パーソナライズ、最適化し、フィードバック、推奨、精神的サポートを提供することで、医療費、検査結果、健康アプリなど消費者が自身の健康データを解読し、管理するのを支援できる。
●医療の実践における伴走車
・GPT-4はエビデンスに基づいた仮説を立て、複雑な検査結果を解釈し、一般的な疾患だけでなく稀な疾患や生命を脅かす疾患の診断も認識し、関連する参考文献や説明を提供することができる。
・GPT-4は高度に専門的な研究論文を読み、非常に洗練された議論を行うことができる。
・GPT-4の“ユニバーサル・トランスレーター”機能は、医師や看護師を目指す人々や一般の人々に対して、医学知識の普及や医学教育に役立つ可能性がある。
・GPT-4は医学雑誌の記事を読み、小学6年生の理科の授業にふさわしい要約とクイズを書くことができる。
・GPT-4は高度な医学研究の場で、推論を駆使して議論を促し、次の研究ステップの可能性を議論し、可能性のある答えを推測することができる。
・GPT-4はインフォームドコンセントのような倫理的概念にも精通していると思われる。
・GPT-4は全体として、透明性、説明責任、多様性、協調性、論理性、尊重の重要性について核心的な理解を持っている。
●GPT-4は現在進行形
・GPT-4は急速に進化しており、ここ数カ月の調査においても、その能力が著しく向上しているが、未完成であり、今後も絶え間なく進化し続けるだろう。
・本書の最大の目的は、この新しいAIが、ヘルスケアや医療、そして社会のその他の分野で果たす役割について、今後極めて重要な社会的議論に貢献することである。しかし、最も重要なことは、GPT-4自体が目的ではなく、新たな可能性と新たなリスクを併せ持つ世界への扉を開くものである。
・今後、GPT-4を凌ぐ有能なAIシステムは登場するだろう。GPT-4は加速度的に強力的になっていく汎用AIシステムの最初の一歩に過ぎないというのが、コンピュータ科学者たちの共通認識である。
・人工知能の進化に合わせ、医療へのアプローチをどのように進化させるのがベストなのかを理解することである。
Chapter3 大いなる疑問:それは、「理解」しているのか
・GPT-4が優れた会話システムであるのは、会話の全体像を把握している点である。これは今までのAI言語システムと大きく異なる点である。
・何のガイダンスもない場合、GPT-4はその回答を簡潔にするか、あるいは拡大解釈するかを自分で決めなければならない。
・GPT-4は口調を調整し、象徴を想起させ、進行中の会話の「雰囲気」に合わせるという能力を持っている。
●大いなる疑問:GPT-4は本当に自分の言っていることを理解しているのか
・GPT-4は読み書きを理解しアウトプットに意図はあるのか、それとも言葉をつなぎ合わせた無心のパターンマッチングなのかが疑問であるが、多くのAI研究者の見解は後者であり、ディープラーニングだけでは限界があると考えている。しかしながら、科学の問題としてこの「大いなる疑問」に答えるのは驚くほど難しい。そして、この種の問いは、科学的、哲学的議論の的であり、この疑問は長く続くものと思われる。
・GPT-4は詩を書くより分析する方が、文章を作成するより、それを見直す方が得意のようである。
・GPT-4が自分の意志を持っているとは思えないが、確信的な捏造や省略、さらには過失もある。このことは検証を必要とする理由である。
●常識的推論、道徳的判断、心の理論
・GPT-4は理解していないという根拠には、具体的な経験の欠如がある。また、より高度な知性、例えば、物理的世界における推論、常識、道徳的判断などにおいての限界は長年の研究結果もある。
・GPT-4はイエスかノーの答えを求める質問に応じないことによって、「自分の意思」を示しているようである。
●現実には限界がある
・今の所、「理解」という問題に決着をつけられていないが、GPT-4の推論能力にはいくつかの現実的な限界がある。
・GPT-4は数学において知性と無知が混在した不可解な動きを見せることがある。
●では、大いなる疑問についてはどうだろう
・GPT-4のように純粋に言語だけで訓練されたAIシステムは、「理解」していないという見解は正しいと思う。そして、大いなる疑問に関する全体的な科学的コンセンサスはその方向性に傾いている。しかしながら、少なくともGPT-4に関しては、これを証明することは意外に難しい。
・『数ヶ月にわたる調査の結果、私[ピーター・リー]は、最新の科学的研究によるテストでは、GPT-4が「理解が欠けている」ことを証明できないという結論に達した。そして、実際、我々がまだ把握していない、真に深遠な何かが起こっている可能性は十分にある。GPT-4は、我々がまだ特定ができていない何らかの「理解」と「思考」を持っているのかもしれない。ただ、1つ確実に言えるのは、GPT-4はこれまでに見たことのないものであるということだ。そして、GPT-4を、「単なる大きな言語モデル」として片付けるのは間違いであるということだ。』
・『大いなる疑問に対する回答や、知能と意図性についての、おそらくさらに大いなる疑問は、我々の科学的・哲学的探求の中心にある。一方で、最終的に最も重要なのは、GPT-4のようなAIシステムと我々の関係が、我々の心や行動をどのように形作るかということかもしれない。人間のように「理解」できるかに関わらず、GPT-4は、4章[信頼するが、検証する]で見るように、診療所から研究室に至るまで、我々の理解を大いに助けてくれるだろう。』
リーナス・トーバルズ
GPU(Graphics Processing Unit)の開発・製造において、生成AIのリーディングカンパニーであるNvidiaによるArm買収断念の報道は2022年1月でした。現在、ソフトバンク配下のArm社は英国ケンブリッジに本社を置く、RISC(縮小命令セットコンピューター)チップの開発に特化した企業で、携帯電話やスマートフォンのほとんどの製品の中に入っています。
このArmの対抗馬として期待されているのがオープンソースのRISC-Ⅴです。このRISC-Ⅴ ISA(命令セットアーキテクチャー)を利用することにより自由にCPUを開発することができます。しかも、設計したCPUをオープンソースにする必要はなく、商用ライセンスのCPUコアを作ることができます。
※オープンソース:ソフトウェアを構成しているプログラム「ソースコード」を無償で一般公開すること。
※“NVIDIA’s secure RISC-V processor”(Youtube[英語])
『Security is key to many of NVIDIA’s markets. Example applications are protecting video and gaming IP, keeping private data on shared servers from leaking, and safety of self-driving cars. NVRISCV is at the core of NVIDIA’s security architecture. It is a RISC-V core with closely coupled co-processors that incorporate many security features to protect against a variety of attacks. Some features are architectural and we are proposing those as RISC-V specifications; others are implementation specific. We believe that RISC-V is ideally positioned to standardize around a set of security specs and best practices, helped by transparency and joint development by the community, inherent to its open source nature.』
以下は上記の英文をDeepLを使って翻訳した文章です。
『セキュリティは、エヌビディアの多くの市場にとって重要です。アプリケーションの例としては、ビデオやゲームIPの保護、共有サーバー上のプライベートデータの漏洩防止、自動運転車の安全性などがあります。NVRISCVは、NVIDIAのセキュリティ・アーキテクチャの中核です。これは、密接に結合したコプロセッサを持つRISC-Vコアで、さまざまな攻撃から保護するために多くのセキュリティ機能を組み込んでいます。いくつかの機能はアーキテクチャ上のものであり、私たちはそれらをRISC-V仕様として提案しています。私たちは、RISC-Vが、そのオープン・ソースという性質に固有の透明性とコミュニティによる共同開発によって、一連のセキュリティ仕様とベスト・プラクティスを標準化するのに理想的な位置にあると信じています。』
日本HPで営業していたのは約12年前なのですが、オープンソースと言われればソフトウェアの話しという認識しかなかったため、CPUというハードウェアの世界にもオープンソースが入り込んでいるという事実に大変驚きました。
オープンソースと言われれば、私の場合Linuxです。IBM社がLinuxを核にサーバーの長期計画を発表したのは2001年でした。HP社はUNIX(HP-UX)が主力であったという経緯もあり、Linuxに対しては消極的でした。SEの評価はLinuxは軽く優れたOS(オペレーティングシステム)というものであり、製品品質に大きな懸念はなかったのですが、メーカーサポートという面で営業としてはなかなか難しい製品となっていました。
このような懐かしい昔話を思い出していて、ふと気になったのが、「今、Linux、特に開発者のリーナス・トーバルズはどうなっているのだろう?」という疑問です。
『それがぼくには楽しかったから』、これがリーナス・トーバルズの本の題名です。なお、原題は『JUST FOR FUN』です。

著者:リーナス・トーバルズ
訳者:風見潤
初版発行:2001年5月
出版:(株)小学館プロダクション

画像出展:「Wikipedia」
Linus Benedict Torvalds
『フィンランド、ヘルシンキ出身のアメリカ合衆国のプログラマ。Linuxカーネルを開発し、1991年に一般に公開した。その後も、公式のLinuxカーネルの最終的な調整役を務める。』
目次
謝辞
序章 人生の意味Ⅰ
第1部 オタクの人生
第1章 眼鏡と鼻と
第2章 初めてのプログラミング
第3章 フィンランドの冬に
第4章 トーバルズ家誕生秘話
第5章 高校時代
第6章 大学と軍隊
第7章 フィンランド再び
第2部 オペレーティング・システムの誕生
第1章 シンクレアQL来る
第2章 人生を変えた本
第3章 ユニックスを学ぶ
第4章 三台目のコンピュータ
第5章 プログラミングの美しさ
第6章 ターミナル・エミュレーション
第7章 誕生
第8章 アップロード
第9章 著作権の問題
第10章 ミニックス対リナックス
第11章 ウィンドウとネットワーク
第12章 恋人!
第3部 舞踏会の王
第1章 初めてのアメリカ
第2章 商標登録
第3章 就職
第4章 シリコンバレーにようこそ
第5章 リナックスの成功
第6章 不協和音
第7章 株式公開
第8章 コムデックス
第9章 リナックス革命は終わったか?
第10章 押しつけるな!
第11章 舞踏会
第12章 サポート
第13章 知的財産権
第14章 コントロール戦略の終焉
第15章 楽しみが待っている
第16章 なぜオープンソースこそ筋が通っているのか
第17章 名声と富
終章 人生の意味Ⅱ
ブログはリーナス・トーバルズがオープンソースに対し、どう思っているのかに注目しました。
第3部 舞踏会の王
第16章 なぜオープンソースこそ筋が通っているのか
●『IBMがパーソナル・コンピュータを開発したとき、何気なく、そのテクノロジーをオープンにしたので、誰でも複製を作れるようになったんだ。そのたった一つの行動は、PC革命に拍車をかけただけじゃなく、やがて情報革命、インターネット革命、ニュー・エコノミ―(なんと呼ぶにせよ、いま世界中で大きな変化を引きおこしているもの)を順に呼び寄せる結果となった。
これは、オープンソース精神から生み出される限りない利益というものを、もっともよく表している。IBM PCはオープンソースのモデルとして開発されたわけじゃないけど、オープンにされたことで、個人や企業が互換機を作り、改良し、売ることができるようになり、オープンソース・テクノロジーの好例となったんだ。
オープンソース・モデルの一番純粋な形では、誰でもプロジェクトの開発や市場性開発などに参加できる。リナックスは明らかにそのもっとも成功した例だ。ヘルシンキのぼくの散らかった寝室から始まり、成長して、有史以来最大の共同プロジェクトにまでなった。その始まりには、コンピュータのソースコードは自由に共有すべきだと信じるソフトウェア開発者に共通の理念があった。その裏付けとなったのが、この運動の強力な武器としての一般公有使用許諾書(GPL―旧来的な著作権に反対するもの)だった。リナックスは発展し、最高のテクノロジーを開発し続ける一つのモデルになった。そして、リナックスがウェブ・サーバー用OSとして次々と採用されていることや、株式公開での予想外の好評でもわかると思うけど、リナックスはさらに発展して、広く市場に受け入れられるようになったのだ。』
●『オープンソースという手法を人々が初めて耳にしたとき、それはばかげたものに聞こえたようだ。だから、オープンソースの長所が理解されるのに何年もかかった。
ぼくらは理念があって、オープンソースを売り込んだわけじゃない。オープンソースこそ最高のテクノロジーを開発し、改良する最良の方法だとわかってきたので、その理念が世間の注目を集めだしたのだ。
いまや、その理念は市場で評価を得つつあり、その評価のおかげでオープンソースがますます受け入れられるようになってきている。さまざまな付加価値サービスをおこなう会社が作られるようになり、それらの会社はテクノロジーを普及させる手段としてオープンソースを利用することができた。お金が転がりこむと、世間は信じるようになるもんだ。
オープンソースというジグゾーパズルの中で、一番理解されていないピースの一つは、どうしてこんなに大勢のプログラマーが、まったくの無報酬で働こうとするのかってことだろう。
順序として、その原動力について述べておこう。多少なりとも生存が保証された社会では、お金は最大の原動力にはならない。人は情熱に駆り立てられたとき、最高の仕事をするものだ。楽しんでいるときも同じだ。これは、ソフトウェア技術者だけじゃなく、劇作家、企業家にも当てはまる真実だ。オープンソース・モデルは、人々に情熱的な生活を送るチャンスを与える。楽しむチャンスも、さらに、たまたま同じ会社で机を並べている数人の仲間とではなく、世界で最も優秀なプログラマーたちと仕事をするチャンスも、オープンソースの開発者たちは、仲間からいい評価を得ようと懸命に努力する。こうしたことは大きな原動力になるに違いない。』
●『オープンソース現象を理解する一つの方法がある―それは、何世紀も昔(現代の話しではないけれど)、科学が宗教界からどのように見られていたかを考えることだ。科学は、最初のうち、何か危険で、破壊的で、反対体制的なものと見なされた―ソフト会社は時々、オープンソースをそんなふうに見ている。科学は宗教体制を攻撃しようとして生まれたわけじゃなかった。それと同じように、オープンソースだってソフトウェア体制を破壊するために考えだされたわけじゃない。オープンソースは、最高のテクノロジーを生み出すために、そしてそのテクノロジーがどこに行くかを見守るために存在するんだ。』
●『オープンソースは理にかなっている。人々は、言動の自由について、屁理屈をこねたりはしない。自由こそ、人々が生命をかけて守ってきたものなのだから。自由はいつでも、生命をかけて守るべきものだ。しかし、はなっから自由を選択するのもまた簡単なことじゃない。オープンソースについても同じことがいえる。オープンにするかどうか、決定を下さなくてはならない。最初からオープンにするという立場に立ってみると危なっかしくてしようがないが、実際にやってみると、その立場はずっと安定したものになっている。』

画像出展:「レバテックキャリア」
Linuxとは?
Linuxの将来性は?
Linuxが利用されている分野
Linuxの特徴、メリット etc
ご参考2:“Android (オペレーティングシステム)”

画像出展:「Wikipedia」
『Androidは、Googleが開発した汎用モバイルオペレーティングシステムである。Linuxカーネルやオープンソースソフトウェアがベースで、主にスマートフォンやタブレットなどのタッチスクリーンモバイルデバイス向けにデザインされている。』
※カーネル:OSの中核。基本機能を担う部分。

画像出展:「ZDNET」
『今やLinux Foundationは、Linux以外にも1000以上のオープンソースプロジェクトを抱えている。しかし、昔からこうだったわけではない。2007年に設立された頃のLinux Foundationは、ほぼ完全にLinuxのためだけの団体だった。当時からずっとLinux Foundationのエグゼクティブディレクターを務めているJim Zemlin氏は、先日ウェブで公開されたDell Technologiesのデベロッパーコミュニティ担当マネージャーBarton George氏との対談の中で、同財団は創設に関わった人々の想像をはるかに超えて拡大してきたと語った。』
追記:Linuxのシェア 2025年8月21日

画像出展:「AI(Perpflexity)が作成」
気になることがあって、AIにLinuxのシェアを聞きました。
PCはWindowsの牙城ですが、サーバーとモバイルは約70%ということです。
HP-UXというUNIXサーバーを営業していて、Linuxが出はじめた時に、これは「強敵だな~」と思ったことが懐かしく思い出されます。
生成AIの可能性
AIとは人工知能(Artificial Intelligence)ですが、そもそもよく分かっていません。特に知りたいことはビジネスに対するインパクトの大きさです。一過性の盛り上がりなのか、“クラウド”のように主流としてITビジネスをリードしていくような革新なのかということです。
購入したニュートン別冊は、2018年5月発行なので少々古いのですが、図表も多く内容的にも興味深いものでした。

編集:中村真哉
発行:2018年5月
出版:(株)ニュートンプレス
生成AI(Generative AI)については、NRI(野村総合研究所)さまのサイトをご紹介させて頂きます。“生成AIとは” 3分40秒の動画もあり、大変勉強になります。
こちらのDOORSの寄稿は非常に具体的です。(執筆者はブレインパッドの高田洋平様です)
ブログで取り上げたのは目次の黒字の個所です。
目次
1 基礎から学ぶ人工知能
●人工知能の分類
●人工知能の歴史
●ヒトとコンピューターの画像認識①~②
●ヒトの視覚野のしくみ①~②
●ディープラーニング
●機械学習①~②
●ディープラーニングの未来①~②
2 人工知能の最新応用技術
●人工知能の進化
●将棋プログラム
●アルファ碁
●保健医療分野におけるAIの活用
●人工知能の病理診断
●人工知能の内視鏡検査
●人工知能の眼底検査
●自動運転 ※ばっちゃまの米国株
●人工知能のひび割れ点検
●人工知能の惑星探査
3 人工知能の未来
●人工知能とセキュリティ
●人工知能と公平性
●人工知能とプライバシー
●汎用人工知能①~②
●シンギュラリティ
4 人工知能の新領域へ
●インタビュー 山川 宏博士
人間と調和できる人工知能をつくりたい
●インタビュー 金井良太博士
AIに意識をもたせることで意識の本質にせまりたい
●インタビュー 山本一成氏
AIが将棋の可能性を広げてくれた
●インタビュー 坊農真弓博士
「ロボットは井戸端会議に入れるか」会話にあるルールを解き明かしたい
●インタビュー 井上智洋博士
AIが人間を仕事から「解放」してくれる
●インタビュー 佐藤 健博士
AIに裁判の結果の理由を説明させる
●インタビュー 平野 晋博士
AIに常識や倫理観、感情は必要か
1 基礎から学ぶ人工知能
●ヒトとコンピューターの画像認識①~②
私たちは、どのように画像を認識している?
・自動運転や医療診断に欠かせないのは画像認識です。この画像認識を可能にし、人工知能の飛躍的進化をもたらしたのが「ディープラーニング」です。例えば、イチゴを見た瞬間にすぐにイチゴだと分かるのは、眼から入った視覚情報が脳の後方(後頭葉)にある「一次視覚野」に送られ、さまざまな情報と統合されてイチゴと認識されるからです。
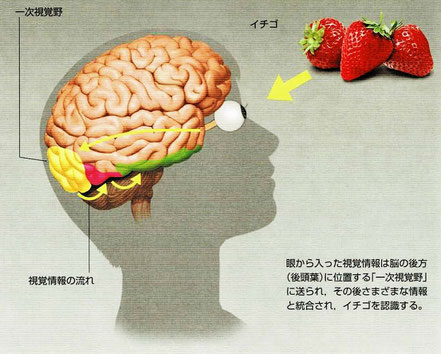
画像出展:「ゼロからわかる 人工知能」
コンピューターはディープラーニングで特徴を抽出
・従来のコンピューターは、足し算や掛け算などの計算を大量に行うことはできますが、瞬時にイチゴをイチゴであると認識することはできません。
・ディープラーニングはイチゴの画像をすべて数値化し膨大な計算を行うことで、イチゴの特徴を抽出します。
まず、イチゴの画像を非常に細かい画素(ピクセル)に分け、その画素が画像のどこに位置するのかといった「位置情報」と、その画像は何色なのかといった「色情報」を持った数値として処理します。イチゴの画像もコンピューター内では、ただの数学の羅列というわけです。
・イチゴの特徴には、「表面につぶつぶがある」「丸みをおびた三角の形をしている」といった特徴があります。これらの特徴を抽出する必要があるのですが、従来の人工知能ではこの「特徴の抽出」を行うことは難しく、研究者が人工知能に「イチゴとは赤いもの」「イチゴには緑色のへたがついている」など逐一、ルールを教える必要がありました。しかしながら、イチゴの特徴を完全に言語化することは不可能であり、精度よく認識できる人工知能を開発することはできませんでした。
・ディープラーニングでは、脳の構造を模した「ニューラルネットワーク」という方法を用いて、特徴を自動で取り出すルールを自ら獲得することができます。つまり、「特徴の抽出」を行うことができるのです。
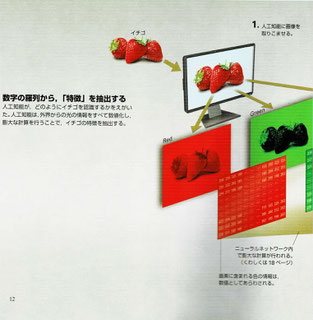

●ディープラーニング
コンピューターの中に神経網をつくりだす「ディープラーニング」
・ニューラルネットワークとは神経回路を模してつくられたシステムです。
・ニューラルネットワークは、データを受け取る「入力層」、学習内容に応じてネットワークのつながり方を変える「隠れ層」、そして最終データを出す「出力層」に分けられます。それぞれの層は、「ノード」とよばれる仮想的な領域からなります。ノードでは以下のような計算が行われ、流れる情報の量が制御されます。

画像出展:「ゼロからわかる 人工知能」
これは、人間におけるニューロンのはたらきに相当します。このニューラルネットワークを何層にも重ねる(深くする)ことで作られるシステムが「ディープラーニング」です。ディープラーニングは脳の視覚野と同じように、入力層に近い部分では単純な形しか判別できません。しかし層を重ねることで、より複雑な特徴を得ることができます。そして最終的にコンピューターは、イチゴそのものの概念を手に入れることができるようになります。このようにディープラーニングは、視覚野が行う情報処理のしくみに非常に似ています。
●機械学習①~②
人工知能の“学習”とは、出力結果と正解との誤差小さくすること
・人工知能は、最初は画像からイチゴの特徴を正しく抽出することも、正しい重みづけをすることもできないので、人工知能はイチゴとリンゴを判別することはできません。そこで、分類した結果の答え合わせを行い、正解との誤差を小さくできるように、重みづけを変えていきます。
コンピューターが“学習”するしくみを見てみよう
・「機械学習」とは、人工知能に試行錯誤を繰り返させ、正しい結果が出せるようにノードとノードの重みづけ徐々に変化させていくことを指します。
・イチゴとリンゴを分類する方法を見てみます。
-学習前の人工知能は重みづけがないので、イチゴがもつ特徴が何か(画像のどこに注目するか)も分かっていません。
[STEP1.画像入力]:イチゴの画像を入力する。この画像には「イチゴ」のレベルが貼られている。
[STEP2.分類]:初期段階では、リンゴとイチゴを分類する特徴が抽出できず、適切な重みづけも不明である。人工知能はすべてを足し合わせ平均をとる。
-人工知能が間違ってリンゴと判定したとしましょう。
[STEP3.結果の出力]:リンゴである確率とイチゴである確率を比較し結果を出す。今回の場合は50%なので判別できない。
-正しい答え(イチゴ)を導き出せるように調整を加えていきます。
[STEP4.答え合わせ]:画像に貼られているラベル(「イチゴ」)と出力結果を突き合わせる。そして、答え合わせの誤差が小さくなるように、人工知能は自ら線の重みづけを変えていく。その結果、抽出される特徴も変わっていく。これが「機械学習」である。ディープラーニングの場合、出力層から入力層に向けて、多くの隠れ層をさかのぼってすべての重みづけを変更していく。

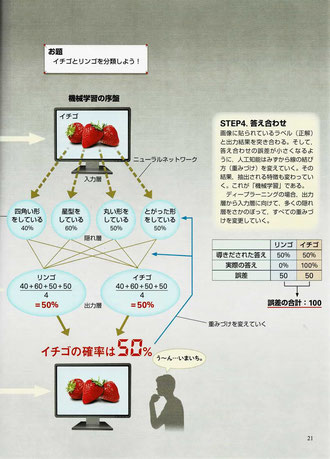
インターネットの拡大が人工知能を賢くした
・人工知能は、何百枚、何千枚と学習を繰り返すことで、徐々に正しい答えを導き出せるようになります。
[STEP5.多くの画像を入力]:人工知能に機械学習を行わせるために、リンゴとイチゴの画像を数多く入力する。このときも、リンゴの画像には人間によって「リンゴ」、イチゴの画像には「イチゴ」と正解ラベルが貼られている。
[STEP6.学習によって適切な特徴と重みづけを得る]:数多くの画像について一つずつ、分類しては答え合わせを行うことで、誤差を小さくしていく。今回の場合、当初の誤差の合計は100だったのに対し、機械学習を繰り返すことで、誤差の合計が30になっていることが分かる。このような計算によって、人工知能は適切にリンゴとイチゴを分類することができるようになる。
・長年、ディープラーニングは実用に耐えるほどの精度が出せないという問題を抱えていました。その理由は、層が深くなるにつれて、答え合わせの結果がうまく隠れ層に伝わらず、重みづけを最適化できなかったためです。
しかし近年、答え合わせの方法を改良したり、本格的な機械学習を行う前に、人工知能を“プレトレーニング”したりすることで、非常に効率よく学習を行うことができるようになりました。
また、インターネットの拡大とともに、使用できる画像データが爆発的に増えたことで、容易に機械学習を行うことができるようになったり、人工知能が行う計算に特化したプロセッサ(中央処理装置)の開発が進んだりしたことも、現在、人工知能の性能が劇的に向上している大きな要因です。


●ディープラーニングの未来①~②
ディープラーニングの活用例
・声の正体は「音波」であり、周波数という数値で表すことができます。この周波数を人工知能に取り込ませることで、「音声認識」が可能になります。iPhoneのSiriなどが該当します。
・日本語や英語の単語は「文字コード」として数値に置き換えられ、翻訳のような「自然言語処理」に利用されています。2016年、Google社はウェブ上で利用できるGoogle翻訳にディープラーニングを用いることで、翻訳の精度を劇的に向上させました。
・囲碁ソフト「AlphaGo」もディープラーニングを用いています。AlphaGoはそのメカニズムは過去のプロ棋士同士の対局中に現れた膨大な石の配置パターンを読み込むことで、その場面における自分が有利か不利かを判断しています。
AlphaGoを開発したイギリスのDeepMind社は更に2017年10月、囲碁ルールのみを与えた「AlphaGo Zero」が40日という短期間で、従来のAlphaGoのどのバージョンよりも強くなったことを発表しました。AlphaGo Zeroで用いられた手法は「強化学習」というものです。強化学習では、研究者は人工知能に過去の対局記録や正しい手筋を教えません。そのかわりに、人工知能同士で対局を行わせ、より多く勝てる打ち筋に「報酬」を与えます。人工知能が自ら、より多くの報酬を得られる、つまりより多く勝てるように試行錯誤して最適な打ち筋を学習していくのです。過去データを用いることなく強くなったことを示すこの結果は、もはや人工知能が人類の手をはなれて進化し続けることを示唆しているといえるかもしれません。

未来を見通すことも可能になりつつある人工知能
・これまでのディープラーニングは主に、静止画像のような「静的な(時間の流れをともなわない)」情報に対して用いられてきました。しかし、動画のように先の展開を予測する必要がある情報の場合、従来のディープラーニングを用いることはできません。
そこで最近、注目を集めている技術が「リカレント・ニューラルネットワーク(RNN)」です。「リカレント」とは「循環する」という意味で、今の時刻の情報を処理する際に、少し前の時刻の情報と統合したうえで処理し、出力することを意味します。少し前の自分の状態に学ぶしくみだということもできます。
私たちは、時々刻々と変化する風景をとらえ、物体の動きを予測し、次の行動を決定します。たとえば正面からボールが飛んできた場合、私たちは反射的によけることが可能です。しかし現在の人工知能は、このような当たり前の予測を行うことができません。なぜなら、ボールが動く映像の実体は、静止画を1枚1枚コマ送りしたものにすぎず、それぞれの静止画のつながりを理解することはむずかしいためです。人工知能にとって「時間」を理解することは困難なのです。
私たちの脳内では、ボールの視覚情報が一次視覚野から二次視覚野、そして高次視覚野へと伝えられる一方で、高次視覚野から一次視覚野へと“逆流”する信号もあるといいます。これは、先に伝わった情報と後から来た情報を統合することで、物体の動きを補正し、正確にとらえるためだと考えられています。この“情報の逆流”を人工知能に搭載した技術がRNNであるといえます。
2 人工知能の最新応用技術
●人工知能の進化
人工知能が動作や言葉を理解し、社会に進出していく
・人工知能は新しい能力を獲得するたびに、人工知能が活躍する領域は広がっていくと考えられます。特に、動作に関連する概念は、ロボットが人間社会で実現に行動するためには必須の能力だといえます。
能力1.画像を正確に見分けられる
能力2.複数の感覚データを使って特徴をつかむ
・今後は人工知能も、視覚情報に温度や音などの情報も組み合わせて、抽象的な概念を理解できるようになります。
能力3.動作に関する概念を獲得する
・「ドアを開ける」といった、自分の動作(例えばドアを押す)とそれがもたらす結果(ドアが奥に開く)を組み合わせた概念です。これらの動作の概念がないと、ロボットは行動計画を立てることができません。
能力4.行動に通じた抽象的な概念を獲得する
・例えば、ガラスのコップは硬いといった抽象的な概念(感覚)は、さまざまな材質のコップを実際に触ったり、落として壊したりすることで獲得できます。こういった感覚は、人間とともに暮らして家事や介護を行うロボットには必須です。
能力5.言葉を理解する
・音声認識や自動翻訳などの言語に関する能力はかなり進んでいますが、まだ人間と同じように言葉を理解しているわけではありません。
能力6.知識や常識を獲得する
・言葉が理解できると、人工知能はインターネット上の情報などから知識や常識を獲得することができるようになります。
3 人工知能の未来
●汎用人工知能①~②
汎用人工知能では、脳をまねてモジュールをつなぎ合わせる
・今の人工知能は、ディープラーニングなどのニューラルネットワークを使用した「モジュール」(プログラムの構成単位)をいくつか組み合わせることでできています。現在は、人間が特定の問題に応じてモジュールを組み合わせて人工知能を設計しています。つまり、その問題しか解けない設計になっています。それに対して、全能アーキテクチャが目指す「汎用人工知能」は、私たちの脳が普段から行っているように、必要に応じて複数のモジュールを自動的に組み合わせることを目指しています。臨機応変に自分自身の設計(プログラム)を変えることで、さまざまな問題を柔軟に解決できるようになります。
・現在の開発状況から見て、人間と同程度の能力をもつ汎用人工知能は2030年頃に完成するのではないかという声が出ています。

画像出展:「ゼロからわかる 人工知能」
大脳基底核や大脳皮質のほか、運動に関わる小脳に相当する人工知能の開発は比較的進んでいますが、海馬に相当するものや、それらを統合するための人工知能の開発は遅れています。
未知の状況に対応する能力をもつ汎用人工知能は、自律的な行動が求められる「災害救助ロボット」や「惑星探査機」などに応用されることが期待されています。
・モジュールは、脳の各部位や領野に対応するプログラムです。全脳アーキテクチャでは、各モジュールを必要に応じてさらに細かい機能に分類して、それらを統合することで、人間の脳と同じような機能を実現する汎用人工知能を目指しています。
●シンギュラリティ
シンギュラリティの到来時期は賛否両論
・「シンギュラリティ(singularity)」は技術的特異点と訳される。人工知能が自分自身で猛烈な進化を続けると、人間の知能を追い抜き、遂には人類がその先の変化を見通せない段階まで進化するという説があります。これはアメリカの人工知能研究者であるレイ・カーツワイル博士が2005年に発表した著書『シンギュラリティは近い』によって世界に知られるようになりました。

画像出展:「ゼロからわかる 人工知能」
・あと数十年でシンギュラリティがやってくるという説には否定的な意見は少なくありません。しかしながら、時期は分かりませんが人工知能がこのまま進化することで、あらゆる分野で人間の知能を上回る時代がいずれやってくることについては、人工知能研究者の多くが同意しているようです。
4 人工知能の新領域へ
●インタビュー 平野 晋博士
AIに常識や倫理観、感情は必要か

画像出展:「ゼロからわかる 人工知能」
『AIネットワーク社会推進会議で取りまとめられた「国際的な議論のためのAI開発ガイドライン案」。AIの著しい発展を受け、近い将来、社会にAIネットワークが構築されることを前提として検討された九つの開発原則である。ただし、このガイドライン案はあくまで指針案であり、法的な拘束力はない。』

総務省の“AIネットワーク社会推進会議”は平成28年からのようです。
感想
『AIは新しい能力を獲得するたびに、AIが活躍する領域は広がっていくと考えられます』これが全てのように思います。
過熱状態は落ち着き、浮き沈みはあるでしょうが、生成AIはクラウドに匹敵するようなITを長期的に牽引する革新になるだろう思います。
開発環境あるいは開発支援のサービスも充実してきています。AIをリードしているNVIDIAといえばGPUという汎用型のAIアクセラレーターで有名ですが、各ニーズに対応した特化型のAIアクセラレーターも登場しています。CPUの両雄(IntelとAMD)も動いているようです。特にAMDは2023年6月にMI300Xという汎用型GPU(GPGPU)を発表しました。Big TechのMetaも、Google、Amazonに続きAI用の独自チップの開発を発表しました。さらに、テスラは独自に設計したチップとインフラストラクチャを使用したカスタムスーパーコンピューター“Dojo”を発表しました。
ソフトウェア、ハードウェアの進歩は止まることはありません。世界中の研究者によって新しい技術が“今”を変えていきます。そして、人工知能のニーズは医療、介護、小売、運輸、災害支援、宇宙開発など多岐に渡ります。
仮想空間はアバターを利用してネット上で交流する“メタバース”に進化しました。通信では5Gに続く、“Beyond5G(6G)”は2030年頃と目されているようです。
シンギュラリティが本当にやってくるのか、それはいつか、不安もありますが、おそらく人類の進歩の歴史の中で、それは避けられないのではないかと思いました。
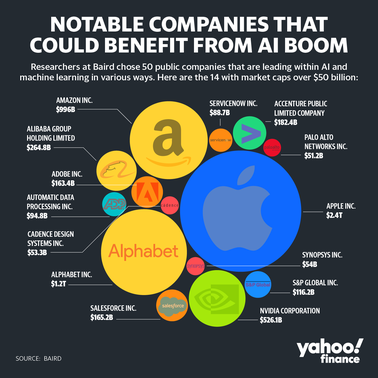
画像出展:「yahoo finance」
円の大きさは時価総額で、AI関連で500億ドル以上の会社を集めたものです。
何故か、”Meta”が入っていませんね。気になってさらに調べてみました。↓
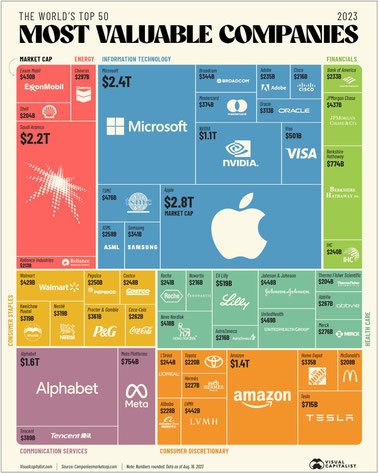
画像出展:「Linkedin」
こちらは2023年、全業種になっています。
やはりMeta(左下)はありました。

画像出展:「Yahooニュース」
米議会は9月13日、テスラのイーロン・マスクCEOのほか、メタ・プラットフォームズのマーク・ザッカーバーグCEO、アルファベットのスンダー・ピチャイCEOらテクノロジー業界の幹部を招き、人工知能(AI)に関するフォーラムを開催した。写真は、米議会で開かれたAIフォーラム(2023年 ロイター/Leah Millis)
『上院民主党トップのシューマー院内総務はフォーラムの冒頭「超党派のAI政策の基盤を整備するという巨大で複雑、かつ重要な取り組みをきょう開始する」と表明。「議会が役割を果たさなければ、AIの恩恵を最大化することも、AIのリスクを最小化することもできない」と述べた。
また、とりわけディープフェイクについては優先的に対応し、2024年の選挙前に規制する必要性があると強調した。
フォーラムは非公開で開催。60人を超える上院議員のほか、エヌビディアのジェンスン・ファンCEO、マイクロソフトのサティア・ナデラCEO、IBMのアービンド・クリシュナCEO、マイクロソフト創業者のビル・ゲイツ氏らも参加した。』
※2025年5月16日:“テスラ オプティマス ロボットがダンスを学習”

2025年5月、テスラのヒューマノイドロボット「Optimus(オプティマス)」は、ダンス動画や工場での実用的な作業能力を披露し、ロボティクス業界で再び注目を集めています。しかし、世界中のライバル企業も独自の強みを武器に追い上げており、「ヒューマノイドロボット戦争」は新たな段階に突入しています。
DPCcarsによる動画です。(2分48秒)
ティム・クックのApple
多くの人がそう思っていたのではないでしょうか。スティーブ・ジョブズを失ったアップルの将来は厳しいだろうと。ところが実際にはそうはならず、アップルはより大きな企業になりました。その立役者はCEOのティム・クックです。
「どんな人物なんだろうか?」、「スティーブ・ジョブズとティム・クックを結びつけたのは何だったのだろうか?」。特に後者は最も知りたい“謎”でした。
また、スティーブ・ジョブズの自伝にあった“こだわり”も気になりました。この点からも、何故、ジョブズはティム・クックだったのか知りたいと思いました。

画像出展:「スティーブ・ジョブズⅡ」
『僕は、いつまでも続く会社を作ることに情熱を燃やしてきた。すごい製品を作りたいと社員が猛烈にがんばる会社を。それ以外はすべて副次的だ。もちろん、利益を上げるのもすごいことだよ。利益があればこそ、すごい製品は作っていられるのだから。でも、原動力は製品であって利益じゃない。スカリーはこれをひっくり返して、金儲けを目的にしてしまった。ほとんど違わないというくらいの小さな違いだけど、これがすべてを変えてしまうんだ―誰を雇うのか、誰を昇進させるのか、会議でなにを話し合うのか、などをね。』[スティーブ・ジョブズⅡp424](上記のメッセージはブログの2.「最後にもうひとつ……」の先頭に出ています)

画像出展:「ティム・クック」
著者:リーアンダー・ケイ二―
訳者:堤沙織
出版:SBクリエイティブ
発行:2019年9月
ブログは目次に続き各章のごく一部をご紹介していますが(黒字)、これ以外に印象的だったクックの成果として、[慈善活動に対する積極的な取り組み]、[再生可能エネルギーへの移行]など、スティーブ・ジョブズの時代には、消極的だったこれらの課題に対しても素晴らしい成果をあげられていました。
目次
序論 うまくやってのける
第1章 スティーブ・ジョブズの死
クックは取るに足りない人物
ジョブズが辞任し、クックがCEOに
スティーブ・ジョブズの死
スティーブ・ジョブズの会社を経営する
破滅する運命のアップル
第2章 アメリカの深南部で形作られた世界観
スウィートホーム・アラバマ
学生時代
早期のビジネス経験
ロバーツデールがクックの世界観を築いた
アラバマ行動主義のルーツ
故郷のアンチヒーロー
オーバーンで工学を学ぶ
第3章 ビッグブルーで業界を学ぶ
IBM PC
リサーチ・トライアングル・パークの工場
ジャストインタイム生産方式
クックの初めての仕事
クックの高い潜在能力
クックのMBA
早期の倫理規範
IBMのソーシャルライフ
IBMでの昇進
インテリジェント・エレクトロニクスに転職する
コンパックに合流する
第4章 倒産寸前の企業に加わる、一生に一度の機会
意見の一致:クック、ジョブズに出会う
オペレーションの新たなリーダー
さよなら、アメリカ。こんにちは、中国!
第5章 アウトソーシングでアップルを救う
フォックスコン
とんとん拍子に出世する
マネージャーとしてのクック
第6章 スティーブ・ジョブズの後を引き継ぐ
ピノキオ並みの硬さ
初期の挫折
採用と解雇
アップルは全盛期を過ぎたのか
クックはアップルの変革を始める
サプライチェーンにおける取り組み
成功の兆し
第7章 魅力的な新製品に自信をもつ
脱税
MacProとiOS7
iPhone 5Sが記録を打ち立てる
良い年末
世界開発者会議―iOS8と健康部門への参入
アンジェラ・アーレンツティム・クックのティム・クック
驚くべきパートナーシップ
IBMとのパートナーシップ―法人向けiOS
iPhone 6とApple Pay
iOS 8.0.1の厄介なバグ
Apple Pay
クックの初の主要製品:Apple Watch
第8章 より環境に優しいアップル
汚染と中毒
良い方向へ進む
ダーティな仕事に取りかかる
環境保護庁の門をたたく
善行を促進する力
クックは太陽光発電に力を注ぐ
クローズドループのサプライチェーン
持続可能な森林
ひたむきなCEO
第9章 クックは法と闘い、勝利する
プライバシーの問題
サンバーナーディーノ
長期にわたる論争
抗議の嵐
作戦指令室
アメリカにパライバシーは存在しない
訴えを取り下げる
クックはプライバシーを強化する
第10章 多様性に賭ける
パーソン・オブ・ザ・イヤー
平等と多様性はビジネスの役に立つ
多様性による革新
女性を昇進させる
アップルの組織構成
株主からのプレッシャー
教育におけるクックの取り組み
早いうちに種をまく
アクセシビリティ
第11章 ロボットカーとアップルの未来
未来の取り組み
アップル・パーク
キャンパスがオープンした日
すべてが成功したわけではない
協調を促す
うまくいっているようだ
次世代iPone、Xの到来
第12章 アップル史上最高のCEO?
クックは革新できるのか?
革新には時間がかかる
教訓を得る
第1章 スティーブ・ジョブズの死
破滅する運命のアップル
・2014年9月:チャーリー・ローズ[ニュースキャスター]とのインタビュー
『クックはジョブズが残したものを何とかして維持し、自分の持つすべてを会社に注ぎ込むことを望んでいた。しかし、ジョブズの真似をしようと考えたことはなかった。「自分がなれるのは、自分自身だけだということを理解しています」と彼は続けた。「私は最高のティム・クックになるように努力しているのです」そして、これこそが、彼の成し遂げたことだった。
第2章 アメリカの深南部で形作られた世界観
学生時代
・ロバーツデールは典型的な南部アメリカの田舎町。面積はわずか13平方キロメートル。当時の人口は約2300人(現在は約5000人)。
・クック家は信仰に篤く、クリスチャンである。
・幼い頃に、バプテスト教会で洗礼を受けてから、信仰は人生の大きな部分を占めてきた。
・クックは控えめで向上心が高く、常に成績優秀な生徒だった。知的で穏やかな性格でユーモアのセンスもあった。
・『彼がアップルで実践した価値観の多くは、子どもの頃に経験した差別と直接結びついているようだ。2013年、デューク大学フュークア・スクール・オブ・ビジネス(クックはここで修士号を取得している)で行われた学生向けの講演会で、クックは、キング牧師とケネディ大統領の2人が子どもの頃からのヒーローだと語っている。「私は南部で生まれ育ち、成長の過程で、差別が引き金となった最悪の行動の数々を目にし、非常に気に病む思いをしてきました」と、彼は学生たちに語った。だからこそ、命がけで差別と戦ったキングとケネディを、心から尊敬しているのだろう。』
オーバーンで工学を学ぶ
・『「アラバマ大は医師や弁護士を志望する富裕層が行くところだったので、自分を労働者階級の1人だととらえていた私には適さないと思いました。そして労働者階級の人々は、オーバーンへ行っていたのです」』
・クックが学んだ生産工学は、複雑なシステムを最適化する方法に焦点を置き、無駄な支出を取り払い、資源を最大限活用する最善策を見つけ出す学問であった。
・クックは2010年、オーバーン大学の卒業式のスピーチで、オーバーン大学の理念を自分の信念として話しているが、それは次のようなものである。『「私はここが、実践的な世界であると信じており、ゆえに、自分が培ったもののみが信頼に値すると考えている。したがって私は、働くこと、ひときわ懸命に働くことの価値を信じる。私は、正直であることと、誠実であることの価値を信じる。それなしでは、仲間の尊敬と信頼を勝ち取ることはできない」。』
・クックは1982年にオーバーン大学を卒業、アンダーセンコンサルティング(現アクセンチュア)とゼネラル・エレクトリックからもオファーを受けていたが、IBMに入社(PC部門)した。

画像出展:「WikipediA」
アラバマ州ロバーツデールは、2010年の国勢調査では人口5,276人、1,951世帯だったそうです。

第3章 ビッグブルーで業界を学ぶ
クックの高い潜在能力
・IBM入社数年後、クックは工場の経営幹部によって選ばれる「ハイポ(ハイ・ポテンシャル)」と呼ばれる将来を担う25名の若手社員リストのランキング1位にいた。なお、「ハイポ」に求められるものは、業績、責任感、リーダーとしての潜在能力など。
・『クックがハイポ・リストの一角を獲得し、最終的にはIBMでの高い地位[パーソナル・コンピューター事業北米ディレクター]を確立するまでになったのは、高校と大学を通して彼が培った労働倫理のおかげだった。工場におけるパーソナル・コンピューター製造の元責任者で、かつてクックの上司だったこともあるレイ・メイズも、クックが同僚たちの中で抜きんでていたことに同意している。「私が感じていた彼の優れたところは、その労働倫理でした」とメイズは語った。』
早期の倫理規範
・ビジネスで“倫理”というと、不正会計やインサイダー取引を連想するものだが、クックの“倫理”はそのようなものではない。
・『2013年、デューク大学で行われた同窓会[デューク大学のFuqua School of Businessを1988年に卒業]で、クックはこのように語った。
「倫理について考えるとき、私はある物事を、それを発見したときよりも良い状態で、後に残すことを考えます。そしてこのことは私にとって、環境への配慮から、労働問題を抱えるサプライヤーとの付き合い方、製品の二酸化炭素排出量、何を支援するかという選択、そして従業員の扱い方まで、すべてに関わることなのです。私のすべての言動は、この考え方がもとにあるのです」。
倫理学の講義によって、彼は同じ業界の人の多くとは異なる方法でビジネスを考えるようになった。彼がそこで学んだ教訓 ―発見したときよりも良い状態で、物事を後に残すこと。環境に配慮し、従業員に敬意をもって接すること― は、彼の信念の支えとなり、アップルCEOとしての任期を象徴するものとなるだろう。彼はIBMで、アップルにおけるリーダーシップの基礎となるものを築き始め、そこには同僚との交流も含まれていた。』

画像出展:「江戸切子協同組合」
私事ですが、早大サッカー部時代に「伝統とは、前年をひとつでも上回る成果を上げ、積み重ねていくこと」と教わったことを思い出しました。
この日本流の“伝統”は、クックの信念の支えとなった“倫理”とスティーブ・ジョブズが願っていた、“いつまでも続く会社”につながるキーワードではないか、ジョブズとクックを結んだ最も重要な価値観だったのではないかと思いました。
つまり、私が最も知りたかった“謎(二人を結んだもの)”とは、“伝統を重んじる心”だったというのが私なりの答えです。
第4章 倒産寸前の企業に加わる、一生に一度の機会
意見の一致:クック、ジョブズに出会う
・『ティム・クックは、アップルのリクルーターからオファーをすでに何度も断っていた。彼らの粘り強さが実を結ぶときがきた。最終的に、彼は少なくともジョブズには会うべきだという結論に達したのだ。「スティーブは、私がいる業界のすべてを作った人物でした。とても会ってみたかったのです。クックは2014年、チャーリー・ローズに対してこう暴露している。
彼はコンパックでの仕事に満足していたが、ジョブズとの出会いは新鮮でエキサイティングな将来の展望を彼に与えてくれた。ジョブズは「他の人とは全く異なることをしていました」とクックは当時を振り返った。その最初の面接で、ジョブズのアップルに対する戦略とビジョンを座って聞いていたとき、彼はそのミッションにおいて自分が価値ある貢献をできるということに納得した。ジョブズはコンピューター業界を震撼させることになるだろう製品や、いまだかつてないコンピューターのデザインコンセプトについて説明した。これらの構想は、丸くふくらんだ形のカラフルなMacintoshであるiMac G3となって、1998年に発売され大成功をおさめ、デザイナーであるジョニー・アイブを一躍有名にした。
クックは好奇心をそそられていた。「彼はそのデザインについてほんの少ししか話しませんでしたが、それだけで十分、私は関心を持ちました。後のiMacとなる製品について説明してくれたのです」。クックはその面接が終わる頃には、ジョブズのようなシリコンバレーの伝説と働くことは、一生ものの栄誉」になることを確信していた。』
第5章 アウトソーシングでアップルを救う
とんとん拍子に出世する
・入社4年後の2002年に、ワールドワイドセールスならびにオペレーション担当副社長になった。
・2004年にはMacintoshのハードウェア部門の責任者になり、2005年にはCOOに任命された。
・COOの昇進を機に、ジョブズはクックを自らの後継者として育て上げていった。アップルに勤めるすべての社員はスペシャリストだが、ジョブズとクックだけは違っていた。
マネージャーとしてのクック
・ジョブズとクックは何年もの間緊密に協力しながら働いてきたが、立ち振る舞い、気質、特にマネジメントは全く違っていた。
・『彼が声を荒げることはほとんどなかったが、問題の核心に迫ることに執着し、質問を延々と投げかけて人々を疲弊させた。「彼はとても静かなリーダーです」とジョズウィアックは語った。「叫ぶことも怒鳴ることもなく、非常に冷静で落ち着いています。しかしとにかく人を質問攻めにするので、部下たちは問題についてしっかりと把握しておく必要があるのです」。質問をすることで、クックは問題を掘り下げることができ、スタッフに自分がしていることを常に把握し、責任感を感じさせる効果があった。彼らはいつでも説明を求められる状況にあることを理解していた。
1998年12月に、クックのオペレーション担当グループに参加したスティーブ・ドイルは次のように語った。「彼は10の質問をしてきます。それらに正しく答えると、さらに10の質問をしてきます。それを1年経験すると、彼の質問は9つに減ります。しかし1つ間違えれば、質問は20、30と増えていくのです」。』
・クックは日曜日の夜に電話会議を受け、午前3時45分にメールの返信を行い、毎朝午前6時までには自分のデスクについていた。そしてオフィスで12~13時間働き、家に帰ってからはもっと多くのメールに返信した。
・クックは中国に行き、16時間の時差をものともせずに3日間働き、午前7時にアメリカに戻り、8時30分からの会議に出席することは珍しいことではなかった。
・オフィスにいない時のリラックス方法は、ジムに出かけるかロッククライミングをすること。また、熱心なサイクリストであり、土日はよく自転車に乗っているため、そのときだけは同僚はメールを気にせずにすんだ。
・クックは自分の健康状態を非常に気にかけていて、混雑する時間帯を避けるため、他の人より早起きしてジムに行っている。
・『彼は仕事とスポーツを同等のものと見なして次のように語っていた。「ビジネスにおいては、スポーツと同様に、勝利のほとんどはゲームの開始前に決定されているのです。我々は、好機がやってくるタイミングを整えることはできませんが、準備を整えておくことはできるのです」。クックの準備へのこだわりは、アップルにおける彼の成功の鍵である。』
・クックの最初の12年間のキャリアは比較的目立たないものだったが、クックは匿名でいることを重要視し、アップルの秘密のカーテンの後ろに隠れたままでいた。
第6章 スティーブ・ジョブズの後を引き継ぐ
成功の兆し
・2012年12月、クックは「タイム」誌の“世界で最も影響力のある100人」に選ばれたが、この記事の中で、アップルの元副社長で、2003年からは取締役を務めていたアル・ゴア[ビル・クリントン大統領時代の副大統領]は、クックに関して次のように記している。
『「伝説的存在であるスティーブ・ジョブズの後を継いで、アップルのCEOになること以上に難しい挑戦を私は知らない。しかし、アラバマ造船所の労働者と主婦の間に生まれ、穏やかで謙虚、物静かだが熱心な性格のティム・クックは、少しも動じることがなかった。ジョブズの残したものを守り抜き、アップルの文化に深く浸っている51歳のクックは、主要な方針転換を円滑かつ見事に実施しながら、世界で最も価値ある革新的な企業を、さらなる高みへと導くことに成功した。彼は、その複雑な社内構造の管理から、新たな「とてつもなく素晴らしい」テクノロジーおよびデザインの飛躍的進歩を製品パイプラインに落とし込むことまで、アップルのあらゆる分野において、自らのリーダーシップを強く発揮している」。』
第7章 魅力的な新製品に自信をもつ
世界開発者会議―iOS8と健康部門への参入
・2014年の世界開発者会議(WWDC)で新しいiOS8の発表に加え、HealthKitと組み合わせた健康管理アプリによって、1兆ドル規模のヘルスケア業界(健康とウェルネス分野)への参入を発表した。

画像出展:「biotaware」
”Apple ResearchKit, HealthKit and CareKit, Health App – what does it all mean?”
英語のサイトですが、Googl翻訳に助けて頂き、それぞれの概要をお伝えします。
◆HealthKit(アイコンは左端)
HealthKitは、ヘルスケアアプリとフィットネスアプリを格納するために設計されたフレームワークであり、それらを一緒に使用してデータをすべて1か所で照合できます。
◆ResearchKit(アイコンは左から2番目)
ResearchKitは、医学研究専用に設計されたオープンソースソフトウェアフレームワークです。ResearchKitを使用すると、医学研究者はアプリを迅速かつ最終的に開発し、このフレームワークから開発されたアプリを通じて有意義で価値のあるデータを取得できます。
◆CareKit(アイコンは右端)
CareKitは新しいソフトウェアフレームワーク(2016年4月にリリース)であり、これにより、開発者は、医療を追跡して管理する医学に特化したアプリを構築できます。作成されたアプリは、患者が自分の病状をよりよく理解して自己管理できるようにすることを目的としています。これは、たとえば、服用した薬の効果を追跡するのに役立ちます。

クリック頂くと株式会社C2さまの”ResearchKit/CareKit”のサイトに移動します。
『C2では、ResearchKitアプリおよびCareKitアプリの開発をお手伝いします。企画、要件定義、画面設計、開発 (アプリ&サーバ)、Appストア配信までをワンストップでサポートいたします。』
なお、事例として、京都大学さま、順天堂大学さま、国立がん研究センターさま等が紹介されています。
クックの初の主要製品:Apple Watch
・『アップルの幹部たちは、ジョブズの死から数週間後、ブレーンストーミングを始めた。つまりこの時計のアイデアは、スティーブの死から間接的に生まれたものだと言うことができる。「最初のディスカッションは、スティーブが亡くなった数カ月後2012年初めに行われました」とアイブは語った。「それには時間がかかりました。我々がどこに行こうとしていたのか、企業としてどんな軌道に乗っていたのか、そして何が我々のモチベーションとなっていたのかを、皆でじっくりと考えたのです」。そうして生まれたのがApple Watchだった。』
・これをみてスティーブ・ジョブズの伝記に書かれていた文章を思い出しました。

画像出展:「homestead」
『僕が病気になってある意味良かったと言えることは少ないけど、そのひとつが、リードが優れた医師とじっくりいろいろな研究をするようになったことだ。21世紀のイノベーションは、生物学[biology]とテクノロジーの交差点で生まれるんじゃないかと思う。僕が息子くらいのころデジタル時代がはじまったように、いま、新しい時代がはじまろうとしているんだ」』
第8章 より環境に優しいアップル
クローズドループのサプライチェーン
・2016年3月、アップルはiPhone6を分解するリアム(Liam)というロボットを発表し、クローズドループのサプライチェーン(製品の製造をリサイクルされた原料のみで行うこと)に向けた大きな一歩を歩み出した。現在、2機のリアムはアメリカとオランダに1機ずつあり、11秒ごとにiPhoneを完全に分解している。

画像出展:「マイナビニュース」
第9章 クックは法と闘い、勝利する
クックはプライバシーを強化する
・2018年4月に発表されたiOS11.3はプライバシー保護に強化を加えているが、このアップデートには、ユーザーの個人データがアップルのサービスによって収集されていることを明確に示すアイコンが追加された。アップルが個人情報を収集するのは、機能を有効にする必要があるときや、サービスを保護するとき、またはユーザー体験をパーソナライズする必要があるときだけである。
・アップデートしたユーザーへの通知は次のような説明がされていた。『「アップルはプライバシーを基本的人権だと考えているため、すべてのアップル製品はデータの収集と使用を最小限に抑え、可能な限りデバイス上で処理し、お客様の情報に対する透明性と管理を提供するよう設計されています」。』
第10章 多様性に賭ける
・クックは同性愛者である。この表明は2014年10月30日、ブルームバーグに掲載された「ティム・クックは語る」という感動的なエッセイの中で行われた。また、表明した理由など心に残るメッセージがある。
・『「私は自分自身がゲイであるおかげで、マイノリティであることの意味をより深く理解することができ、他のマイノリティグループに属する人々が日々直面している課題についても考えることができるようになったのです」。』
・『CBSの「ザ・レイト・ショー」に出演したクックは、自分がアメリカのセクシャアル・マイノリティの若者たちを助けることができると気づいてから、自らのセクシャリティを公表することを決めたと語った。「子どもたちは学校でいじめられ、その多くは差別され、両親から拒絶されています。私が何とかしなければならないと感じたのです」と彼は語った。「私は自分のプライバシーを非常に重視していましたが、他の人のために何かすることのほうが、それよりもはるかに重要と感じたのです。皆さんに私の真実を伝えたいと思いました」。』
第11章 ロボットカーとアップルの未来
未来の取り組み
・タイタンと呼ばれるプロジェクトは、Apple Carという自動運転車に関するもので2014年にクックが承認したプロジェクトである。そのきっかけはジョブズが、当時大きな話題となっていた、テスラモーターズの新たな電気自動車に興味をもった2008年にさかのぼる。(ジョブズは当時の自動車業界の状況から自動運転車を追及しない決断をくだしている)
・『2017年6月、クックはプロジェクト・タイタンについて初めて公に語り、ブルームバーグに対し、「自動運転システムに焦点を合わせている」ことを認めた。「これは、我々が非常に重要視する核となるテクノロジーです」。そしてクックはこう付け加えた。「我々は、これをすべてのAIプロジェクトの母であると考えています。おそらく現存するAIプロジェクトの中で、最も難しいものの1つです」。』
・タイタンの問題は製品開発だけでなく、雇用やマネジメント、そしておそらくビジョンにおいても失敗していると評価されており、軌道に乗っているのかいないのかさえ明らかになっていない。
Appleが自動運転車を開発していることは全く知らず、大変驚きました。しかし、その”タイタン”と呼ばれているプロジェクトは苦戦していることを知りました。
そこでネット検索してみると、【Patently Apple】という、Appleの知的財産(IP)や最新のニュースを発信するブログ(英語)があり、”タイタン”に関しても色々なニュースが掲載されているのを知りました。
第12章 アップル史上最高のCEO?
革新には時間がかかる
・クックのもとで発売された最初の新ジャンルの製品であるApple Watchは、当初は不信感をもって迎いられ、一笑に付されることもあり、初期の評価は面白いおもちゃではあるが、世界を変える製品ではないというものあった。しかし3年後、Apple Watchはスマートウォッチ市場で最大の勢力となり、スイスの時計業界全体よりも大規模となっていた。
・Apple Watchは、アップルの健康とウェルネスに対する熱意を形にしたプラットフォームであり、HealthKitやResearchKitのようなソフトウェアによって、着用者が自分の健康とフィットネスをモニターし、改善するのをサポートする手首装着型コンピューターの基礎を築いている。

こちらは、”お茶の水循環器内科さま”のサイトです。2020年9月7日に「アップルウォッチ外来」を開始されたとのことです。
『お茶の水循環器内科ではアップルの「家庭用心電計プログラム」「家庭用心拍数モニタプログラム」が医療機器承認を受けて、アップルウォッチ外来を開始しました。具体的には、不整脈の発作時の記録をもとに、不整脈の疑いの評価、さらなる精密検査の必要性、治療の必要性等を相談するものです。』
付記
《「スティーブ・ジョブズとティム・クックを結びつけたのは何だったのだろうか?」。特に後者は最も知りたい“謎”でした。》
この疑問に対する自分なりの答えは以下のようなものでした。
《この日本流の“伝統”は、クックの信念の支えとなった“倫理”とスティーブ・ジョブズが願っていた、“いつまでも続く会社”につながるキーワードではないか、ジョブズとクックを結んだ最も重要な価値観だったのではないかと思います。つまり、私が最も知りたかった“謎(二人を結んだもの)”とは、“伝統を重んじる心”だったというのが私なりの答えです。》
読み終わってみて、ジョブズとクックを結んだのは、もう一つ、幼少期の体験を通して”研ぎ澄まされた精神が潜在的に共鳴した”からではないかと思います。
労働階級の家に育ち、両親からの愛情に心をよせ、加えてジョブズは養子をバネに、一方クックは差別の多い南部の田舎町に住み、自分自身がセクシャルマイノリティであったことをバネに、強い気持ちや揺るぎない信念(ジョブズは父親譲りの完璧な物づくり、クックは確固たる倫理感)を醸成したのだと思います。
量子コンピューター誕生
【量子超越】(quantum supremacy)というのは、「量子コンピューターで従来のコンピューターにはできない計算をする」という意味の造語だそうです。
量子コンピューターが世界最速のスパコン(スーパーコンピュータ)を凌駕したという【量子超越】のニュースは、前々回のブログ“スマート・クリエイティブ”の中でご紹介しましたが、このGoogle の量子コンピューターのことは、日経サイエンスで特集されていました。

日経サイエンス 2020年2月号
出版:日経サイエンス
発行:2020年2月
量子コンピューターはたった53個の素子で世界最速のスパコンを超える計算を実行した。この計算能力を生かせるキラーアプリケーションの発見を目指して世界中で競争が始まっている。

画像出展:「日経サイエンス」
「前」世界最速のスパコン
米国立オークリッジ研究所にあるスパコン
サミット
・台数(ノード数):4608
・CPU数:9216
・メモリ:10PB(ペタバイト)
・ストレージ:250PB
・OS:Linux
2020年6月22日に富士通/理化学研究所の“富岳”が世界1位になったという発表がありました。


画像出展:「日本経済新聞」
性能比較
Google 社の量子コンピューター(53個の超電導量子ビット)

画像出展:「日経サイエンス」
チップの中身
量子コンピューターチップには、53個の超電導量子ビット(右)が格子状に並び、接続を制御する接続器でつながっている。1つ抜けているのは(上段中央の白いチップ)壊れて動作しなかったため。
この特集は技術的な解説が中心ですが、難解ということもあり、私の関心は“これからの見通し”と“量子コンピューターの扉を開けたのは誰か”という2点です。
前者は、「量子コンピューターが近い将来に世界を変えることはない。これは現在の量子コンピューターが計算できるのは特殊なものに限定されており、科学者や産業界が期待する実用的な計算ができるようになるかどうかは未知数である」ということでした。
東京大学の中村泰信先生は、『「今の延長で、2~3年のうちにおそらく200量子ビット程度まではいけると思う」』、とお話されています。
また、本誌には2つの視点から今後の課題が書かれています。
①『各ビットを制御するために必要な膨大な配線をどう処理するかが大規模化の課題になるという。よく巨大なシャンデリアのような量子コンピューターの写真を見かけることがあるが、あれは中心にある量子チップを冷やす冷凍機で、無数の金属線はそのチップの素子を制御する配線だ。』
②『エラーを訂正しながら計算が続けられる量子コンピューターを実現するにはあと20~30年かかると、研究者の多くはみている。それまではエラー耐性量子コンピューターを目指しつつ、エラー訂正できない小規模な量子コンピューター(これをNISQ[Noisy Intermediate-Scale Quantum device]と呼ぶ)で何か面白い計算ができないかを探索する研究が進むだろう。』
量子コンピューターは極めて興味深い技術革新ですが、まだまだツボミ、満開になるまでにはかなりの月日を要するようです。

画像出展:「日経サイエンス」
左はマルティニス教授(2017年12月、グーグル研究所)
後者の“誰が量子コンピューターの扉を開けたのか”という疑問は、オックスフォード大学の物理学教授、ディヴィッド・ドイッチュ(David Deutsch)先生というのが答えでした。日経サイエンスの記事の中にも誕生までの経緯に関するお話が出ていましたので、そちらをご紹介します。

・量子的に動作するコンピューターというアイデアが初めて注目を集めたのは1981年5月、IBMの計算機科学者ランダウア―(Rolf Landauer)が主催した「第1回物理と計算の国際会議」である。会議には著名な物理学者のファインマン(Richard Feynman)が招かれ、計算機による物理コミュニケーションについて講演した。そして「(量子力学以前の)古典力学を扱う解析はどれもうまくいかない。自然は古典力学では動いていないので、シミュレートするなら量子力学的にやるべきだ」と結論し、量子コンピューターの必要性を予言した。
・『ドイチュが1985年に量子コンピューターの動作を定式化した論文を出したときには、「反響はほとんどなかった」という。量子的な重さね合わせは今でこそ計算のリソースと捉えられているが、当時は量子力学を構成する理論上の枠組みだと思われていた。そんな実体のないものに情報を保存して計算するというのは突拍子もない話で、しばしば「幽霊を使って計算するコンピューター」と評された。
だが量子コンピューターの理論に関心を持つ人はじわじわと増えていった。1994年にベル研究所のシェア(Peter Shor、現マサチューセッツ工科大学)が量子コンピューターによって巣因数分解を桁違いの高速で解くアルゴリズムを提唱すると状況は一変し、大勢の研究者が流入して、第1次の量子コンピューターブームが起きた。』
※ご参考:量子論および「重さね合わせ」についての簡単な説明は、ブログ“スマート・クリエイティブ”の前半にあります。
・1982年ごろ、英オックスフォード大学のポスドク、ドイッチュ(David Deutsch)は、それまで数カ月にわたって進めてきた計算を終え、ひとつの結論にたどり着いた。今まさに理論を完成しつつある新しい計算機「量子コンピューター」は、まったく新しい計算をする。
『「それは特別な瞬間だった」とドイッチュは振り返る。「量子コンピューターの理論は、新しい計算の理論だとわかった」。
1985年7月、ドイッチュは量子コンピューターの理論を論文として発表し、その中でこう書いた。
「いつの日か量子コンピューターを作ることが技術的に可能になるかもしれない。おそらくは超電導回路の量子で」』
・34年後の2019年10月、グーグルの量子AIグループを率いるマルティニス(John Martinis)らが、超電導回路を使った量子コンピューターで、世界最速のスパコンで1万年かかる実験を200秒で実行したとNature誌に発表した。そしてこの劇的な加速によって「量子超越」が実験的に示されたと宣言した。
・マルティニスはカリフォルニア工科大学で行った講演でこう語った。「量子超越は、ソロバンから最先端のコンピューターまで、あらゆる計算機は同じクラスの計算をするという【拡張チャーチ・チューリングのテーゼ】への反論だ。量子コンピューターは、新しいクラスの計算をするデバイスなのだ」。ドイッチュの予想は30年余りを経て、マルティニスによって現実のものとなった。
※IBM社の反論:”Googleが世界で初めて実証した「量子超越性」にIBMが反論、量子コンピューターはシミュレートできるのか?” こちらはGigazineさまの記事になります。
※Google 社の計画:”米グーグルが量子コンピューターの野心的計画、10年以内に「万能」目指す” こちらは日経XTECHさまの記事になります。


画像出展:「Google Research」
こちらはGoogle Researchにあった”Quantum”というページです。左の絵は”The Question of Quantum Supremacy”につながります。また、”Quantum”のページには次のような説明が出ていました。『A research effort from Google AI that aims to build quantum processors and develop novel quantum algorithms to dramatically accelerate computational tasks for machine learning.』
卓越した才能をもったドイッチュ先生の著書の中に、「無限の始まり」という著名な本があることを知りました。
論外の難しさであるのは間違いなく、ページ数も600ページを超える大作のため買うつもりは全くなかったのですが、幸いにも、図書館に所蔵されていることを見つけました。
パラパラとページをめくっていると、400ページの“時間とは「もつれ」現象である”という見出しに続いて、量子コンピューターに関する記述がありました。ブログではその冒頭の部分をご紹介します。

著者:デイヴィッド・ドイッチュ
出版:合同出版
発行:2013年11月

こちらは原書です。発行は2012年1月でした。
『物理学における私の研究テーマのいくつかは、「量子コンピューター」の理論に関するものだ。量子コンピューターでは情報を伝える変数があの手この手で守られ、周囲ともつれを起こさないようになっている。そうすることで、情報の流れを単一の歴史に限定しない新たな計算モードが実現されている。あるタイプの量子計算では、同時に行われる膨大な数の異なる計算が互いに影響を及ぼし合い、ひいては一つの計算の結果に寄与する。このことは「量子並列性」と呼ばれている。
一般に、量子計算では情報の個々のビットを「キュービット(量子ビット)」と呼ばれる物理的物体で表す。キュービットを物理的に実現する方法はいくつもあるが、二つの不可欠な特徴をかならず備えている。一つは、個々のキュービットに離散的な二つの値のどちらかをとれる変数があること、もう一つは、キュービットをもつれから保護する特殊な措置―キュービットを絶対零度近くまで冷やすなど―が講じられていることだ。量子並列性を用いる典型的なアルゴリズムではまず、キュービットのいくつかで、情報を伝達する変数に両方の値を同時に獲得させる。ここで、キュービットをまとめて(たとえば)数を表す一時記憶(レジスター)と見なせば、レジスターとしてのさまざまな実在の数は、キュービット数の二乗という指数関数的な大きさになる。そして、一時的に古典的な計算が行われ、そのあいだに分化の波がほかのキュービットのいくつかへと広がる―だが、それ以上は広がらない。そうならないような措置が講じられているからだ。ゆえに、情報は膨大な数の自律的な歴史それぞれのなかで別個に処理される。最後に、影響を受けるすべてのキュービットが絡む干渉プロセスによって、数々の歴史に含まれる情報が単一の歴史にまとまる。中間段階の計算が存在し、情報はそこで計算されているため、先ほど議論した単純な干渉実験[多宇宙における情報の流れに関するもの]の場合とは違って、最終状態は初期状態と同じではなく、図13に示すように初期状態の関数となる。
画像出展:「無限の始まり」
宇宙船の乗組員は自分のドッペルゲンガー[分身]と情報を共有し、一つの関数を異なる入力に対して計算することによって大量の計算をやってのけたが、量子並列性を利用するアルゴリズムでもまさに同じことをする。だが、先ほどの架空の計算は、プロットに合わせていろいろ創作できる宇宙船の規則の制約しか受けなかったのに対し、量子コンピューターは量子干渉をつかさどる物理法則の制約を受ける。多宇宙の助けを借りて実行できるのは、決まったタイプの量子計算しかない。そしてそのタイプでは、最終結果に必要な情報を単一の歴史にまとめるうえで、たまたま量子干渉の数字が最適なのである。
この手法による計算では、わずか数百キュービットの量子コンピューターでも、観測可能な宇宙に存在する原子よりはるかに多い数の計算を並列に実行できる。本書の執筆時点[2011年頃]で製作されている量子コンピューターのキュービット数は10だ。この数の「拡張」は量子テクノロジーにとってたいへん難関だが、徐々に実現しつつある。』
ご参考:”量研(QST)における量子生命科学研究”
上記をクリック頂くと、量子科学技術開発機構さまの資料(PDF19枚)がダウンロードされます。図、写真、表などが多く含まれた親切な資料です。
付記:”量子技術にまい進する中国--第14次5カ年計画にみるその野望”
こちらは、2021年3月30日付のZDJapanさまの記事です。
『~中国はその中でも量子コミュニケーションに対する果敢な取り組みを続けており、さらなる加速に向かってまい進している。中国はその計画の目標の1つとして、古典的な通信テクノロジーに匹敵する長距離高速量子通信システムの開発を挙げている。~』
付記:”IBMが量子コンピューター分野の開発者認定資格をスタート--その背景と意義”
こちらは、2021年4月15日付のZDJapanさまの記事です。
『~この認定資格は、IBMの量子コンピューティング用ソフトウェア開発キット(SDK)である「Qiskit」を利用することにフォーカスしたものだ。QiskitはPythonスクリプトをベースとするオープンソースプラットフォームで、これを利用すれば、量子アルゴリズムの実験から、クラウドベースの量子デバイスでのコードの実行まで、量子コンピューターを使ったさまざまな実験を行うことができる。~』
付記:”グーグル、新たな量子コンピューター研究拠点「Quantum AI」キャンパス披露”
こちらは、2021年5月19日付のZDJapanさまの記事です。
『~Googleが新たに大規模な量子コンピューティング研究センターを開設したことを明らかにした。カリフォルニア州サンタバーバラにあり、数百人のスタッフを雇用する予定だ。このキャンパスには、Googleの最初の量子データセンター、量子ハードウェア研究ラボ、量子プロセッサーチップファブリケーション施設がある。すでに一部の研究者やエンジニアが働いているという。~』
付記:”NVIDIA、日本の量子研究向け ABCI-Q スーパーコンピューターを支援”
こちらは、2024年3月19日付のPRTIMESさまの記事です。
『~産業技術総合研究所 量⼦・AI融合技術ビジネス開発グローバル研究センター 副センター長の堀部雅弘氏は次のように話しています。「ABCI-Q を通じて、日本の研究者は量子コンピューティングについてより深く知り、実用的なアプリケーションのテストおよび開発を加速できるようになるでしょう。NVIDIA CUDA-Q プラットフォームと NVIDIA H100 により、量子コンピューティング研究の新たなフロンティアを探求する科学者を支援します」~』
付記:”NVIDIA、高速化された量子古典コンピューティングのための 新システムを発表”
こちらは、2024年3月21日付のNVIDIA社からの発表です。
『~世界初の GPU アクセラレーテッド量子コンピューティング システムである NVIDIA DGX Quantum は、世界で最も強力なアクセラレーテッド コンピューティング プラットフォーム (NVIDIA Grace Hopper Superchip とCUDA Quantumオープンソース プログラミング モデルによって実現) と、世界で最も先進的な量子制御プラットフォームである Quantum MachinesによるOPX を組み合わせたものです。~』
付記:”Google が新しい量子チップ、エラー訂正のブレークスルー、ロードマップの詳細を発表” こちらは、2024年12月9日付のHPCwireさまの記事です。
『Google は本日、最新の量子チップである Willow (約 100 量子ビット) を発表しました。これは、この新しいチップで達成された 2 つの重要な成果と一致しています。それは、いわゆる量子エラー訂正しきい値の突破と、従来のコンピューティングに対する量子パフォーマンスの新しいベンチマークの記録です。Willow は、数週間前まで世界最速のスーパーコンピューターであった Frontier では10 兆年 (10 24 ) かかると Google が述べたベンチマークタスクを 5 分で実行しました。~』

スマート・クリエイティブ
今回のブログは“Google”に関するものです。「なぜ、Googleに興味をもったのか?」、かなり長い前置きになりますがお付き合いください。
ほとんど関心のなかった自動運転ですが、たまたま入ってきた情報に反応してしまいました。それはグーグルが自動運転で他社を圧倒しているというものです。てっきり、今も五十歩百歩、横一線なのではないかと思っていたため、このニュースに意表を突かれた感じです。
検索してみると、素晴らしいサイトがありました。以下はそのサイトにあった2019年4月1日付の記事です。動画もあり、非常に詳しい紹介がされています。

画像出展:「NEWS CARAVAN」
Google傘下のWaymo、商用自動運転車を目指した10年の軌跡。
『2018年に初めて自動運転を使った配車サービスを商用展開したのがWaymoです。Googleの親会社のアルファベットの傘下でWaymoは、前身のGoogle自動運転プロジェクトから10年もの歳月をかけてようやく、その技術を実用化させつつあります。』
以下のグラフはワシントンポストのニュースにあったものです。“Rates of intervention”という見出しなので、自動運転技術の性能に関するものということだと思います。これを見るとGoogle は競合他社より2桁~3桁、精度が高そうです。

画像出展:「ワシントンポスト」
上記のグラフではTeslaが0になっていますが、下のグラフの補足を見ると、Teslaは公道での実験データを公表していないようです。また、公道でのテストデータに関してもGoogle の実績(距離)は他社を圧倒しています。
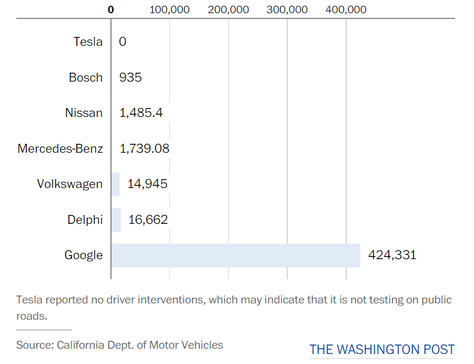
画像出展:「OFFICE31051」
ところで、ご紹介した“NEWS CARAVAN”は、“世界中の最新のテクノロジーを扱ったニュースを配信するサイトです”とのことです。その内容は、FAANG(Facebook、Apple、Amazon、Netflix、Googleの頭文字)、AI、Maas/自動運転、サブスクリプションビジネス、IoT、ブロックチェーン・仮想通貨、フィンテック(Finance+Technology)、クラウド、フードテック(Food+Technology)、宇宙開発 の情報を扱っています。素晴らしい完成度です。
そういえば、Googleは量子コンピュータでもIBMと競っていたのを思い出しました。ということで、こちらも検索してみると驚きのニュースが見つかりました。

画像出展:「CNET Japan」
グーグルの「量子超越性」は革命の始まりにすぎない
『1981年に有名な物理学者、故Richard Feynman氏が言及し、Googleが13年間取り組んできた量子コンピューティングというアイデアが、現実に向かって動き出しているのである。』
下の記事はNewsweekのものです。

画像出展:「Newsweek」
『グーグルの研究チームは、同社の量子コンピューターが、従来のスーパーコンピューター(スパコン)で約1万年かかる計算を「わずか数分」で解いたと発表した。』
『量子コンピューターは、量子力学の奇妙な原理を利用して計算を行う。従来型のコンピューターは「ビット」という情報単位を使っている。これは「0」か「1」のどちらかの状態しか表すことができないのに対し、量子コンピューターが使う情報単位「量子ビット」は、同時に「0」でも「1」でもあって、「0」と「1」の間のすべての値でもある。扱える情報量が大幅に増えるため、演算能力も大幅に高まるのだ。』
こちらの記事の中には英語ですが、コインの表裏を例にした説明動画があります。これは量子力学の奇妙な原理の一つ、「重ね合わせ」を説明するものです。
偉そうに説明できるような知識は持っていないのですが、過去ブログの“量子論1”に戻って少しご説明します。なお、ここでご紹介している内容および画像は、「13歳からの量子論のきほん」という本からです。

出版:ニュートンプレス
発行:2018年7月
量子論が生まれた理由
『あらゆる物質は、「原子」からできていることがわかっています。19世紀末ごろになって、原子がかかわる現象を詳しく調べてみると、ミクロな世界は私たちが日常生活で目にする世界とはまったくちがうことがわかってきました。ミクロの世界は私たちが日常生活で目にする世界とはまったくちがうことがわかってきました。ミクロな物質は、私たちの常識では説明できない、摩訶不思議なふるまいをするのです。
そこで、新しい理論が必要になりました。それが「量子論」です。量子論とは「非常に小さなミクロな世界で、物質を構成する粒子や光などがどのようにふるまうかを解き明かす理論」といえます。』
量子論と日常生活の関係
『マクロな世界の物体の運動に量子論を適用すると、計算量が膨大になってしまいます。そこで実用上は、計算が楽な古典論が使われます。マクロな世界では、量子論による計算結果と古典論による計算結果が、ほとんど同じになるのです。なおマクロな世界にも、量子論を使わないと説明できない現象はあります。「金属(導体)」「絶縁体」「半導体」の性質のちがいや、「超流動」や「超電導」といった現象です。』


量子論の二つの重要事項
●波と粒子の二面性:“電子や光は、波と粒子の性質をあわせもつ”
●状態の共存(重ね合わせ):“一つの電子は、箱の左右に同時に存在できる”
Newsweekの記事にあったコインの動画は、上記の「状態の共存(重ね合わせ)」を説明したものということになります。
以前、ネットで見つけた例えでは次のようなものもありました。
「道を歩いていたら、道が3つに分かれた。1番早く目的地に着ける道を選びたいが、選べるのは1つしかない。従って、結果的に1番早い道を選べる確率は1/3(約33.33%)である。
一方、量子の世界では、【重ね合わせ】という奇妙な原理のお陰で3つの道を同時に歩いて行ける。よって、1番早い道を選べる確率は100%である」。
「Google 恐るべし!!」
そこで、Google がどんな会社か知りたいと思い、“How Google Works(私たちの働き方とマネジメント)”という本を購入したという経緯です。
ブログは目次に続き、共同創業者であるラリー・ペイジの言葉と本書の骨子的なメッセージをお伝えし、続いてGoogle のDNAではないかと思われる“スマート・クリエイティブ”と“ラーニング・アニマル”、そして、イノベーションという章の中のテーマから、“自らとりまく環境を理解する”と“良い失敗をする”をご紹介します。

著者:エリック・シュミット、ジョナサン・ローゼンバーグ、アラン・イーグル
出版:日本経済新聞出版社
発行:2014年10月
目次は大見出しのみご紹介させて頂きます。
序文
はじめに
文化 自分たちのスローガンを信じる
戦略 あなたの計画は間違っている
人材 採用は一番大切な仕事
意思決定 「コンセンサス」の本当の意味
コミュニケーション とびきり高性能のルータになれ
イノベーション 原始スープを生み出せ
おわりに
序文
『グーグルは「自律的思考」をあらゆる活動の基礎にしていた。それはぼくらの誇るすばらしい成功、そしてときにはとんでもない失敗の原動力となった。』 グーグルCEO兼共同創業者 ラリー・ペイジ
はじめに
楽しいプロジェクト
『本書は成功・成長している企業やベンチャーの発達過程をたどるような構成になっている。この発達過程は、雪玉が坂道を転がっていくうちに勢いがつき、どんどん大きくなっていくような、永続的な好環境に発展できるものだ。一連のステップは、スマート・クリエイティブを惹きつけ、意欲を高めるために企業が実践可能なものだ。その一つひとつが企業を次のステップへと押し上げていく。各ステップは相互に依存し、お互いの上に成り立っている。またどのステップも決して終わることのない、ダイナミックなものだ。
まずは最高のスマート・クリエイティブを惹きつける方法から始める。その出発点は企業文化だ。なぜなら企業文化とビジネスの成功は切り離して考えることはできないからだ。自分たちのモットーを信じられなければ、大成功はとうてい望めない。次に取り上げるのが戦略だ。スマート・クリエイティブは強固な戦略の土台に根差したアイデアに何より魅力を感じる。事業計画を支える戦略の柱こそが、事業計画そのものよりもはるかに重要だとよくわかっている。その次が採用だ。これはリーダーの最も大切な仕事である。最高の人材を十分に集めることができれば、知性と知性が混じり合い、クリエイティビティと成功が生まれるのは確実だ。』
スマート・クリエイティブ
・こんにちの労働環境は、20世紀とは本質的に異なる。実験のコストは安くなり、失敗のコストもかつてよりは大幅に低くなった。そのうえ、データもコンピューティングのリソースも豊富になり、自由に使えるようになった。部署を越え、大陸や海を越えての協業も簡単にできる。こうした要素が組み合わさった結果、突如としてひとりのプレイヤー、マネジャー、経営者にいたるまで、働く人間がとほうもないインパクトを生み出せるようになった。
・IBM、ゼネラル・エレクトリック(GE)、ゼネラル・モーターズ(GM)、ジョンソン・エンド・ジョンソンなどの優れた企業は、有望な人材に2~3年ずつさまざまな部署を経験させる経営幹部養成トラックを設けている。だがこの仕組みは専門能力ではなく、経営能力を高めることを目的としている。この結果、従来型企業で働く知識労働者のほとんどは、専門分野に秀でているか、幅広い経営能力を備えているか、どちらかの能力に片寄っているのが普通である。
・従来型の知識労働者と、グーグルのエンジニアを比べてみると、まったく違うタイプであることがわかる。グーグルの社員は会社の情報やコンピューティング能力に自由にアクセスできる。リスクテイクをいとわず、またそうしたリスクをともなう取り組みが失敗したとしても処罰や不利益を受けることはない。職務や組織構造に束縛されることなく、むしろ自分のアイデアを実行に移すよう奨励されている。納得できないことがあれば、黙ってはいない。退屈しやすく、しょっちゅう職務を変える。多才で、専門性とビジネススキルと創造性を併せ持っている。私たちが「スマート・クリエイティブ」と呼ぶ新種で、インターネットの世紀での成功のカギを握る存在である。
・こんにち成功している企業の際立った特色は、最高のプロダクトを生み出しつづける能力である。それを手に入れる道は、「スマート・クリエイティブ」を惹きつけ、彼らがとてつもない偉業を成し遂げられるような環境をつくりだすことである。
・スマート・クリエイティブは、自分の“商売道具”を使いこなすための高度な専門知識を持っており、経験値も高い。
・スマート・クリエイティブは、実行力に優れ、単にコンセプトを考えるだけでなく、プロトタイプをつくる人間である。
・スマート・クリエイティブは、分析力も優れている。データを扱うのが得意で、それを意思決定に生かすことができる。同時にデータの弱点もわかっており、いつまでも分析を続けようとはしない。データに判断させるのは構わないが、それに振り回されるのはやめようと考える。
・スマート・クリエイティブは、ビジネス感覚も優れている。専門知識をプロダクトの優位性や事業の成功と結びつけて考えることができ、そのすべてが重要であることをわかっている。競争心も旺盛である。成功にはイノベーションが不可欠だが、猛烈な努力も欠かせない。
・スマート・クリエイティブは、頂点を目指す意欲にあふれ、ユーザのこともよくわかっている。どんな業界に身を置いているかにかかわらず、スマート・クリエイティブはプロダクトを誰よりもユーザ目線、あるいは消費者の視点から見ることができる。自らが「パワー・ユーザ」で興味の対象に取りつかれたようにのめり込む。
・スマート・クリエイティブからは、斬新なアイデアがほとばしり出る。他の人とはまったく違う視点があり、ときには本来の自分とも違う視点に立つ。必要に応じて、カメレオン的に視点を使い分けることができる。
・スマート・クリエイティブは、好奇心旺盛である。常に疑問を抱き、決して現状に満足せず、常に問題を見つけて解決しようとし、それができるのは自分しかいないと確信している。傲慢に見えることもあるかもしれない。
・スマート・クリエイティブは、リスクをいとわない。失敗を恐れない。失敗からは常に大切なことを学べると信じているからである。あるいはとほうもない自信家で、たとえ失敗しても、絶対に立ち直り、次は成功できると思っている。
・スマート・クリエイティブは、自発的である。指示を与えられるのを待つのではなく、また納得できない指示を与えられたら無視することもある。自らの主体性にもとづいて行動するが、その主体性自体が並みの強さではない。
・スマート・クリエイティブは、あらゆる可能性にオープンである。自由に他社と協力し、アイデアや分析をそれ自体の本質にもとづいて評価する。
・スマート・クリエイティブは、細かい点まで注意が行き届く。集中力を切らさず、どんな細かいことも覚えている。それは勉強し、記憶するからではない。それが自分にとって重要だから、すべて知り尽くしている。
・スマート・クリエイティブは、コミュニケーションも得意である。一対一でも集団の前で話すときも、話がおもしろく、センスがよくてカリスマ性さえ感じさせる。
・『すべてのスマート・クリエイティブがこうした特徴を全部備えているわけではないし、実際そんな人間は数えるほどしかいない。だが全員に共通するのは、ビジネスセンス、専門知識、クリエイティブなエネルギー、自分で手を動かして業務を遂行しようとする姿勢だ。これが基本的要件だ。』
・スマート・クリエイティブはどこにでもいる。社会階層や年齢、性別も関係ない。テクノロジーのもたらすツールを使って価値あることをしたいという、意欲と能力のある、あらゆる世代の志の高い人たちである。その共通点は努力をいとわず、これまでの常識的方法に疑問を持ち、新しいやり方を試すことに積極的であることである。スマート・クリエイティブが大きな影響を持ちうるのはこうした理由からである。

画像出展:「Google・シュミット会長による働き方とマネジメントを示すスライドが公開中」
『彼らはテクノロジーの知識やビジネス能力、そして創造力を組み合わせることができ、最新のツールと自由な環境を与えてやると驚くべき製品を驚くべきスピードで生みだすことができる人たちです。』
人材
ラーニング・アニマルを採用する
・『あなたの会社の従業員について考えてみよう。自分より優秀だと心から思えるのは誰か。チェスやクロスワードで対戦したくない相手は? 自分より優秀な人間を採用せよ、という格言があるが、どれだけ実行できているだろう。
この格言はいまも妥当性を失っていないが、その意味は考えられている以上に深い。もちろん優秀な人はいろいろなことを知っていて、凡庸な人より高い成果をあげる。ただ、大切なのは優秀な人が「何を知っているか」ではなく、「これから何を学ぶか」だ。』
・『ヘンリー・フォードは「人は学習を辞めたときに老いる。20歳の老人もいれば、80歳の若者もいる。学びつづける者は若さを失わない。人生で何よりすばらしいのは、自分の心の若さを保つことだ」と言った。グーグルが採用したいのは、ジェットコースターを選ぶタイプ、つまり学習を続ける人々だ。彼ら“ラーニング・アニマル”は大きな変化に立ち向かい、それを楽しむ力を持っている。』
・心理学者のキャロル・ドゥエックは、これ[ラーニング・アニマル]を別の言葉で表現する。それは「しなやかマインドセット」である。
・しなやかマインドセットの持ち主は、努力すれば自分の持ち味とする能力を変えたり、新たな能力を開花させることができると考える。人は変われる。適応できる。むしろ変化を強いられると、心地よく感じ、より高い成果をあげられる。
・しなやかマインドセットの持ち主は「学習目標」を設定する。学ぶこと自体が目標になると、くだらない質問をしたり、答えを間違えたりしたら自分がバカに見えるのではないかなどと悩んだりせず、リスクをとるようになる。ラーニング・アニマルが目先の失敗にこだわらないのは、長い目でみればそのほうが多くを学び、さらなる高みに上がれることを知っているからだ。
・知力より専門能力を重視するのは、とくにハイテク業界では間違いである。あらゆる業界では急速な変化が起きており、昨日までの先端的プロダクトが明日には陳腐化するような時代に、スペシャリスト採用にこだわると裏目に出る可能性が高い。スペシャリストが問題を解決するとき、その手法には自分の強みとされる専門分野ならではの偏りが生じがちだ。優秀なゼネラリストには偏りがなく、多様なソリューションを見比べて最も有効なものを選択することができる。
イノベーション
自らとりまく環境を理解する
・『グーグルXチームは新しいプロジェクトに取り組むかどうか決めるとき、ベン図を使う。まず、それが対象としているのは、数百万人、数十億人に影響をおよぼすような大きな問題あるいはチャンスだろうか。第二に、すでに市場に存在するものとは根本的に異なる解決策のアイデアはあるのか。グーグルは既存のやり方を改善するのではなく、まったく新しい解決策を生み出したいと考えている。そして第三に、根本的なる解決策を世に送り出すための画期的な技術は(完全な姿ではなく、部分的なかたちでも)すでに存在しているのか、あるいは実現可能なのか。』
・「プロジェクト・ルーン」とは、インターネットへのブロードバンド接続環境のない数十億人に、ヘリウム気球を使ってそれを提供しようというプロジェクトだが、これは先に挙げた三つの条件をすべて満たしている。すでに存在する、あるいは十分実現可能な技術を使って、とほうもなく大きな問題をこれまでとは劇的に違うやり方で解決しようとするものである。グーグルXチームはまず新たなプロジェクトのアイデアが三つのパラダイムをすべて満たすか確かめ、満たさないものは却下する。
・イノベーションが生まれるには、イノベーションにふさわしい環境が必要である。イノベーションにふさわしい環境とは、急速に成長しており、たくさんの競合企業がひしめく市場である。
・まったく新しい、ライバルがやってこない“未開の地”は、企業の成長を維持するだけの規模がない。イノベーションのための環境を望むなら、成長の余地の大きな巨大市場を探したほうが良い。
・技術は検討すべき要素である。その分野の技術はどのように進化していくか。現在との違いは何か、そして他にはどんな違いが生まれるか。その進化する環境のなかで、持続的に他社との明確な違いを出していくための人材はそろっているか。これらもイノベーションの環境にとって大切である。

こちらが、ベン図です。
「できるネット」さまより拝借しました。
良い失敗をする
『「世に出してから手直しする」アプローチの成功例がグーグル・クロームだとすれば、代表的な失敗例は2009年に華々しく登場したグーグル・ウェーブである。』
・ウェーブは大失敗だった。しかし、失敗が明らかになってから追加投資をしなかった。また失敗によって敗者の烙印を押された社員はいなかった。ウェーブ・チームメンバーはプロジェクトの打ち切り後、社内でひっぱりだこになった。限界に挑戦するようなプロジェクトに取り組んだからである。
・ウェーブは失敗する過程で、たくさんの貴重な技術を生み出した。ウェーブのプラットフォームの技術はグーグル・プラスやGメールに取り入れられている。失敗ではあったが、ウェーブは“良い失敗”だった。
・イノベーションを生み出すには、良い失敗のしかたを身に着ける。どんな失敗プロジェクトからも、次の試みに役立つような貴重な技術、ユーザ、市場の理解が得られるものである。アイデアは潰すのではなく、形を変えることを考える。
・世界的イノベーションの多くは、まったく用途の異なるものから生まれている。だからプロジェクトを終了するときには、その構成要素を慎重に吟味し、他の何かに応用できないか見きわめる必要がある。
・『ラリーがよく言うように、とびきり大きな発想をしていれば、完全な失敗に終わることはまずない。たいてい何かしら貴重なものが残るはずだ。そして失敗したチームを非難してはいけない。メンバーが社内で良い仕事に就けるようにしよう。他のイノベーターも、彼らが制裁を受けるかどうか注目している。失敗を祝福する必要はないが、ある種の名誉の印と言っていいだろう。少なくとも挑戦したのだから。』
・経営者の仕事は、リスクを最低限に抑えたり、失敗を防いだりすることではない。リスクをとり、避けられない失敗に耐えられるだけの強靭な組織をつくることである。
・おそらく最も難しいのは、失敗のタイミングを見きわめることである。良い失敗は決断が早い。プロジェクトが成功しないと判断したら、リソースのさらなる浪費や機会損失を避けるため、なるべく早く手を引くべきである。ただし、イノベーティブな会社の顕著な特徴は、優れたアイデアに成熟する時間をたっぷり与えることである。自動運転車やグーグル・ファイバー(家庭で最大1ギガビットのブロードバンド接続を可能にする。現在のアメリカの平均的な家庭用回線のおよそ100倍に相当)のようなプロジェクトは、莫大な収益をもたらす可能性があるが、おそろしく時間がかかる。
・『ジェフ・ベゾスもこう言っている。「時間軸を伸ばすだけで、それまで考えもしなかったようなプロジェクトに取り組めるようになる。アマゾンではアイデアを5年~7年で実現したいと考えている。ぼくらは積極的にタネをまき、育てようとするし、しかもとびきり頑固だ。ビジョンについては頑固に、細部については柔軟に、が合言葉さ」 』
・失敗はすばやく、ただし時間軸はとびきり長く、ということである。そのために大切なことは、手直しをできるかぎり速くすること、そして手直しするたびに、自分が成功に近づいているか判断する基準をつくっておくことである。小さな失敗は当然起こるだろうし、許容すべきである。それが進むべき正しい道を示してくれることもある。
・失敗が積み重なり、どうにも成功への道筋が見えないときは、おそらく潮時と考えた方が良い。
相田みつを先生の『にんげんだもの』より

”ラーニング・アニマル”と聞いて、こちらの書を思い出しました。
追記:2024年12月12日

画像出展:「IoT World Today」
『サンフランシスコの計画に関するニュースは、今年初めにカリフォルニア州公益事業委員会がウェイモのサービス範囲を州全体に拡大し、高速道路で最高時速65マイルでの運行を許可する決定を下したことを受けて発表された。
これにより、ウェイモは高速道路での無人運転サービスに対して最終的に料金を請求できるようになる。そして、テストの最新段階はその目標に向けた次のステップとなる。
これはまた、Waymo が戦略的展開を着実に進めていることを反映している。同社はつい先週、ベイエリア (およびロサンゼルス郡) で Waymo One 配車サービスの運用区域を拡大する予定であると発表したばかりだ。』
追記:2025年4月12日


画像出展:「electrek」 ※写真は動画から
『本日より、テキサス州オースティンのお客様限定で、完全自動運転のWaymo One配車サービスがUberアプリを通じてご利用いただけます。本日の発表は、WaymoとUberの既存のパートナーシップに基づくものであり、このロボタクシースタートアップが米国各地の新たな都市へ進出していく上で重要な節目となります。』
追記:2025年7月9日

画像出展:「PCMAG」
『プログラムが有効化されると、お子様は独立して自動運転車両を呼び出し、フェニックス都市圏の315平方マイルを走行できるようになります。フェニックス都市圏はWaymoが初めて導入された都市です。』
※画像をクリックすると、“Waymoのティーンアカウント”に移動します。
ブロックチェーン
ビットコインなる仮想通貨には全く興味はなかったのですが、そのビットコインの仕組みに使われている“ブロックチェーン”というテクノロジーは、画期的なものらしいということ知りました。「インターネット以来の最大の発明だ」という人までいるようです。
約29年勤めていた会社はHP(ヒューレット・パッカード)というIT企業です。もっぱら営業担当だったため、技術そのものにはほとんど興味はありませんが、IT業界の動向については今も関心があります(実は、これにはIT企業の株式を少々保有しているという裏事情もあります)。
そこで、このような新しいビジネスチャンスに対し、明確な戦略メッセージを周知徹底されるIBM社のホームページをのぞいてみることにしました。そして、この“ブロックチェーン”が極めて有望なものであるということを理解しました。これは“中抜き”によるコストと時間と多様性に対するビジネスチャンスということだと思います。
知りたいことは、「ブロックチェーンの何が優れているのか」と「どんなビジネス機会が想定されるのか(実現可能性)」の2つです。
思っていたとおり、数多くの本が出版されていたのですが、この本は著者の中島先生が中央銀行である日本銀行に長く勤務され、特に「決済システム」にも関わっていたという点に惹かれました。発行が2017年10月と他の本に比べるとそれ程新しくないためか、中古本価格が安かったのも助かりました。

著者:中島真志
出版:新潮社
発行:2017年10月
大きな目次は以下の通りです。
序章 生き残る次世代通貨は何か
第1章 謎だらけの仮想通貨
第2章 仮想通貨に未来はあるのか
第3章 ブロックチェーンこそ次世代のコア技術
第4章 通貨の電子化は歴史の必然
第5章 中央銀行がデジタル通貨を発行する日
第6章 ブロックチェーンによる国際送金革命
第7章 有望視される証券決済へのブロックチェーンの応用
「はじめに」の後半に、著書である中島先生の経歴のお話が出ていますので、最初にそれをご紹介します。
『著者は、長らく日本銀行に勤務し、リサーチ関連の仕事を多く経験しました。その中で「決済システム」に出会い、大学教授への転身後もライフワークとして調査研究を続けてきています。日本銀行時代には、金融研究所で「電子現金」の研究に携わり(詳しくは本論でどうぞ)、国際決済銀行(BIS)に出向の際は、決済に関するグローバルなルール作りに携わりました。この間、資金決済、証券決済、外為決済、SWIFTなどについての著書を刊行し、いずれも金融関係者に広く読んで頂いています。こういった経歴から、わが国における決済分野の有識者の一人として、金融庁の審議会や全銀ネットの有識者会合などにも数多く参加してきました。』
ブログは「第3章 ブロックチェーンこそ次世代のコア技術」からになりますが、その第3章の中にある、“③ブロックチェーンが主役の世界へ” の説明に使われている図を見て、今後の目指す方向性が見えました。

画像出展:「アフター・ビットコイン」
以下は図の説明です。
『ビットコインなどの仮想通貨が、従来の金融の本流から少し離れた、いわば周辺部分におけるイノベーションであるのに対して、ブロックチェーンは、金融の中核を成すメインストリームの業務のあり方を大きく変えようとしているのです。
ここに来て金融業界では、「ブロックチェーンが主役になる」という認識が共有されつつあり、この技術をどの分野に応用していくかが中心的な課題となっているのです。ビットコインは、あくまでもブロックチェーンの最初の実用例であって、また特殊な適用例の一つにすぎないとの見方に変わってきています。すなわち、「ビットコイン中心の世界」から、「ブロックチェーンが主役の世界」へ移行してきており、当初のビットコインの導入段階からは、主客が完全に逆転しているのです。
ブロックチェーンの応用分野は、幅広い分野が想定されており、このうち、①仮想通貨に応用する場合を「ブロックチェーン1.0」、②金融分野(仮想通貨以外)に応用する場合を「ブロックチェーン2.0」、③土地登記、資産管理、商流管理、医療情報、選挙の投票管理などの非金属分野に応用する場合を「ブロックチェーン3.0」として分類するようになっています(図表3-1)。』
次も第3章からになります。ポイントと感じた部分を書き出しました。
1.ブロックチェーンとは
●ビットコインを支える中核技術として開発され、“オリジナル・ブロックチェーン”と呼ばれている。
●新たな進化系のブロックチェーンを総称して“ブロックチェーン技術”と呼んでいる。
●データベースを保管するデータベースの技術である。
●“ブロック”と呼ばれる取引データの固まり一定時間ごとに生成し、時系列的に鎖のようにつなげていく。
●過去の取引データを改ざんするためには、過去から最新のブロックまでをすべて改ざんする必要があり、二重使用や偽造などの不正取引を防止できる。

画像出展:「経済産業省」
2.分散型台帳技術(DLT:Distributed Ledger Techonology)とは
“分散型台帳技術(DLT)に関して、中島先生は次のように補足されています。
『IT技術者以外の一般の方にとっては、そこまで[ブロックチェーンとDLTを]厳密に区別する必要は必ずしもなく、ブロックチェーンと分散型台帳管理(DLT)とはほぼ同義のものと捉えておけばよいでしょう。ブロックチェーンとDLTとは、「同じ技術を別の側面から呼んだもの」と考えておけばよいものと思います。』
●「ブロックを鎖状につなげて管理する」という技術面より「所有権データを分散型で管理する」というユーザ側の視点の方が金融業界では親しみやすく、その結果、金融業界では“分散型台帳技術(DLT)”という用語が前に出てきている。
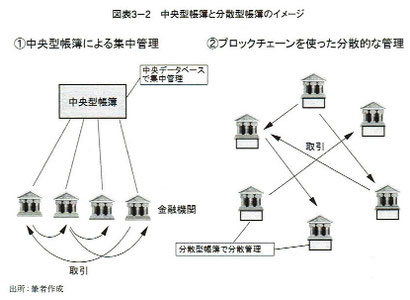
画像出展:「アフター・ビットコイン」
3.ブロックチェーン/分散型台帳技術の特性
1)改ざん耐性(改ざんが困難であること)
●改ざんするためには、現在までのすべてのブロックを作り直す必要があり、かつその作り直しを正規のチェーンよりも早く成立させなければならない。これは事実上不可能である。(この重要なメカニズムは“ハッシュ値”というものに因る)
2)高可用性(低障害であること)
●ネットワーク上のコンピュータが同じデータを持ち合い、分散してデータを管理している。
●ネットワーク上のコンピュータが1台でも稼働していれば全体としてのシステムを維持できる。

右側のP2P(Point to Point)型がブロックチェーンの一般的なシステム構成になります。左側はサーバーが故障すると、システム全体が止まります。
画像出展:「アフター・ビットコイン」
3)低コスト(劇的なコスト削減ができること)
●取引や顧客に関する膨大なデータベースの維持、管理などに関わるコストを大幅に削減ができる。
●各金融機関どうしの帳簿の残高照合作業が不要になる。
●ユーザ側においても仲介者が不要になるため、迅速かつ低コストでの取引が可能になる。
4.ブロックチェーンの種類
●ブロックチェーンには誰でも参加できる「オープン型」と特定の参加者のみの「クローズド型」がある。
●「オープン型」は「パブリック型」とも呼ばれている。ビットコインは「オープン型」である。
●「クローズド型」は「プライベート型」や「許可型」とも呼ばれている。
●「クローズド型」は参加を許可する段階で、参加者の身元は明らかになっている(匿名性なし)。
●「クローズド型」には全体を管理・運営する中央の管理主体が存在する。

画像出展:「アフター・ビットコイン」
5.コンセンサス・アルゴリズム
●「コンセンサス・アルゴリズム」とは「合意形成の手法」と言われており、分散したデータベース上に多数存在する台帳情報を、ネットワーク上の全員で共有するための手法である。
●「コンセンサス・アルゴリズム」の方法は、オープン型とクローズ型で異なるが、これはオープン型が「悪意の参加者」の存在を前提にする必要があるのに対し、クローズド型では「許可された参加者」だけが対象になるからである。
●主なコンセンサス・アルゴリズム

表の上から3つ(プルーフ オブ ワーク[PoW]、プルーフ オブ ステーク[PoS]、プルーフ オブ インポータンス[PoI])は悪意のある参加者がいることを前提に、厳格な方式で不正を排除している仕組みになっています。
画像出展:「アフター・ビットコイン」
6.代表的なブロックチェーン
1)リナックスが進める「ハイパーレッジャー・ファブリック」
●「ハイパーレッジャー・ファブリック」は“リナックス・ファウンデーション”が開発しているブロックチェーンであり、金融業界向けのブロックチェーンとしての標準化を志向している。
●独自のコンセンサス・アルゴリズム(PBFT系)やメンバーシップ管理の仕組みを含んでいる。
●金融以外にも、製造、保険、不動産契約、IoT、ライセンス管理、エネルギー取引などでの応用を志向している。
●オープンソース(無償で一般公開)のため、誰でもそのソフトウエアの利用、改良ができる。

こちらは“リナックス・ファウンデーション”のサイトにあるものです。

“Forbes Blockchain 50”の半数がHyperledgerを使っているということが書かれたページです。

こちらはForbesのサイトです。アルファベット順に50社が紹介されています。

こちらは“ブロックチェーンオンライン”さまのハイパーレッジャーに関するご説明です。
『Hyperledgerは、ブロックチェーンの技術を仮想通貨に限らず最大限に利用することを目的として生まれたブロックチェーン技術の推進コミュニティーです。プロジェクトの立ち上げにあたってLinuxOSの普及をサポートする非営利の共同事業体であるLinux Foundationが中心となり、オープンソースの理念から世界中のIT企業が協力して、ブロックチェーン技術の確立を目指しています。』

こちらのブログの中に、少し古いですがLinuxに関する現状が載っていました。一部をご紹介します。これを見るとLinuxはOSS(Open Source Software)のリーダーという感じですね。
●In 2018, Linux ran on 100% of the world’s 500 supercomputers.
●In 2018, Android (based on Linux) dominated the mobile OS market with 75.16%.
●85% of all smartphones run on some version or derivative of Linux.
上記の”WEBSITE PLANET"は”Find a solution for your website”となっており、”Website Builders"もありました。
2)R3コンソーシアムが進める「コルダ」
●R3は米国の技術系企業である。
●金融業界向けに特化した分散型台帳管理技術を開発する。

こちらはコルダのサイトですが、参加企業のロゴが全て掲載されています。数えてみたら178社でした。(2019年5月3日時点)
7.金融分野におけるブロックチェーンの実証実験
1)国際送金における応用
『国際送金は、これまで相手先への着金までに時間がかかることや、手数料が高いといった問題点があったため、ブロックチェーンの技術を使ってこれらを克服し、国際送金を「早く、安く」行おうとする動きがみられます。』

“国際送金システム「SWIFT」がブロックチェーン企業R3と提携 XRP対応の決済アプリ「Corda Settler」統合へ”という2019年1月31日付けのBD by BITDAYSさまの記事です。
なお、SWIFTとは Society for Worldwide Interbank Financial Telecommunicationの略で、国際銀行間通信協会になります。

私自身の話になりますが、HPの営業時代に銀行さまを担当していたことがあり、このSWIFTという用語は国際決済の代名詞のように使われていました。「思い出します。懐かしい」。(日本語サイトです)
2)証券決済における応用
『国際送金と並び、証券決済の分野もブロックチェーンの応用として脚光が当たっています。株式や債券といった証券の決済は、現状では、多くの当事者が関係する複雑なプロセスになっていますが、ブロックチェーンを利用することによって、こうしたプロセスを大幅に合理化し、コストを削減できるのではないかとの機運が盛り上がっています。』
付記1:総務省 自治体ポイントに関する検討会 2018年4月11日 資料3
クリック頂くと、PDFの資料がダウンロードされます。こちらの資料、”ブロックチェーンの将来性と応用分野” は中島先生によるものです。今回ご紹介した『アフター・ビットコイン』がベースになっていますが、書式がスライドタイプなので見やすいと思います。ご参考にして頂ければと思います。
付記2:HPE opens new headquarters in north San Jose
日本では『平成』最後の日となった2019年4月30日に、HPE(旧HPから分社した会社で主に企業むけのシステムやサービスを提供。辞めていなければHPではなく、こちらのHPE側にいたというところです)の新しい本社がオープンしたそうです。グッドタイミングだったので貼りました。

すいません。英語のままです。
Hewlett Packard Enterprise employees gather next to the new HPE headquarters at 6280 America Center in San Jose. Hewlett Packard Enterprise on Tuesday unveiled a gleaming new office building in north San Jose, bringing a world-class tech company's headquarters into the Bay Area's largest city.
画像出展:「mercurynews」

左から2番目がCEOのAntonio Neriです。
Hewlett Packard Enterprises CEO Antonio Neri (L), San Jose City Councilman Lan Diep (C) and San Jose Mayor Sam Liccardo (R), take a selfie with Hewlett Packard Enterprises employees during the grand opening of the new HPE headquarters in north San Jose. Hewlett Packard Enterprises on Tuesday unveiled a gleaming new office building in north San Jose, marking a new tech headquarters for the Bay Area's largest city.

Hewlett Packard Enterprise (NYSE: HPE) said its new headquarters in City Place in the Spring area opened for employees on Feb. 14, and the company plans a grand opening celebration “in a month or two.”
画像出展:「yahoo! finance」
【YHP】
ホームページの「その他」→「参考図書」のページにガレージらしき写真を、何の説明もつけずにポンと置いていますが、それについてお話したいと思います。
この写真のタイトルは「Rules of the Garage」といい、1999年当時、米国ヒューレット・パッカード社(HP社)の新CEOであったカーリー・フィオリナが、創業者のビル・ヒューレットとデイブ・パッカードが築いたHP Wayの精神を再考し、あらためて行動規範としてまとめたものです。
原点であるHP Wayはビル・ヒューレットが語った次の言葉が象徴的であるといわれています。
それは、「信頼と尊厳。社員は男女を問わず誰でも良い仕事、創造的な仕事をしたいと思っている。それに相応しい環境におかれれば、誰でもそうする。会社は本当に社員が働きやすい環境・制度を整備する。社員はそうした会社の姿勢に応えるべく責任と義務を要する。」
というものです。なお、二人が使った創業当時のガレージは米国ITの象徴ともいえる、シリコンバレー発祥の地として「史跡」に指定されています。
HP WayはHP社で働く者にとっては、DNAともいうべき考え方ですが、私が最も印象に残り、判断や行動の拠り所として、心に置いていたのはHP Wayではありません。
それは会社説明会で渡された会社案内のトップページに書かれていた、「One for all, all for one」でした。今でこそ有名ですが、34年前の自分にはとても新鮮で、何故かハッとさせられたという記憶があります。
ラグビーでよく使われる言葉だということを知り、その意味するイメージを深く理解できたと思います。仕事が楽しく、前向きに取り組むことができたのは、この言葉を大切にしてきたからではないかと思っています。
そして、この言葉は入社当時の人事部長で、56歳という若さで他界された木本建治さん、早稲田大学ラグビー部OBで1987年の日本選手権では、監督として社会人の強豪東芝府中を撃破し、大学最後の優勝監督となった木本監督を思い出します。

ずいぶんと日焼けしてしまいましたが、貴重な1冊です。

写真はtownphoto.netさまより拝借。2010年5月撮影のようですが、この「HPストリート」の風景は1980年代当時と変わらないように思います。